 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-free domain adaptation based on label reliability for cross-domain bearing fault diagnosis
Mar 11, 2025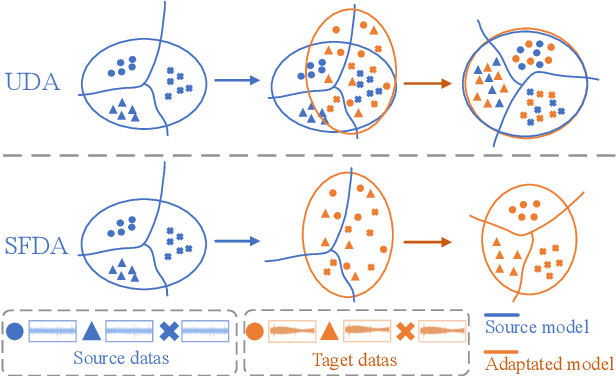

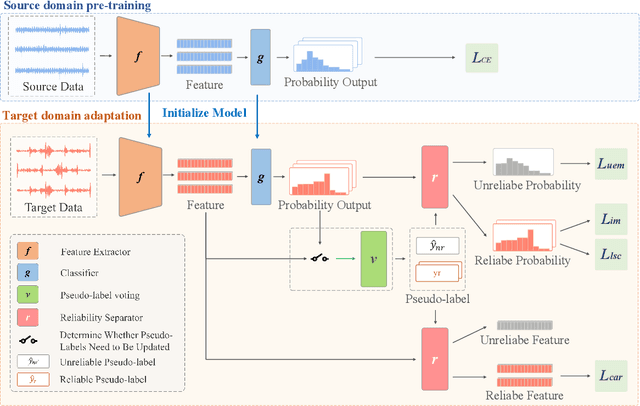

Source-free domain adaptation (SFDA) has been exploited for cross-domain bearing fault diagnosis without access to source data. Current methods select partial target samples with reliable pseudo-labels for model adaptation, which is sub-optimal due to the ignored target samples. We argue that every target sample can contribute to model adaptation, and accordingly propose in this paper a novel SFDA-based approach for bearing fault diagnosis that exploits both reliable and unreliable pseudo-labels. We develop a data-augmentation-based label voting strategy to divide the target samples into reliable and unreliable ones. We propose to explore the underlying relation between feature space and label space by using the reliable pseudo-labels as ground-truth labels, meanwhile, alleviating negative transfer by maximizing the entropy of the unreliable pseudo-labels. The proposed method achieves well-balance between discriminability and diversity by taking advantage of reliable and unreliable pseudo-labels. Extensive experiments are conducted on two bearing fault benchmarks, demonstrating that our approach achieves significant performance improvements against existing SFDA-based bearing fault diagnosis methods. Our code is available at https://github.com/BdLab405/SDALR.
Cross-View Panorama Image Synthesis
Mar 22, 2022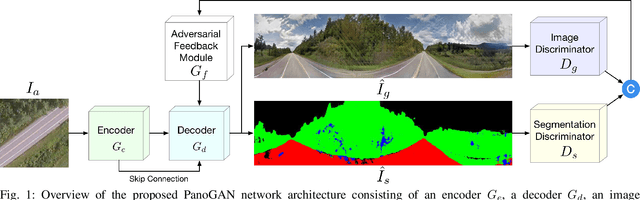
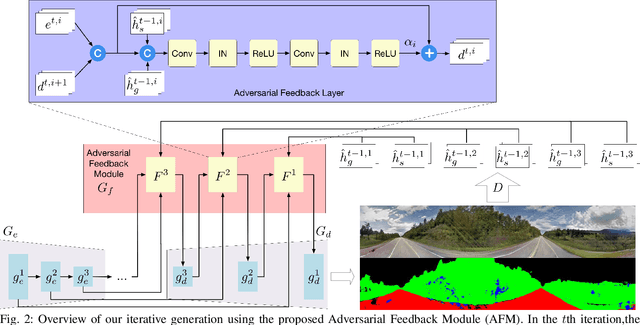
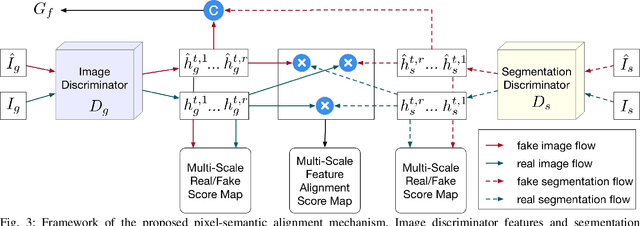

In this paper, we tackle the problem of synthesizing a ground-view panorama image conditioned on a top-view aerial image, which is a challenging problem due to the large gap between the two image domains with different view-points. Instead of learning cross-view mapping in a feedforward pass, we propose a novel adversarial feedback GAN framework named PanoGAN with two key components: an adversarial feedback module and a dual branch discrimination strategy. First, the aerial image is fed into