 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Image Synthesis with Deformable Convolution and Attention Mechanism
Paper and Code
Jul 20, 2020
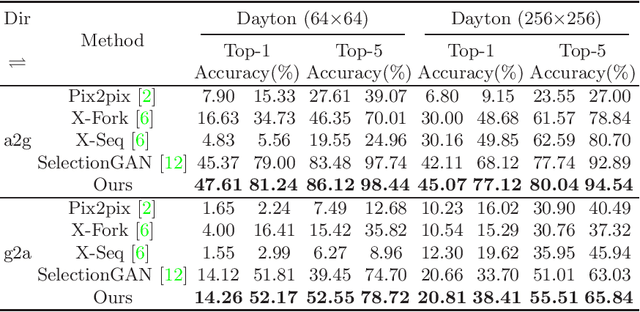
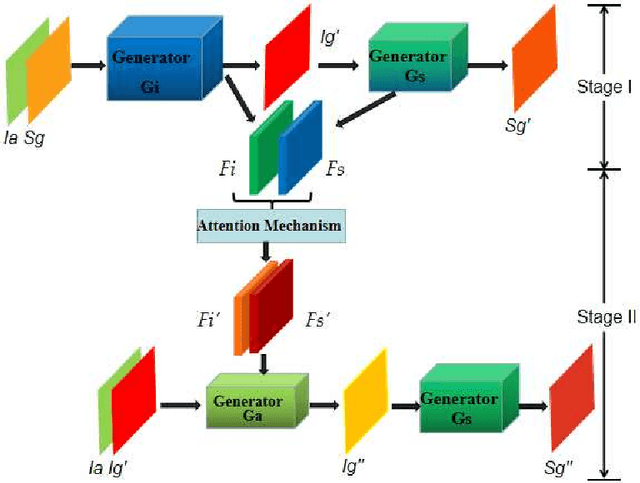
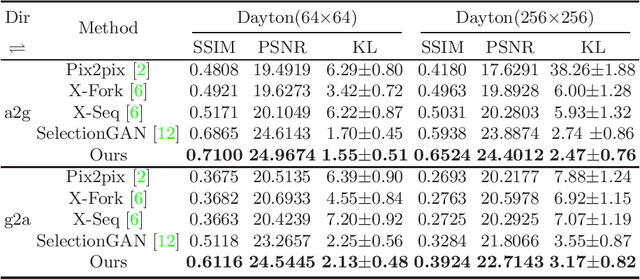
Learning to generate natural scenes has always been a daunting task in computer vision. This is even more laborious when generating images with very different views. When the views are very different, the view fields have little overlap or objects are occluded, leading the task very challenging. In this paper, we propose to use Generative Adversarial Networks(GANs) based on a deformable convolution and attention mechanism to solve the problem of cross-view image synthesis (see Fig.1). It is difficult to understand and transform scenes appearance and semantic information from another view, thus we use deformed convolution in the U-net network to improve the network's ability to extract features of objects at different scales. Moreover, to better learn the correspondence between images from different views, we apply an attention mechanism to refine the intermediate feature map thus generating more realistic images. A large number of experiments on different size images on the Dayton dataset[1] show that our model can produce better results than state-of-the-art methods.