 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Deterministic to Probabilistic: A Novel Perspective on Domain Generalization for Medical Image Segmentation
Dec 07, 2024Traditional domain generalization methods often rely on domain alignment to reduce inter-domain distribution differences and learn domain-invariant representations. However, domain shifts are inherently difficult to eliminate, which limits model generalization. To address this, we propose an innovative framework that enhances data representation quality through probabilistic modeling and contrastive learning, reducing dependence on domain alignment and improving robustness under domain variations. Specifically, we combine deterministic features with uncertainty modeling to capture comprehensive feature distributions. Contrastive learning enforces distribution-level alignment by aligning the mean and covariance of feature distributions, enabling the model to dynamically adapt to domain variations and mitigate distribution shifts. Additionally, we design a frequency-domain-based structural enhancement strategy using discrete wavelet transforms to preserve critical structural details and reduce visual distortions caused by style variations. Experimental results demonstrate that the proposed framework significantly improves segmentation performance, providing a robust solution to domain generalization challenges in medical image segmentation.
Boundless Across Domains: A New Paradigm of Adaptive Feature and Cross-Attention for Domain Generalization in Medical Image Segmentation
Nov 22, 2024



Domain-invariant representation learning is a powerful method for domain generalization. Previous approaches face challenges such as high computational demands, training instability, and limited effectiveness with high-dimensional data, potentially leading to the loss of valuable features. To address these issues, we hypothesize that an ideal generalized representation should exhibit similar pattern responses within the same channel across cross-domain images. Based on this hypothesis, we use deep features from the source domain as queries, and deep features from the generated domain as keys and values. Through a cross-channel attention mechanism, the original deep features are reconstructed into robust regularization representations, forming an explicit constraint that guides the model to learn domain-invariant representations. Additionally, style augmentation is another common method. However, existing methods typically generate new styles through convex combinations of source domains, which limits the diversity of training samples by confining the generated styles to the original distribution. To overcome this limitation, we propose an Adaptive Feature Blending (AFB) method that generates out-of-distribution samples while exploring the in-distribution space, significantly expanding the domain range. Extensive experimental results demonstrate that our proposed methods achieve superior performance on two standard domain generalization benchmarks for medical image segmentation.
Target-aware Bi-Transformer for Few-shot Segmentation
Sep 18, 2023Traditional semantic segmentation tasks require a large number of labels and are difficult to identify unlearned categories. Few-shot semantic segmentation (FSS) aims to use limited labeled support images to identify the segmentation of new classes of objects, which is very practical in the real world. Previous researches were primarily based on prototypes or correlations. Due to colors, textures, and styles are similar in the same image, we argue that the query image can be regarded as its own support image. In this paper, we proposed the Target-aware Bi-Transformer Network (TBTNet) to equivalent treat of support images and query image. A vigorous Target-aware Transformer Layer (TTL) also be designed to distill correlations and force the model to focus on foreground information. It treats the hypercorrelation as a feature, resulting a significant reduction in the number of feature channels. Benefit from this characteristic, our model is the lightest up to now with only 0.4M learnable parameters. Futhermore, TBTNet converges in only 10% to 25% of the training epochs compared to traditional methods. The excellent performance on standard FSS benchmarks of PASCAL-5i and COCO-20i proves the efficiency of our method. Extensive ablation studies were also carried out to evaluate the effectiveness of Bi-Transformer architecture and TTL.
PFENet++: Boosting Few-shot Semantic Segmentation with the Noise-filtered Context-aware Prior Mask
Sep 28, 2021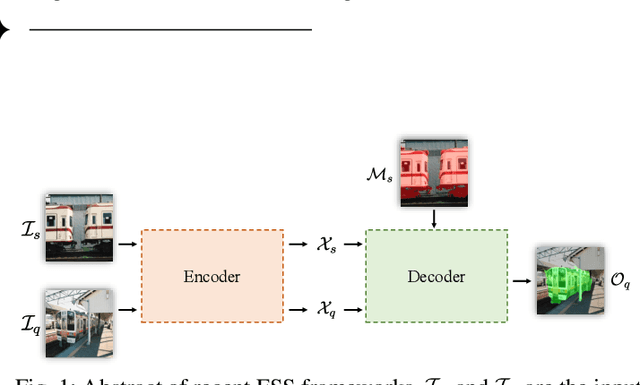



