 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-free domain adaptation based on label reliability for cross-domain bearing fault diagnosis
Paper and Code
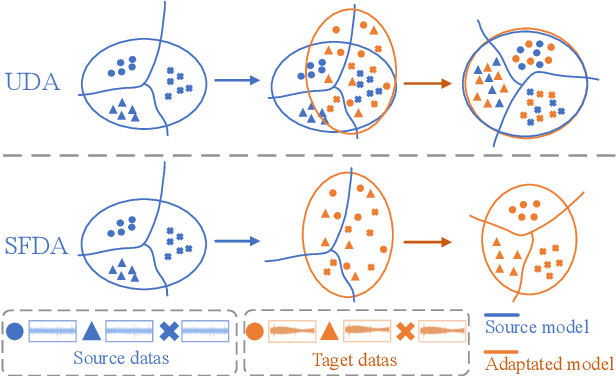

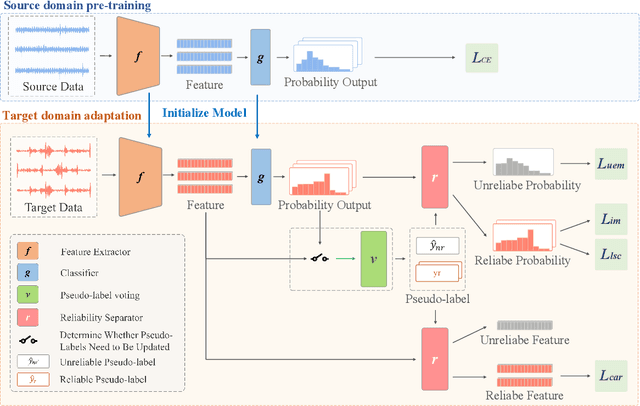

Source-free domain adaptation (SFDA) has been exploited for cross-domain bearing fault diagnosis without access to source data. Current methods select partial target samples with reliable pseudo-labels for model adaptation, which is sub-optimal due to the ignored target samples. We argue that every target sample can contribute to model adaptation, and accordingly propose in this paper a novel SFDA-based approach for bearing fault diagnosis that exploits both reliable and unreliable pseudo-labels. We develop a data-augmentation-based label voting strategy to divide the target samples into reliable and unreliable ones. We propose to explore the underlying relation between feature space and label space by using the reliable pseudo-labels as ground-truth labels, meanwhile, alleviating negative transfer by maximizing the entropy of the unreliable pseudo-labels. The proposed method achieves well-balance between discriminability and diversity by taking advantage of reliable and unreliable pseudo-labels. Extensive experiments are conducted on two bearing fault benchmarks, demonstrating that our approach achieves significant performance improvements against existing SFDA-based bearing fault diagnosis methods. Our code is available at https://github.com/BdLab405/SDALR.