the generator to produce a target panorama image and its associated segmentation map in favor of model training with layout semantics. Second, the feature responses of the discriminator encoded by our adversarial feedback module are fed back to the generator to refine the intermediate representations, so that the generation performance is continually improved through an iterative generation process. Third, to pursue high-fidelity and semantic consistency of the generated panorama image, we propose a pixel-segmentation alignment mechanism under the dual branch discrimiantion strategy to facilitate cooperation between the generator and the discriminator. Extensive experimental results on two challenging cross-view image datasets show that PanoGAN enables high-quality panorama image generation with more convincing details than state-of-the-art approaches. The source code and trained models are available at \url{https://github.com/sswuai/PanoGAN}.
DF-GAN: Deep Fusion Generative Adversarial Networks for Text-to-Image Synthesis
Aug 13, 2020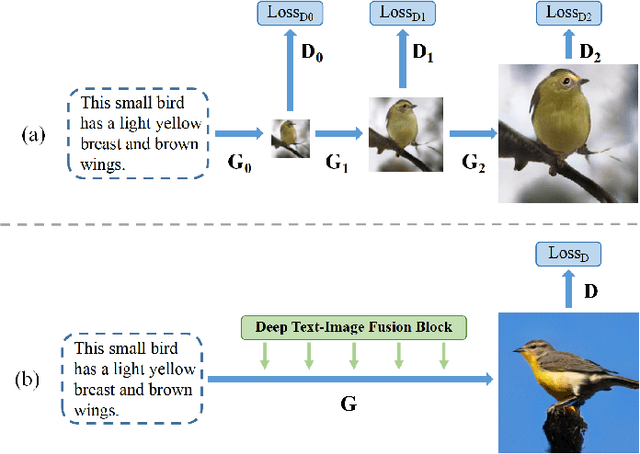

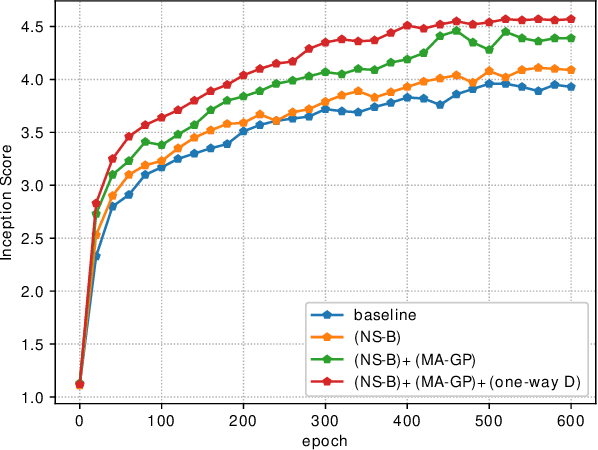
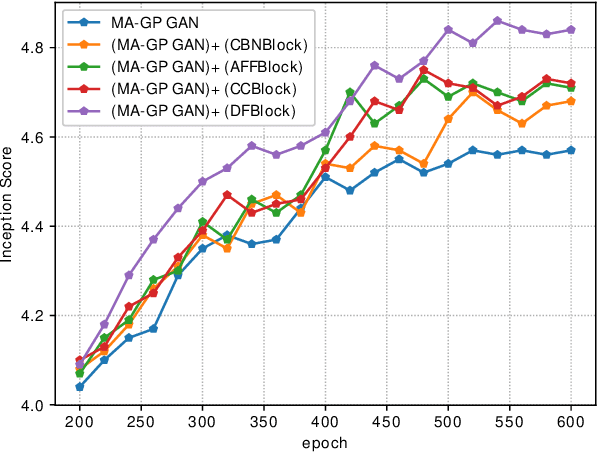
Synthesizing high-resolution realistic images from text descriptions is a challenging task. Almost all existing text-to-image methods employ stacked generative adversarial networks as the backbone, utilize cross-modal attention mechanisms to fuse text and image features, and use extra networks to ensure text-image semantic consistency. The existing text-to-image models have three problems: 1) For the backbone, there are multiple generators and discriminators stacked for generating different scales of images making the training process slow and inefficient. 2) For semantic consistency, the existing models employ extra networks to ensure the semantic consistency increasing the training complexity and bringing an additional computational cost. 3) For the text-image feature fusion method, cross-modal attention is only applied a few times during the generation process due to its computational cost impeding fusing the text and image features deeply. To solve these limitations, we propose 1) a novel simplified