 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
Matrix Completion Via Reweighted Logarithmic Norm Minimization
Dec 24, 2025Low-rank matrix completion (LRMC) has demonstrated remarkable success in a wide range of applications. To address the NP-hard nature of the rank minimization problem, the nuclear norm is commonly used as a convex and computationally tractable surrogate for the rank function. However, this approach often yields suboptimal solutions due to the excessive shrinkage of singular values. In this letter, we propose a novel reweighted logarithmic norm as a more effective nonconvex surrogate, which provides a closer approximation than many existing alternatives. We efficiently solve the resulting optimization problem by employing the alternating direction method of multipliers (ADMM). Experimental results on image inpainting demonstrate that the proposed method achieves superior performance compared to state-of-the-art LRMC approaches, both in terms of visual quality and quantitative metrics.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
Source-free domain adaptation based on label reliability for cross-domain bearing fault diagnosis
Mar 11, 2025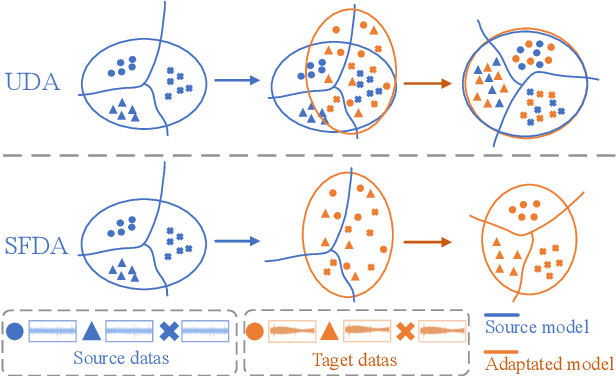

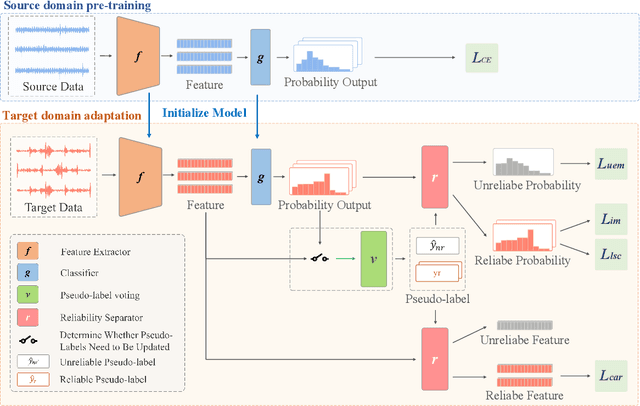

Source-free domain adaptation (SFDA) has been exploited for cross-domain bearing fault diagnosis without access to source data. Current methods select partial target samples with reliable pseudo-labels for model adaptation, which is sub-optimal due to the ignored target samples. We argue that every target sample can contribute to model adaptation, and accordingly propose in this paper a novel SFDA-based approach for bearing fault diagnosis that exploits both reliable and unreliable pseudo-labels. We develop a data-augmentation-based label voting strategy to divide the target samples into reliable and unreliable ones. We propose to explore the underlying relation between feature space and label space by using the reliable pseudo-labels as ground-truth labels, meanwhile, alleviating negative transfer by maximizing the entropy of the unreliable pseudo-labels. The proposed method achieves well-balance between discriminability and diversity by taking advantage of reliable and unreliable pseudo-labels. Extensive experiments are conducted on two bearing fault benchmarks, demonstrating that our approach achieves significant performance improvements against existing SFDA-based bearing fault diagnosis methods. Our code is available at https://github.com/BdLab405/SDALR.
Sequential three-way group decision-making for double hierarchy hesitant fuzzy linguistic term set
Jun 27, 2024



