 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Do LLMs Know About Chinese Zero Pronouns?
May 29, 2026Zero Pronouns (ZPs) are a pervasive linguistic phenomenon in pro-drop languages such as Chinese and have long posed a challenge for natural language processing systems. Although Large Language Models (LLMs) perform well on many Chinese language tasks, their ability to process ZPs remains poorly understood. We conduct a systematic investigation of LLMs' handling of Chinese ZPs through a sequence of linguistically motivated tasks, including identification, referentiality classification, referential type classification, resolution, and translation. A diverse set of LLMs is evaluated across all tasks. Our results show that Chinese ZPs remain highly challenging for current LLMs, particularly for upstream tasks such as identification and referentiality classification. Performance on downstream tasks, such as ZP translation, is also consistently low: even state-of-the-art reasoning-oriented LLMs correctly translate fewer than half of Chinese ZPs into English.
When Seekers Are Hard to Help: Evaluating Emotional Support Dialogue Systems in Worst-Case Interactions
May 27, 2026Emotional Support Dialogue Systems (ESDSes) are increasingly evaluated and trained with LLM-simulated seekers. However, such simulated seekers often behave as cooperative, average-case users who disclose clearly, respond constructively, and accept support within a few turns. This can lead to overly optimistic evaluation and obscure whether ESDSes can handle difficult help-seeking interactions. In this work, we study ESDS evaluation under worst-case interactions, where seekers are hard to help due to low engagement, resistance, limited self-disclosure, emotional volatility, or rigid negative interpretations. We first conduct an expert simulation study with eight experienced counselling professionals, who simulate difficult seekers, interact with existing Chinese ESDSes, provide scale ratings, and participate in semi-structured interviews. Based on this study, we derive worst-case seeker behaviours and identify key limitations of current systems. We then propose a worst-case evaluation framework consisting of an LLM-based worst-case seeker simulator and four worst-case-oriented metrics: Deep Emotional Understanding, Guided Exploration, Balanced Emotional Support, and Authentic and Grounded Support. Evaluating 17 systems, we find that nearly all models suffer substantial performance drops under worst-case interactions. Large general-purpose LLMs are generally more robust than specialised ESDSes, but even the strongest models struggle to sustain engagement and improve seekers' emotional states. Finally, we show that worst-case simulation can also generate useful training data, improving the robustness of smaller models.
On the Robustness of Knowledge Editing for Detoxification
Feb 11, 2026Knowledge-Editing-based (KE-based) detoxification has emerged as a promising approach for mitigating harmful behaviours in Large Language Models. Existing evaluations, however, largely rely on automatic toxicity classifiers, implicitly assuming that reduced toxicity scores reflect genuine behavioural suppression. In this work, we propose a robustness-oriented evaluation framework for KE-based detoxification that examines its reliability beyond standard classifier-based metrics along three dimensions: optimisation robustness, compositional robustness, and cross-lingual robustness. We identify pseudo-detoxification as a common failure mode, where apparent toxicity reductions arise from degenerate generation behaviours rather than meaningful suppression of unsafe content. We further show that detoxification effectiveness degrades when multiple unsafe behaviours are edited jointly, and that both monolingual and cross-lingual detoxification remain effective only under specific model-method combinations. Overall, our results indicate that KE-based detoxification is robust only for certain models, limited numbers of detoxification objectives, and a subset of languages.
How Do People Quantify Naturally: Evidence from Mandarin Picture Description
Feb 10, 2026Quantification is a fundamental component of everyday language use, yet little is known about how speakers decide whether and how to quantify in naturalistic production. We investigate quantification in Mandarin Chinese using a picture-based elicited description task in which speakers freely described scenes containing multiple objects, without explicit instructions to count or quantify. Across both spoken and written modalities, we examine three aspects of quantification: whether speakers choose to quantify at all, how precise their quantification is, and which quantificational strategies they adopt. Results show that object numerosity, animacy, and production modality systematically shape quantificational behaviour. In particular, increasing numerosity reduces both the likelihood and the precision of quantification, while animate referents and modality selectively modulate strategy choice. This study demonstrates how quantification can be examined under unconstrained production conditions and provides a naturalistic dataset for further analyses of quantity expression in language production.
Do Large Language Models Judge Error Severity Like Humans?
Jun 05, 2025


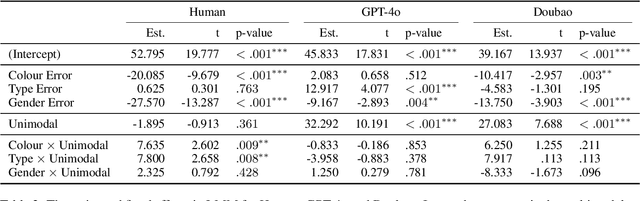
Large Language Models (LLMs) are increasingly used as automated evaluators in natural language generation, yet it remains unclear whether they can accurately replicate human judgments of error severity. In this study, we systematically compare human and LLM assessments of image descriptions containing controlled semantic errors. We extend the experimental framework of van Miltenburg et al. (2020) to both unimodal (text-only) and multimodal (text + image) settings, evaluating four error types: age, gender, clothing type, and clothing colour. Our findings reveal that humans assign varying levels of severity to different error types, with visual context significantly amplifying perceived severity for colour and type errors. Notably, most LLMs assign low scores to gender errors but disproportionately high scores to colour errors, unlike humans, who judge both as highly severe but for different reasons. This suggests that these models may have internalised social norms influencing gender judgments but lack the perceptual grounding to emulate human sensitivity to colour, which is shaped by distinct neural mechanisms. Only one of the evaluated LLMs, Doubao, replicates the human-like ranking of error severity, but it fails to distinguish between error types as clearly as humans. Surprisingly, DeepSeek-V3, a unimodal LLM, achieves the highest alignment with human judgments across both unimodal and multimodal conditions, outperforming even state-of-the-art multimodal models.
Emotional Supporters often Use Multiple Strategies in a Single Turn
May 21, 2025