text-to-image backbone which is able to synthesize high-quality images directly by one pair of generator and discriminator, 2) a novel regularization method called Matching-Aware zero-centered Gradient Penalty which promotes the generator to synthesize more realistic and text-image semantic consistent images without introducing extra networks, 3) a novel fusion module called Deep Text-Image Fusion Block which can exploit the semantics of text descriptions effectively and fuse text and image features deeply during the generation process. Compared with the previous text-to-image models, our DF-GAN is simpler and more efficient and achieves better performance. Extensive experiments and ablation studies on both Caltech-UCSD Birds 200 and COCO datasets demonstrate the superiority of the proposed model in comparison to state-of-the-art models.
Cross-View Image Synthesis with Deformable Convolution and Attention Mechanism
Jul 20, 2020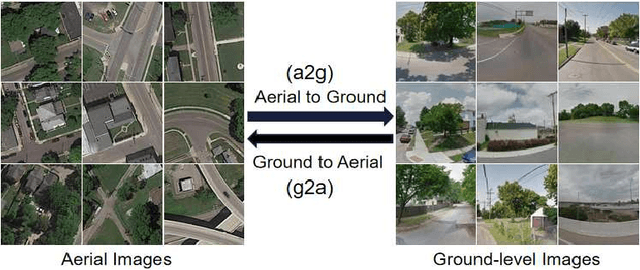
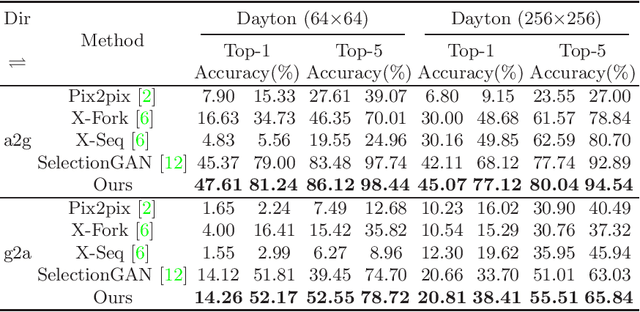
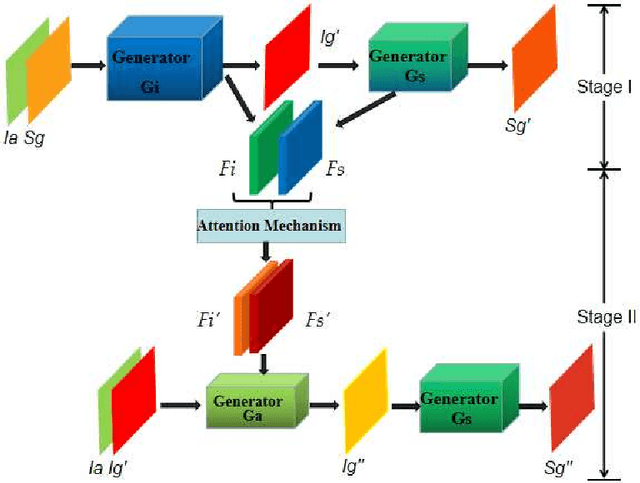
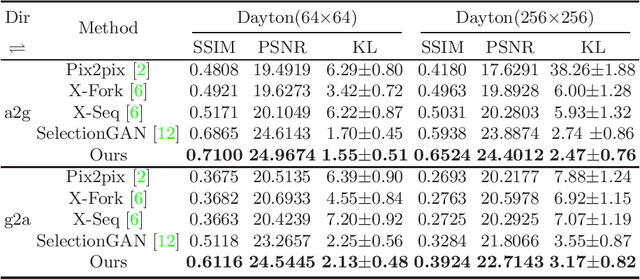
Learning to generate natural scenes has always been a daunting task in computer vision. This is even more laborious when generating images with very different views. When the views are very different, the view fields have little overlap or objects are occluded, leading the task very challenging. In this paper, we propose to use Generative Adversarial Networks(GANs) based on a deformable convolution and attention mechanism to solve the problem of cross-view image synthesis (see Fig.1). It is difficult to understand and transform scenes appearance and semantic information from another view, thus we use deformed convolution in the U-net network to improve the network's ability to extract features of objects at different scales. Moreover, to better learn the correspondence between images from different views, we apply an attention mechanism to refine the intermediate feature map thus generating more realistic images. A large number of experiments on different size images on the Dayton dataset[1] show that our model can produce better results than state-of-the-art methods.