Group decision-making (GDM) characterized by complexity and uncertainty is an essential part of various life scenarios. Most existing researches lack tools to fuse information quickly and interpret decision results for partially formed decisions. This limitation is particularly noticeable when there is a need to improve the efficiency of GDM. To address this issue, a novel multi-level sequential three-way decision for group decision-making (S3W-GDM) method is constructed from the perspective of granular computing. This method simultaneously considers the vagueness, hesitation, and variation of GDM problems under double hierarchy hesitant fuzzy linguistic term sets (DHHFLTS) environment. First, for fusing information efficiently, a novel multi-level expert information fusion method is proposed, and the concepts of expert decision table and the extraction/aggregation of decision-leveled information based on the multi-level granularity are defined. Second, the neighborhood theory, outranking relation and regret theory (RT) are utilized to redesign the calculations of conditional probability and relative loss function. Then, the granular structure of DHHFLTS based on the sequential three-way decision (S3WD) is defined to improve the decision-making efficiency, and the decision-making strategy and interpretation of each decision-level are proposed. Furthermore, the algorithm of S3W-GDM is given. Finally, an illustrative example of diagnosis is presented, and the comparative and sensitivity analysis with other methods are performed to verify the efficiency and rationality of the proposed method.
Utilizing Autoregressive Networks for Full Lifecycle Data Generation of Rolling Bearings for RUL Prediction
Jan 02, 2024The prediction of rolling bearing lifespan is of significant importance in industrial production. However, the scarcity of high-quality, full lifecycle data has been a major constraint in achieving precise predictions. To address this challenge, this paper introduces the CVGAN model, a novel framework capable of generating one-dimensional vibration signals in both horizontal and vertical directions, conditioned on historical vibration data and remaining useful life. In addition, we propose an autoregressive generation method that can iteratively utilize previously generated vibration information to guide the generation of current signals. The effectiveness of the CVGAN model is validated through experiments conducted on the PHM 2012 dataset. Our findings demonstrate that the CVGAN model, in terms of both MMD and FID metrics, outperforms many advanced methods in both autoregressive and non-autoregressive generation modes. Notably, training using the full lifecycle data generated by the CVGAN model significantly improves the performance of the predictive model. This result highlights the effectiveness of the data generated by CVGans in enhancing the predictive power of these models.
Utilizing Multiple Inputs Autoregressive Models for Bearing Remaining Useful Life Prediction
Nov 26, 2023



Accurate prediction of the Remaining Useful Life (RUL) of rolling bearings is crucial in industrial production, yet existing models often struggle with limited generalization capabilities due to their inability to fully process all vibration signal patterns. We introduce a novel multi-input autoregressive model to address this challenge in RUL prediction for bearings. Our approach uniquely integrates vibration signals with previously predicted Health Indicator (HI) values, employing feature fusion to output current window HI values. Through autoregressive iterations, the model attains a global receptive field, effectively overcoming the limitations in generalization. Furthermore, we innovatively incorporate a segmentation method and multiple training iterations to mitigate error accumulation in autoregressive models. Empirical evaluation on the PMH2012 dataset demonstrates that our model, compared to other backbone networks using similar autoregressive approaches, achieves significantly lower Root Mean Square Error (RMSE) and Score. Notably, it outperforms traditional autoregressive models that use label values as inputs and non-autoregressive networks, showing superior generalization abilities with a marked lead in RMSE and Score metrics.
Utilizing VQ-VAE for End-to-End Health Indicator Generation in Predicting Rolling Bearing RUL
Nov 17, 2023The prediction of the remaining useful life (RUL) of rolling bearings is a pivotal issue in industrial production. A crucial approach to tackling this issue involves transforming vibration signals into health indicators (HI) to aid model training. This paper presents an end-to-end HI construction method, vector quantised variational autoencoder (VQ-VAE), which addresses the need for dimensionality reduction of latent variables in traditional unsupervised learning methods such as autoencoder. Moreover, concerning the inadequacy of traditional statistical metrics in reflecting curve fluctuations accurately, two novel statistical metrics, mean absolute distance (MAD) and mean variance (MV), are introduced. These metrics accurately depict the fluctuation patterns in the curves, thereby indicating the model's accuracy in discerning similar features. On the PMH2012 dataset, methods employing VQ-VAE for label construction achieved lower values for MAD and MV. Furthermore, the ASTCN prediction model trained with VQ-VAE labels demonstrated commendable performance, attaining the lowest values for MAD and MV.
Data-Free Distillation of Language Model by Text-to-Text Transfer
Nov 03, 2023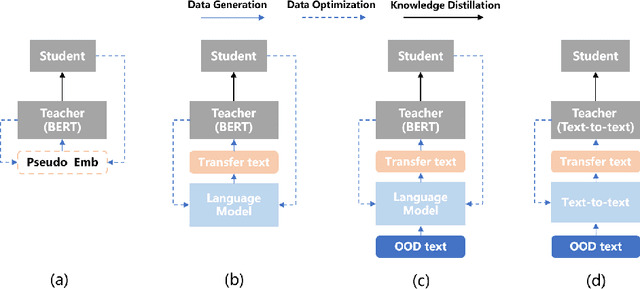


