 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Judge Error Severity Like Humans?
Jun 05, 2025


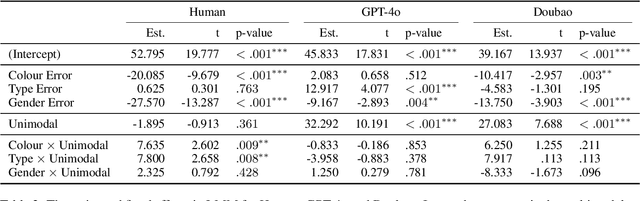
Large Language Models (LLMs) are increasingly used as automated evaluators in natural language generation, yet it remains unclear whether they can accurately replicate human judgments of error severity. In this study, we systematically compare human and LLM assessments of image descriptions containing controlled semantic errors. We extend the experimental framework of van Miltenburg et al. (2020) to both unimodal (text-only) and multimodal (text + image) settings, evaluating four error types: age, gender, clothing type, and clothing colour. Our findings reveal that humans assign varying levels of severity to different error types, with visual context significantly amplifying perceived severity for colour and type errors. Notably, most LLMs assign low scores to gender errors but disproportionately high scores to colour errors, unlike humans, who judge both as highly severe but for different reasons. This suggests that these models may have internalised social norms influencing gender judgments but lack the perceptual grounding to emulate human sensitivity to colour, which is shaped by distinct neural mechanisms. Only one of the evaluated LLMs, Doubao, replicates the human-like ranking of error severity, but it fails to distinguish between error types as clearly as humans. Surprisingly, DeepSeek-V3, a unimodal LLM, achieves the highest alignment with human judgments across both unimodal and multimodal conditions, outperforming even state-of-the-art multimodal models.
Multi-label classification for multi-temporal, multi-spatial coral reef condition monitoring using vision foundation model with adapter learning
Mar 29, 2025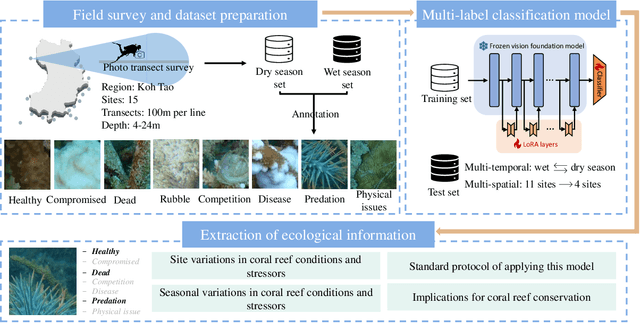
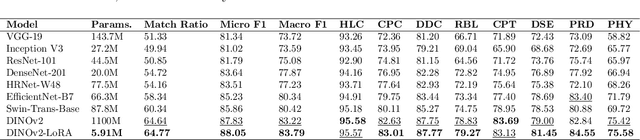
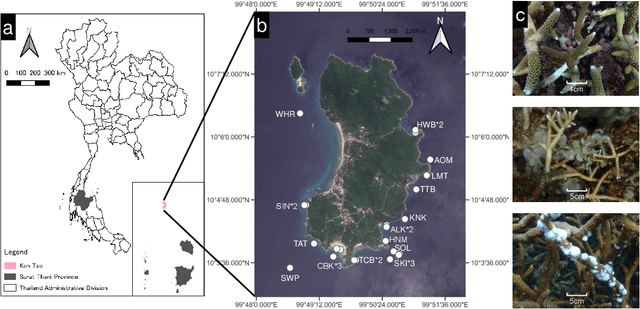
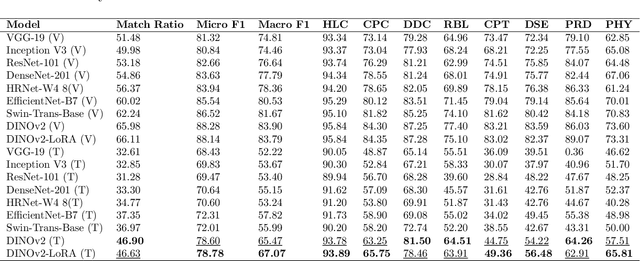
Coral reef ecosystems provide essential ecosystem services, but face significant threats from climate change and human activities. Although advances in deep learning have enabled automatic classification of coral reef conditions, conventional deep models struggle to achieve high performance when processing complex underwater ecological images. Vision foundation models, known for their high accuracy and cross-domain generalizability, offer promising solutions. However, fine-tuning these models requires substantial computational resources and results in high carbon emissions. To address these challenges, adapter learning methods such as Low-Rank Adaptation (LoRA) have emerged as a solution. This study introduces an approach integrating the DINOv2 vision foundation model with the LoRA fine-tuning method. The approach leverages multi-temporal field images collected through underwater surveys at 15 dive sites at Koh Tao, Thailand, with all images labeled according to universal standards used in citizen science-based conservation