Modal Regression based Structured Low-rank Matrix Recovery for Multi-view Learning
Mar 22, 2020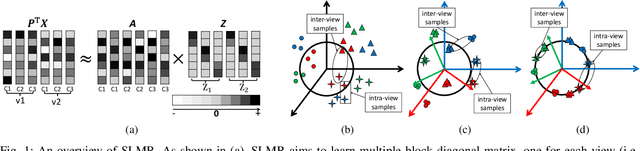
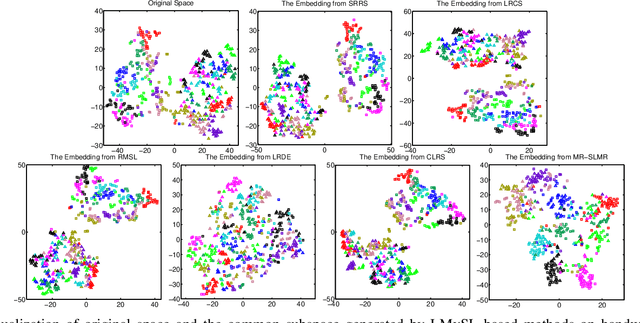

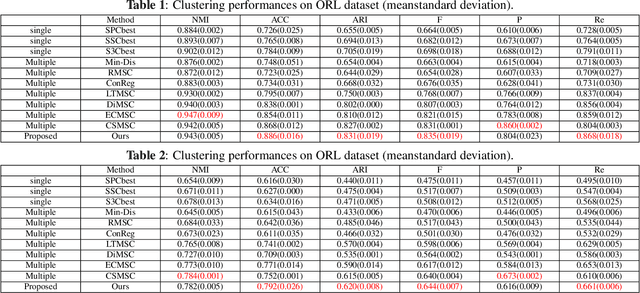
Low-rank Multi-view Subspace Learning (LMvSL) has shown great potential in cross-view classification in recent years. Despite their empirical success, existing LMvSL based methods are incapable of well handling view discrepancy and discriminancy simultaneously, which thus leads to the performance degradation when there is a large discrepancy among multi-view data. To circumvent this drawback, motivated by the block-diagonal representation learning, we propose Structured Low-rank Matrix Recovery (SLMR), a unique method of effectively removing view discrepancy and improving discriminancy through the recovery of structured low-rank matrix. Furthermore, recent low-rank modeling provides a satisfactory solution to address data contaminated by predefined assumptions of noise distribution, such as Gaussian or Laplacian distribution. However, these models are not practical since complicated noise in practice may violate those assumptions and the distribution is generally unknown in advance. To alleviate such limitation, modal regression is elegantly incorporated into the framework of SLMR (term it MR-SLMR). Different from previous LMvSL based methods, our MR-SLMR can handle any zero-mode noise variable that contains a wide range of noise, such as Gaussian noise, random noise and outliers. The alternating direction method of multipliers (ADMM) framework and half-quadratic theory are used to efficiently optimize MR-SLMR. Experimental results on four public databases demonstrate the superiority of MR-SLMR and its robustness to complicated noise.
