 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Dialogue Generation with Diversified Traits
Paper and Code
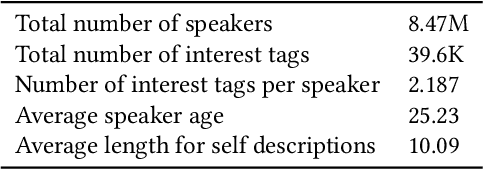
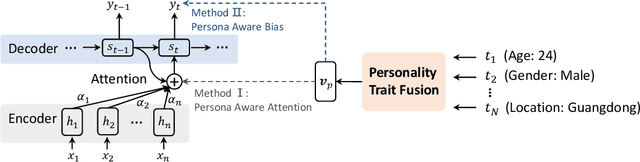

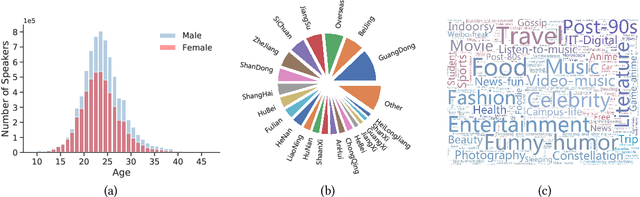
Endowing a dialogue system with particular personality traits is essential to deliver more human-like conversations. However, due to the challenge of embodying personality via language expression and the lack of large-scale persona-labeled dialogue data, this research problem is still far from well-studied. In this paper, we investigate the problem of incorporating explicit personality traits in dialogue generation to deliver personalized dialogues. To this end, firstly, we construct PersonalDialog, a large-scale multi-turn dialogue dataset containing various traits from a large number of speakers. The dataset consists of 20.83M sessions and 56.25M utterances from 8.47M speakers. Each utterance is associated with a speaker who is marked with traits like Age, Gender, Location, Interest Tags, etc. Several anonymization schemes are designed to protect the privacy of each speaker. This large-scale dataset will facilitate not only the study of personalized dialogue generation, but also other researches on sociolinguistics or social science. Secondly, to study how personality traits can be captured and addressed in dialogue generation, we propose persona-aware dialogue generation models within the sequence to sequence learning framework. Explicit personality traits (structured by key-value pairs) are embedded using a trait fusion module. During the decoding process, two techniques, namely persona-aware attention and persona-aware bias, are devised to capture and address trait-related information. Experiments demonstrate that our model is able to address proper traits in different contexts. Case studies also show interesting results for this challenging research problem.