programs. The experimental results demonstrate that the DINOv2-LoRA model achieved superior accuracy, with a match ratio of 64.77%, compared to 60.34% achieved by the best conventional model. Furthermore, incorporating LoRA reduced the trainable parameters from 1,100M to 5.91M. Transfer learning experiments conducted under different temporal and spatial settings highlight the exceptional generalizability of DINOv2-LoRA across different seasons and sites. This study is the first to explore the efficient adaptation of foundation models for multi-label classification of coral reef conditions under multi-temporal and multi-spatial settings. The proposed method advances the classification of coral reef conditions and provides a tool for monitoring, conserving, and managing coral reef ecosystems.
See Behind Walls in Real-time Using Aerial Drones and Augmented Reality
Oct 17, 2024



This work presents ARD2, a framework that enables real-time through-wall surveillance using two aerial drones and an augmented reality (AR) device. ARD2 consists of two main steps: target direction estimation and contour reconstruction. In the first stage, ARD2 leverages geometric relationships between the drones, the user, and the target to project the target's direction onto the user's AR display. In the second stage, images from the drones are synthesized to reconstruct the target's contour, allowing the user to visualize the target behind walls. Experimental results demonstrate the system's accuracy in both direction estimation and contour reconstruction.
Underwater litter monitoring using consumer-grade aerial-aquatic speedy scanner (AASS) and deep learning based super-resolution reconstruction and detection network
Aug 07, 2024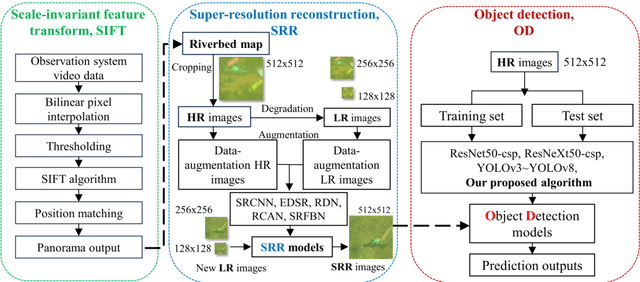

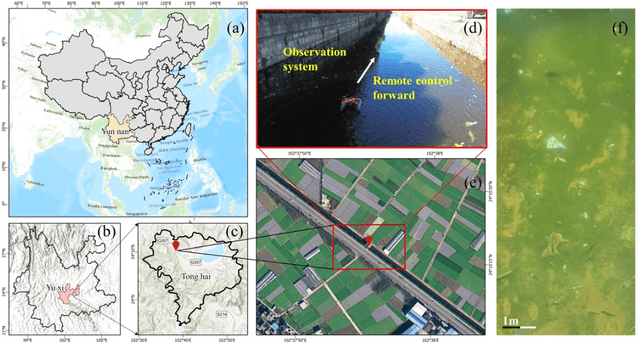

Underwater litter is widely spread across aquatic environments such as lakes, rivers, and oceans, significantly impacting natural ecosystems. Current monitoring technologies for detecting underwater litter face limitations in survey efficiency, cost, and environmental conditions, highlighting the need for efficient, consumer-grade technologies for automatic detection. This research introduces the Aerial-Aquatic Speedy Scanner (AASS) combined with Super-Resolution Reconstruction (SRR) and an improved YOLOv8 detection network. AASS enhances data acquisition efficiency over traditional methods, capturing high-quality images that accurately identify underwater waste. SRR improves image-resolution by mitigating motion blur and insufficient resolution, thereby enhancing detection tasks. Specifically, the RCAN model achieved the highest mean average precision (mAP) of 78.6% for detection accuracy on reconstructed images among the tested SRR models. With a magnification factor of 4, the SRR test set shows an improved mAP compared to the conventional bicubic set. These results demonstrate the effectiveness of the proposed method in detecting underwater litter.