Joint Learning of Self-Representation and Indicator for Multi-View Image Clustering
May 11, 2019
Multi-view subspace clustering aims to divide a set of multisource data into several groups according to their underlying subspace structure. Although the spectral clustering based methods achieve promotion in multi-view clustering, their utility is limited by the separate learning manner in which affinity matrix construction and cluster indicator estimation are isolated. In this paper, we propose to jointly learn the self-representation, continue and discrete cluster indicators in an unified model. Our model can explore the subspace structure of each view and fusion them to facilitate clustering simultaneously. Experimental results on two benchmark datasets demonstrate that our method outperforms other existing competitive multi-view clustering methods.
Structured Discriminative Tensor Dictionary Learning for Unsupervised Domain Adaptation
May 11, 2019

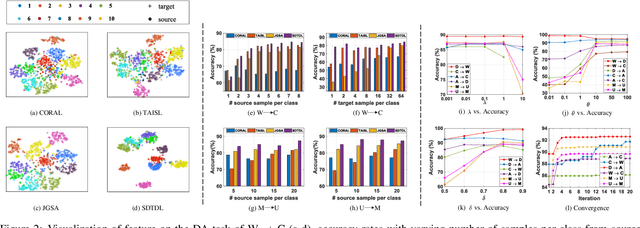
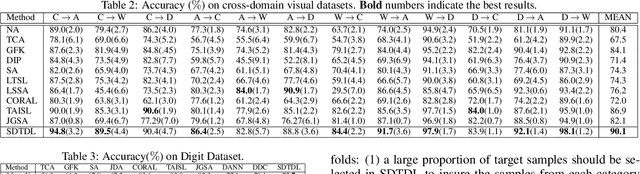
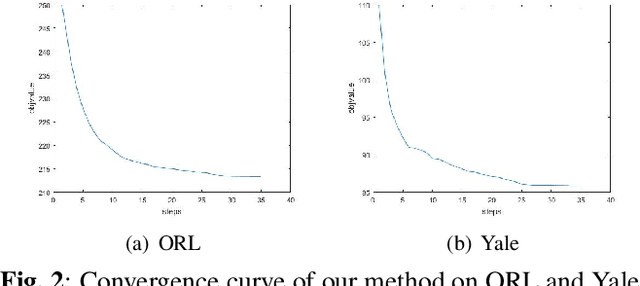
Unsupervised Domain Adaptation (UDA) addresses the problem of performance degradation due to domain shift between training and testing sets, which is common in computer vision applications. Most existing UDA approaches are based on vector-form data although the typical format of data or features in visual applications is multi-dimensional tensor. Besides, current methods, including the deep network approaches, assume that abundant labeled source samples are provided for training. However, the number of labeled source samples are always limited due to expensive annotation cost in practice, making sub-optimal performance been observed. In this paper, we propose to seek discriminative representation for multi-dimensional data by learning a structured dictionary in tensor space. The dictionary separates domain-specific information and class-specific information to guarantee the representation robust to domains. In addition, a pseudo-label estimation scheme is developed to combine with discriminant analysis in the algorithm iteration for avoiding the external classifier design. We perform extensive results on different datasets with limited source samples. Experimental results demonstrates that the proposed method outperforms the state-of-the-art approaches.