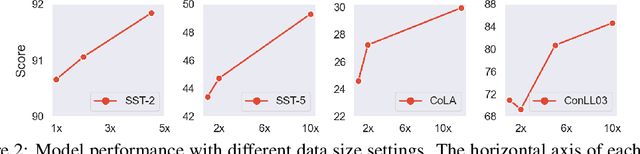
Data-Free Knowledge Distillation (DFKD) plays a vital role in compressing the model when original training data is unavailable. Previous works for DFKD in NLP mainly focus on distilling encoder-only structures like BERT on classification tasks, which overlook the notable progress of generative language modeling. In this work, we propose a novel DFKD framework, namely DFKD-T$^{3}$, where the pretrained generative language model can also serve as a controllable data generator for model compression. This novel framework DFKD-T$^{3}$ leads to an end-to-end learnable text-to-text framework to transform the general domain corpus to compression-friendly task data, targeting to improve both the \textit{specificity} and \textit{diversity}. Extensive experiments show that our method can boost the distillation performance in various downstream tasks such as sentiment analysis, linguistic acceptability, and information extraction. Furthermore, we show that the generated texts can be directly used for distilling other language models and outperform the SOTA methods, making our method more appealing in a general DFKD setting. Our code is available at https://gitee.com/mindspore/models/tree/master/research/nlp/DFKD\_T3.
Multiscale Positive-Unlabeled Detection of AI-Generated Texts
Jun 02, 2023
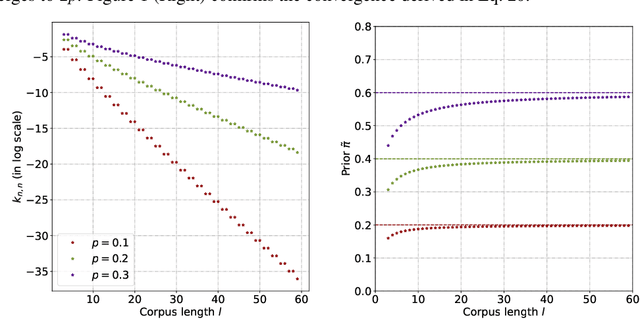


Recent releases of Large Language Models (LLMs), e.g. ChatGPT, are astonishing at generating human-like texts, but they may get misused for fake scholarly texts, fake news, fake tweets, et cetera. Previous works have proposed methods to detect these multiscale AI-generated texts, including simple ML classifiers, pretrained-model-based training-agnostic methods, and finetuned language classification models. However, mainstream detectors are formulated without considering the factor of corpus length: shorter corpuses are harder to detect compared with longer ones for shortage of informative features. In this paper, a Multiscale Positive-Unlabeled (MPU) training framework is proposed to address the challenge of multiscale text detection. Firstly, we acknowledge the human-resemblance property of short machine texts, and rephrase text classification as a Positive-Unlabeled (PU) problem by marking these short machine texts as "unlabeled" during training. In this PU context, we propose the length-sensitive Multiscale PU Loss, where we use a recurrent model in abstraction to estimate positive priors of scale-variant corpuses. Additionally, we introduce a Text Multiscaling module to enrich training corpuses. Experiments show that our MPU method augments detection performance on long AI-generated text, and significantly improves short-corpus detection of language model detectors. Language Models trained with MPU could outcompete existing detectors by large margins on multiscale AI-generated texts. The codes are available at https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt and https://github.com/YuchuanTian/AIGC_text_detector.