Monitoring of Hermit Crabs Using drone-captured imagery and Deep Learning based Super-Resolution Reconstruction and Improved YOLOv8
Aug 07, 2024



Hermit crabs play a crucial role in coastal ecosystems by dispersing seeds, cleaning up debris, and disturbing soil. They serve as vital indicators of marine environmental health, responding to climate change and pollution. Traditional survey methods, like quadrat sampling, are labor-intensive, time-consuming, and environmentally dependent. This study presents an innovative approach combining UAV-based remote sensing with Super-Resolution Reconstruction (SRR) and the CRAB-YOLO detection network, a modification of YOLOv8s, to monitor hermit crabs. SRR enhances image quality by addressing issues such as motion blur and insufficient resolution, significantly improving detection accuracy over conventional low-resolution fuzzy images. The CRAB-YOLO network integrates three improvements for detection accuracy, hermit crab characteristics, and computational efficiency, achieving state-of-the-art (SOTA) performance compared to other mainstream detection models. The RDN networks demonstrated the best image reconstruction performance, and CRAB-YOLO achieved a mean average precision (mAP) of 69.5% on the SRR test set, a 40% improvement over the conventional Bicubic method with a magnification factor of 4. These results indicate that the proposed method is effective in detecting hermit crabs, offering a cost-effective and automated solution for extensive hermit crab monitoring, thereby aiding coastal benthos conservation.
ECRTime: Ensemble Integration of Classification and Retrieval for Time Series Classification
Jul 20, 2024



Deep learning-based methods for Time Series Classification (TSC) typically utilize deep networks to extract features, which are then processed through a combination of a Fully Connected (FC) layer and a SoftMax function. However, we have observed the phenomenon of inter-class similarity and intra-class inconsistency in the datasets from the UCR archive and further analyzed how this phenomenon adversely affects the "FC+SoftMax" paradigm. To address the issue, we introduce ECR, which, for the first time to our knowledge, applies deep learning-based retrieval algorithm to the TSC problem and integrates classification and retrieval models. Experimental results on 112 UCR datasets demonstrate that ECR is state-of-the-art(sota) compared to existing deep learning-based methods. Furthermore, we have developed a more precise classifier, ECRTime, which is an ensemble of ECR. ECRTime surpasses the currently most accurate deep learning classifier, InceptionTime, in terms of accuracy, achieving this with reduced training time and comparable scalability.
GBG++: A Fast and Stable Granular Ball Generation Method for Classification
May 29, 2023



Granular ball computing (GBC), as an efficient, robust, and scalable learning method, has become a popular research topic of granular computing. GBC includes two stages: granular ball generation (GBG) and multi-granularity learning based on the granular ball (GB). However, the stability and efficiency of existing GBG methods need to be further improved due to their strong dependence on $k$-means or $k$-division. In addition, GB-based classifiers only unilaterally consider the GB's geometric characteristics to construct classification rules, but the GB's quality is ignored. Therefore, in this paper, based on the attention mechanism, a fast and stable GBG (GBG++) method is proposed first. Specifically, the proposed GBG++ method only needs to calculate the distances from the data-driven center to the undivided samples when splitting each GB, instead of randomly selecting the center and calculating the distances between it to all samples. Moreover, an outlier detection method is introduced to identify local outliers. Consequently, the GBG++ method can significantly improve effectiveness, robustness, and efficiency while being absolutely stable. Second, considering the influence of the sample size within the GB on the GB's quality, based on the GBG++ method, a $k$-nearest neighbors algorithm (GB$k$NN++) which can reduce misclassification at class boundary to some extent is presented. Finally, the experimental results indicate that the proposed method outperforms several existing GB-based classifiers and classical machine learning classifiers on $20$ public benchmark data sets.