Robust Visual Tracking using Multi-Frame Multi-Feature Joint Modeling
Nov 19, 2018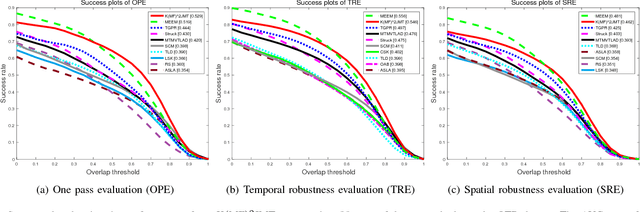
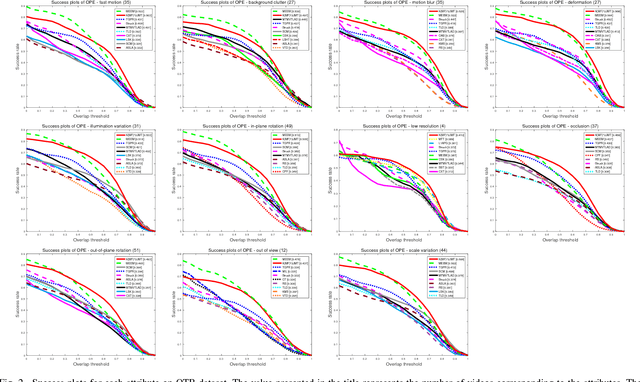
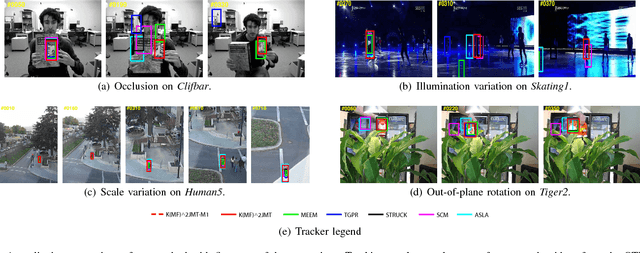
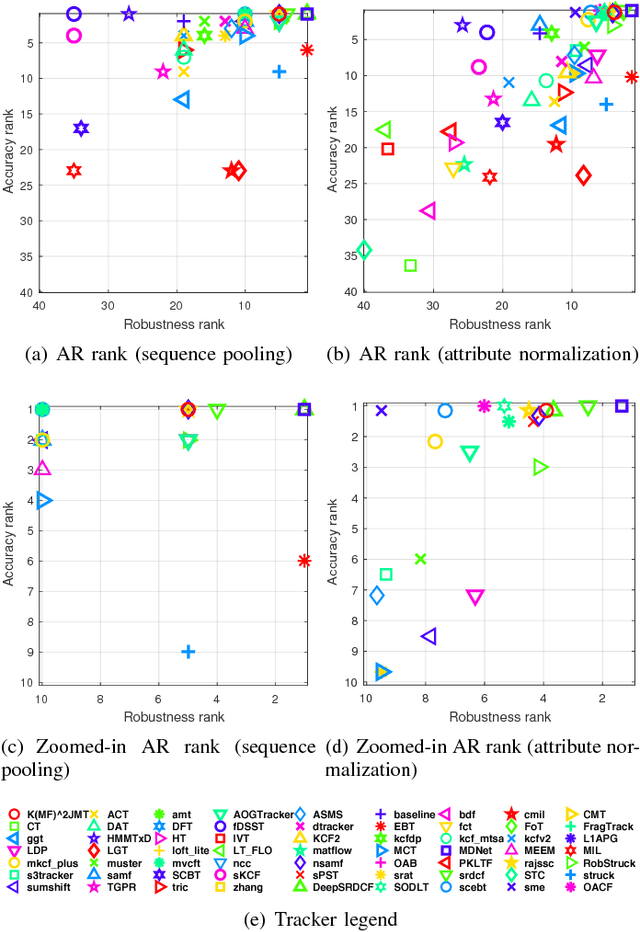
It remains a huge challenge to design effective and efficient trackers under complex scenarios, including occlusions, illumination changes and pose variations. To cope with this problem, a promising solution is to integrate the temporal consistency across consecutive frames and multiple feature cues in a unified model. Motivated by this idea, we propose a novel correlation filter-based tracker in this work, in which the temporal relatedness is reconciled under a multi-task learning framework and the multiple feature cues are modeled using a multi-view learning approach. We demonstrate the resulting regression model can be efficiently learned by exploiting the structure of blockwise diagonal matrix. A fast blockwise diagonal matrix inversion algorithm is developed thereafter for efficient online tracking. Meanwhile, we incorporate an adaptive scale estimation mechanism to strengthen the stability of scale variation tracking. We implement our tracker using two types of features and test it on two benchmark datasets. Experimental results demonstrate the superiority of our proposed approach when compared with other state-of-the-art trackers. project homepage http://bmal.hust.edu.cn/project/KMF2JMTtracking.html
Multi-view Common Component Discriminant Analysis for Cross-view Classification
May 20, 2018


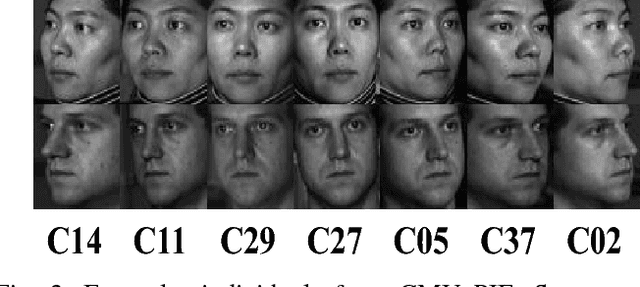
Cross-view classification that means to classify samples from heterogeneous views is a significant yet challenging problem in computer vision. A promising approach to handle this problem is the multi-view subspace learning (MvSL), which intends to find a common subspace for multi-view data. Despite the satisfactory results achieved by existing methods, the performance of previous work will be dramatically degraded when multi-view data lies on nonlinear manifolds. To circumvent this drawback, we propose Multi-view Common Component Discriminant Analysis (MvCCDA) to handle view discrepancy, discriminability and nonlinearity in a joint manner. Specifically, our MvCCDA incorporates supervised information and local geometric information into the common component extraction process to learn a discriminant common subspace and to discover the nonlinear structure embedded in multi-view data. We develop a kernel method of MvCCDA to further boost the performance of MvCCDA. Beyond kernel extension, optimization and complexity analysis of MvCCDA are also presented for completeness. Our MvCCDA is competitive with the state-of-the-art MvSL based methods on four benchmark datasets, demonstrating its superiority.