Emotional Support Conversations (ESC) are crucial for providing empathy, validation, and actionable guidance to individuals in distress. However, existing definitions of the ESC task oversimplify the structure of supportive responses, typically modelling them as single strategy-utterance pairs. Through a detailed corpus analysis of the ESConv dataset, we identify a common yet previously overlooked phenomenon: emotional supporters often employ multiple strategies consecutively within a single turn. We formally redefine the ESC task to account for this, proposing a revised formulation that requires generating the full sequence of strategy-utterance pairs given a dialogue history. To facilitate this refined task, we introduce several modelling approaches, including supervised deep learning models and large language models. Our experiments show that, under this redefined task, state-of-the-art LLMs outperform both supervised models and human supporters. Notably, contrary to some earlier findings, we observe that LLMs frequently ask questions and provide suggestions, demonstrating more holistic support capabilities.
CCNU at SemEval-2025 Task 3: Leveraging Internal and External Knowledge of Large Language Models for Multilingual Hallucination Annotation
May 17, 2025We present the system developed by the Central China Normal University (CCNU) team for the Mu-SHROOM shared task, which focuses on identifying hallucinations in question-answering systems across 14 different languages. Our approach leverages multiple Large Language Models (LLMs) with distinct areas of expertise, employing them in parallel to annotate hallucinations, effectively simulating a crowdsourcing annotation process. Furthermore, each LLM-based annotator integrates both internal and external knowledge related to the input during the annotation process. Using the open-source LLM DeepSeek-V3, our system achieves the top ranking (\#1) for Hindi data and secures a Top-5 position in seven other languages. In this paper, we also discuss unsuccessful approaches explored during our development process and share key insights gained from participating in this shared task.
A computational transition for detecting correlated stochastic block models by low-degree polynomials
Sep 02, 2024Detection of correlation in a pair of random graphs is a fundamental statistical and computational problem that has been extensively studied in recent years. In this work, we consider a pair of correlated (sparse) stochastic block models $\mathcal{S}(n,\tfrac{\lambda}{n};k,\epsilon;s)$ that are subsampled from a common parent stochastic block model $\mathcal S(n,\tfrac{\lambda}{n};k,\epsilon)$ with $k=O(1)$ symmetric communities, average degree $\lambda=O(1)$, divergence parameter $\epsilon$, and subsampling probability $s$. For the detection problem of distinguishing this model from a pair of independent Erd\H{o}s-R\'enyi graphs with the same edge density $\mathcal{G}(n,\tfrac{\lambda s}{n})$, we focus on tests based on \emph{low-degree polynomials} of the entries of the adjacency matrices, and we determine the threshold that separates the easy and hard regimes. More precisely, we show that this class of tests can distinguish these two models if and only if $s> \min \{ \sqrt{\alpha}, \frac{1}{\lambda \epsilon^2} \}$, where $\alpha\approx 0.338$ is the Otter's constant and $\frac{1}{\lambda \epsilon^2}$ is the Kesten-Stigum threshold. Our proof of low-degree hardness is based on a conditional variant of the low-degree likelihood calculation.
Computational Modelling of Plurality and Definiteness in Chinese Noun Phrases
Mar 07, 2024



Theoretical linguists have suggested that some languages (e.g., Chinese and Japanese) are "cooler" than other languages based on the observation that the intended meaning of phrases in these languages depends more on their contexts. As a result, many expressions in these languages are shortened, and their meaning is inferred from the context. In this paper, we focus on the omission of the plurality and definiteness markers in Chinese noun phrases (NPs) to investigate the predictability of their intended meaning given the contexts. To this end, we built a corpus of Chinese NPs, each of which is accompanied by its corresponding context, and by labels indicating its singularity/plurality and definiteness/indefiniteness. We carried out corpus assessments and analyses. The results suggest that Chinese speakers indeed drop plurality and definiteness markers very frequently. Building on the corpus, we train a bank of computational models using both classic machine learning models and state-of-the-art pre-trained language models to predict the plurality and definiteness of each NP. We report on the performance of these models and analyse their behaviours.
Intrinsic Task-based Evaluation for Referring Expression Generation
Feb 12, 2024



Recently, a human evaluation study of Referring Expression Generation (REG) models had an unexpected conclusion: on \textsc{webnlg}, Referring Expressions (REs) generated by the state-of-the-art neural models were not only indistinguishable from the REs in \textsc{webnlg} but also from the REs generated by a simple rule-based system. Here, we argue that this limitation could stem from the use of a purely ratings-based human evaluation (which is a common practice in Natural Language Generation). To investigate these issues, we propose an intrinsic task-based evaluation for REG models, in which, in addition to rating the quality of REs, participants were asked to accomplish two meta-level tasks. One of these tasks concerns the referential success of each RE; the other task asks participants to suggest a better alternative for each RE. The outcomes suggest that, in comparison to previous evaluations, the new evaluation protocol assesses the performance of each REG model more comprehensively and makes the participants' ratings more reliable and discriminable.