Interactive Feature Embedding for Infrared and Visible Image Fusion
Nov 09, 2022General deep learning-based methods for infrared and visible image fusion rely on the unsupervised mechanism for vital information retention by utilizing elaborately designed loss functions. However, the unsupervised mechanism depends on a well designed loss function, which cannot guarantee that all vital information of source images is sufficiently extracted. In this work, we propose a novel interactive feature embedding in self-supervised learning framework for infrared and visible image fusion, attempting to overcome the issue of vital information degradation. With the help of self-supervised learning framework, hierarchical representations of source images can be efficiently extracted. In particular, interactive feature embedding models are tactfully designed to build a bridge between the self-supervised learning and infrared and visible image fusion learning, achieving vital information retention. Qualitative and quantitative evaluations exhibit that the proposed method performs favorably against state-of-the-art methods.
High-order structure preserving graph neural network for few-shot learning
May 29, 2020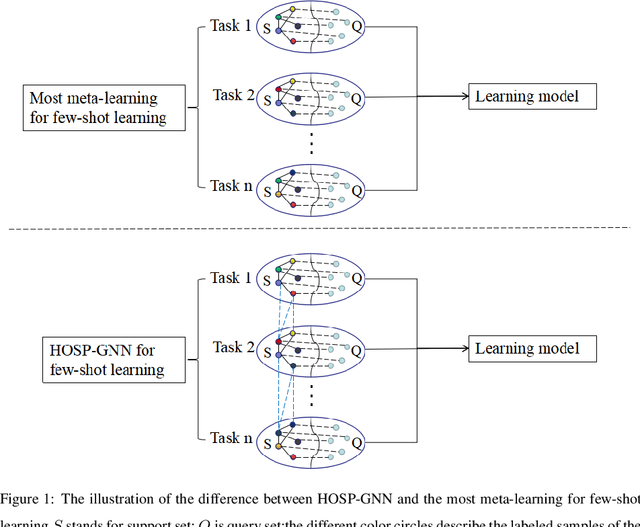
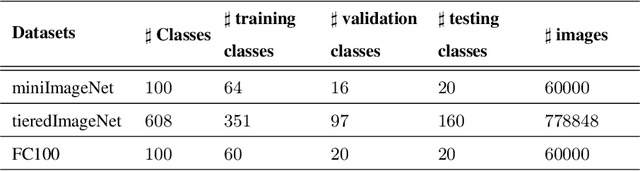


Few-shot learning can find the latent structure information between the prior knowledge and the queried data by the similarity metric of meta-learning to construct the discriminative model for recognizing the new categories with the rare labeled samples. Most existing methods try to model the similarity relationship of the samples in the intra tasks, and generalize the model to identify the new categories. However, the relationship of samples between the separated tasks is difficultly considered because of the different metric criterion in the respective tasks. In contrast, the proposed high-order structure preserving graph neural network(HOSP-GNN) can further explore the rich structure of the samples to predict the label of the queried data on graph that enables the structure evolution to explicitly discriminate the categories by iteratively updating the high-order structure relationship (the relative metric in multi-samples,instead of pairwise sample metric) with the manifold structure constraints. HOSP-GNN can not only mine the high-order structure for complementing the relevance between samples that may be divided into the different task in meta-learning, and but also generate the rule of the structure updating by manifold constraint. Furthermore, HOSP-GNN doesn't need retrain the learning model for recognizing the new classes, and HOSP-GNN has the well-generalizable high-order structure for model adaptability. Experiments show that HOSP-GNN outperforms the state-of-the-art methods on supervised and semi-supervised few-shot learning in three benchmark datasets that are miniImageNet, tieredImageNet and FC100.