Multi-view Hybrid Embedding: A Divide-and-Conquer Approach
Apr 19, 2018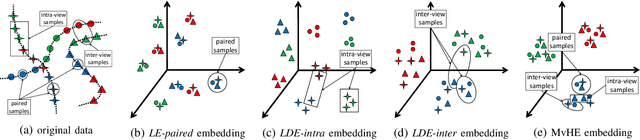
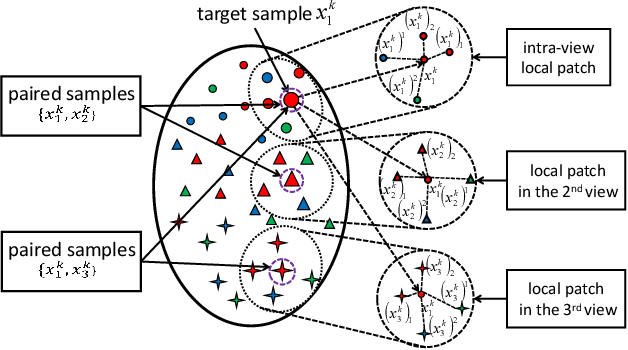
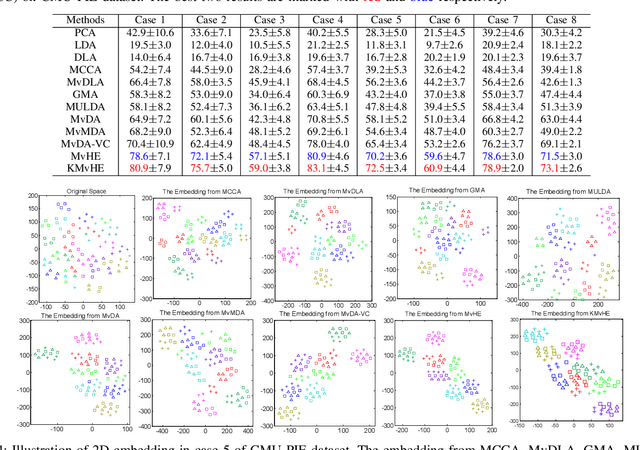
We present a novel cross-view classification algorithm where the gallery and probe data come from different views. A popular approach to tackle this problem is the multi-view subspace learning (MvSL) that aims to learn a latent subspace shared by multi-view data. Despite promising results obtained on some applications, the performance of existing methods deteriorates dramatically when the multi-view data is sampled from nonlinear manifolds or suffers from heavy outliers. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Multi-view Hybrid Embedding (MvHE), a unique method of dividing the problem of cross-view classification into three subproblems and building one model for each subproblem. Specifically, the first model is designed to remove view discrepancy, whereas the second and third models attempt to discover the intrinsic nonlinear structure and to increase discriminability in intra-view and inter-view samples respectively. The kernel extension is conducted to further boost the representation power of MvHE. Extensive experiments are conducted on four benchmark datasets. Our methods demonstrate overwhelming advantages against the state-of-the-art MvSL based cross-view classification approaches in terms of classification accuracy and robustness.