In this work, we revisit the prior mask guidance proposed in "Prior Guided Feature Enrichment Network for Few-Shot Segmentation". The prior mask serves as an indicator that highlights the region of interests of unseen categories, and it is effective in achieving better performance on different frameworks of recent studies. However, the current method directly takes the maximum element-to-element correspondence between the query and support features to indicate the probability of belonging to the target class, thus the broader contextual information is seldom exploited during the prior mask generation. To address this issue, first, we propose the Context-aware Prior Mask (CAPM) that leverages additional nearby semantic cues for better locating the objects in query images. Second, since the maximum correlation value is vulnerable to noisy features, we take one step further by incorporating a lightweight Noise Suppression Module (NSM) to screen out the unnecessary responses, yielding high-quality masks for providing the prior knowledge. Both two contributions are experimentally shown to have substantial practical merit, and the new model named PFENet++ significantly outperforms the baseline PFENet as well as all other competitors on three challenging benchmarks PASCAL-5$^i$, COCO-20$^i$ and FSS-1000. The new state-of-the-art performance is achieved without compromising the efficiency, manifesting the potential for being a new strong baseline in few-shot semantic segmentation. Our code will be available at https://github.com/dvlab-research/PFENet++.
Low-Rank Matrix Recovery from Noisy via an MDL Framework-based Atomic Norm
Sep 17, 2020



The recovery of the underlying low-rank structure of clean data corrupted with sparse noise/outliers is attracting increasing interest. However, in many low-level vision problems, the exact target rank of the underlying structure, the particular locations and values of the sparse outliers are not known. Thus, the conventional methods can not separate the low-rank and sparse components completely, especially gross outliers or deficient observations. Therefore, in this study, we employ the Minimum Description Length (MDL) principle and atomic norm for low-rank matrix recovery to overcome these limitations. First, we employ the atomic norm to find all the candidate atoms of low-rank and sparse terms, and then we minimize the description length of the model in order to select the appropriate atoms of low-rank and the sparse matrix, respectively. Our experimental analyses show that the proposed approach can obtain a higher success rate than the state-of-the-art methods even when the number of observations is limited or the corruption ratio is high. Experimental results about synthetic data and real sensing applications (high dynamic range imaging, background modeling, removing shadows and specularities) demonstrate the effectiveness, robustness and efficiency of the proposed method.
Learning a Deep Part-based Representation by Preserving Data Distribution
Sep 17, 2020