Deep graph learning for semi-supervised classification
May 29, 2020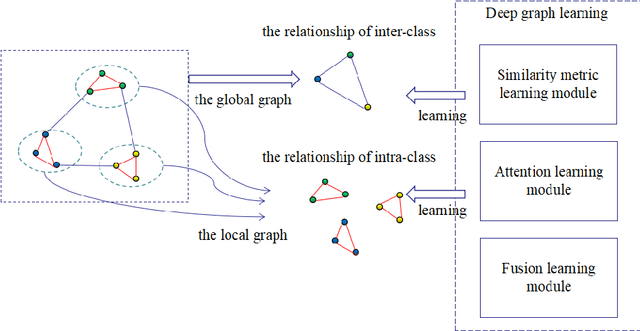
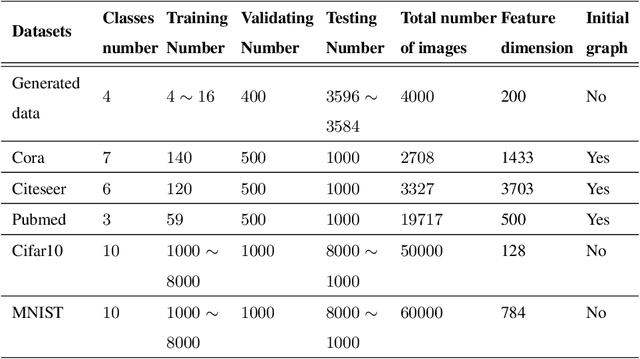
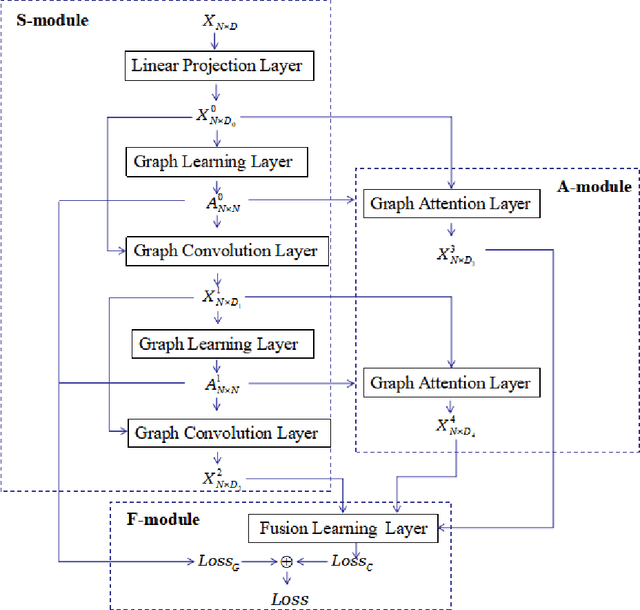
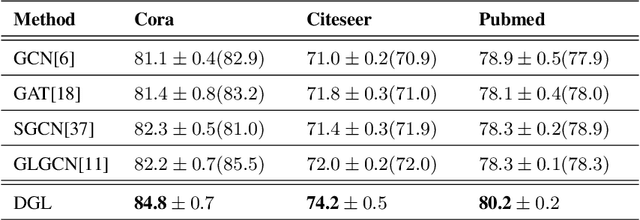
Graph learning (GL) can dynamically capture the distribution structure (graph structure) of data based on graph convolutional networks (GCN), and the learning quality of the graph structure directly influences GCN for semi-supervised classification. Existing methods mostly combine the computational layer and the related losses into GCN for exploring the global graph(measuring graph structure from all data samples) or local graph (measuring graph structure from local data samples). Global graph emphasises on the whole structure description of the inter-class data, while local graph trend to the neighborhood structure representation of intra-class data. However, it is difficult to simultaneously balance these graphs of the learning process for semi-supervised classification because of the interdependence of these graphs. To simulate the interdependence, deep graph learning(DGL) is proposed to find the better graph representation for semi-supervised classification. DGL can not only learn the global structure by the previous layer metric computation updating, but also mine the local structure by next layer local weight reassignment. Furthermore, DGL can fuse the different structures by dynamically encoding the interdependence of these structures, and deeply mine the relationship of the different structures by the hierarchical progressive learning for improving the performance of semi-supervised classification. Experiments demonstrate the DGL outperforms state-of-the-art methods on three benchmark datasets (Citeseer,Cora, and Pubmed) for citation networks and two benchmark datasets (MNIST and Cifar10) for images.