Unsupervised dimensionality reduction is one of the commonly used techniques in the field of high dimensional data recognition problems. The deep autoencoder network which constrains the weights to be non-negative, can learn a low dimensional part-based representation of data. On the other hand, the inherent structure of the each data cluster can be described by the distribution of the intraclass samples. Then one hopes to learn a new low dimensional representation which can preserve the intrinsic structure embedded in the original high dimensional data space perfectly. In this paper, by preserving the data distribution, a deep part-based representation can be learned, and the novel algorithm is called Distribution Preserving Network Embedding (DPNE). In DPNE, we first need to estimate the distribution of the original high dimensional data using the $k$-nearest neighbor kernel density estimation, and then we seek a part-based representation which respects the above distribution. The experimental results on the real-world data sets show that the proposed algorithm has good performance in terms of cluster accuracy and AMI. It turns out that the manifold structure in the raw data can be well preserved in the low dimensional feature space.
Big-Data Clustering: K-Means or K-Indicators?
Jun 03, 2019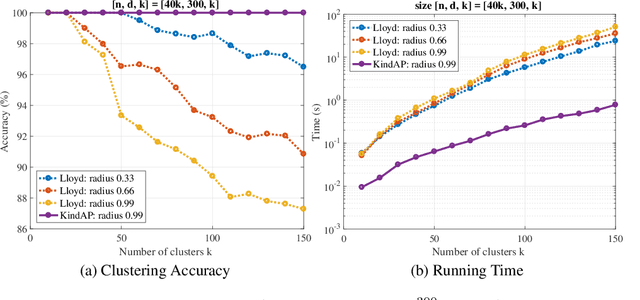
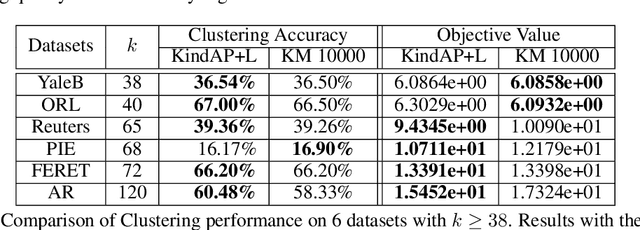
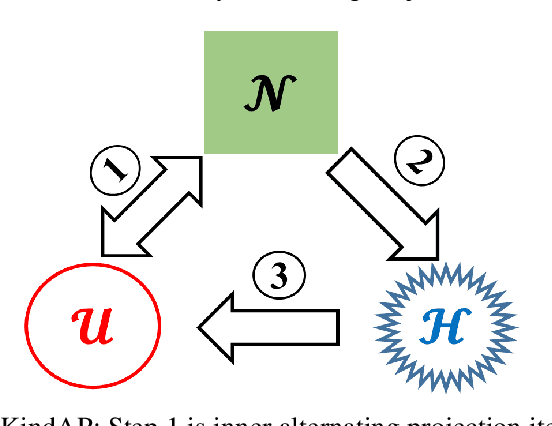
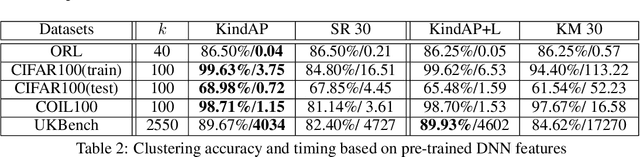
The K-means algorithm is arguably the most popular data clustering method, commonly applied to processed datasets in some "feature spaces", as is in spectral clustering. Highly sensitive to initializations, however, K-means encounters a scalability bottleneck with respect to the number of clusters K as this number grows in big data applications. In this work, we promote a closely related model called K-indicators model and construct an efficient, semi-convex-relaxation algorithm that requires no randomized initializations. We present extensive empirical results to show advantages of the new algorithm when K is large. In particular, using the new algorithm to start the K-means algorithm, without any replication, can significantly outperform the standard K-means with a large number of currently state-of-the-art random replications.
Multi-view Common Component Discriminant Analysis for Cross-view Classification
May 20, 2018


Cross-view classification that means to classify samples from heterogeneous views is a significant yet challenging problem in computer vision. A promising approach to handle this problem is the multi-view subspace learning (MvSL), which intends to find a common subspace for multi-view data. Despite the satisfactory results achieved by existing methods, the performance of previous work will be dramatically degraded when multi-view data lies on nonlinear manifolds. To circumvent this drawback, we propose Multi-view Common Component Discriminant Analysis (MvCCDA) to handle view discrepancy, discriminability and nonlinearity in a joint manner. Specifically, our MvCCDA incorporates supervised information and local geometric information into the common component extraction process to learn a discriminant common subspace and to discover the nonlinear structure embedded in multi-view data. We develop a kernel method of MvCCDA to further boost the performance of MvCCDA. Beyond kernel extension, optimization and complexity analysis of MvCCDA are also presented for completeness. Our MvCCDA is competitive with the state-of-the-art MvSL based methods on four benchmark datasets, demonstrating its superiority.