 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Synergistic Learning with Vision-Language Adaption for Low-Resource Biomedical Image Classification
Apr 27, 2026Accurate biomedical image classification under low-resource conditions remains challenging due to limited annotations, subtle inter-class visual differences, and complex disease semantics. While vision--language models offer a promising foundation for mitigating data scarcity, their effective adaptation in biomedical settings is constrained by the need for parameter-efficient tuning alongside fine-grained and semantically consistent representation learning. In this work, we propose Multi-View Synergistic Learning (MVSL), a unified framework that addresses these challenges by jointly considering adaptation paradigms, representation granularity, and disease semantic relationships. MVSL decouples the adaptation of visual and textual encoders to respect their distinct representational characteristics, enabling more stable and effective parameter-efficient fine-tuning. It further introduces multi-granularity contrastive learning to explicitly model both global image semantics and localized lesion-level evidence, improving fine-grained discrimination for visually similar disease categories. In addition, MVSL preserves disease-level semantic structure by incorporating structured supervision derived from large language models, which constrains textual representations at the class level and indirectly regularizes visual embeddings through cross-modal alignment. Together, these components enable more stable cross-modal alignment and improved discrimination under limited supervision. Extensive experiments on $11$ public biomedical datasets spanning $9$ imaging modalities and $10$ anatomical regions demonstrate that MVSL consistently outperforms state-of-the-art methods in few-shot and zero-shot classification settings.
Target-aware Bi-Transformer for Few-shot Segmentation
Sep 18, 2023Traditional semantic segmentation tasks require a large number of labels and are difficult to identify unlearned categories. Few-shot semantic segmentation (FSS) aims to use limited labeled support images to identify the segmentation of new classes of objects, which is very practical in the real world. Previous researches were primarily based on prototypes or correlations. Due to colors, textures, and styles are similar in the same image, we argue that the query image can be regarded as its own support image. In this paper, we proposed the Target-aware Bi-Transformer Network (TBTNet) to equivalent treat of support images and query image. A vigorous Target-aware Transformer Layer (TTL) also be designed to distill correlations and force the model to focus on foreground information. It treats the hypercorrelation as a feature, resulting a significant reduction in the number of feature channels. Benefit from this characteristic, our model is the lightest up to now with only 0.4M learnable parameters. Futhermore, TBTNet converges in only 10% to 25% of the training epochs compared to traditional methods. The excellent performance on standard FSS benchmarks of PASCAL-5i and COCO-20i proves the efficiency of our method. Extensive ablation studies were also carried out to evaluate the effectiveness of Bi-Transformer architecture and TTL.
PFENet++: Boosting Few-shot Semantic Segmentation with the Noise-filtered Context-aware Prior Mask
Sep 28, 2021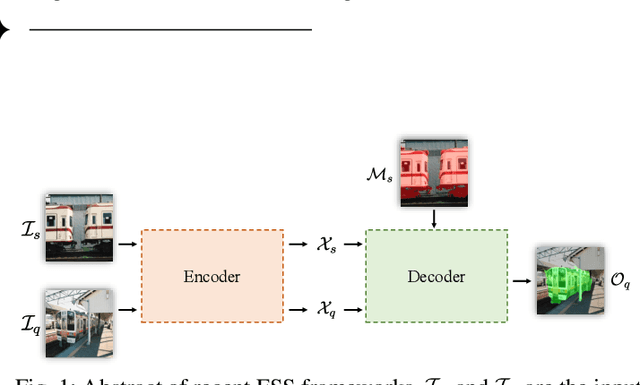



In this work, we revisit the prior mask guidance proposed in "Prior Guided Feature Enrichment Network for Few-Shot Segmentation". The prior mask serves as an indicator that highlights the region of interests of unseen categories, and it is effective in achieving better performance on different frameworks of recent studies. However, the current method directly takes the maximum element-to-element correspondence between the query and support features to indicate the probability of belonging to the target class, thus the broader contextual information is seldom exploited during the prior mask generation. To address this issue, first, we propose the Context-aware Prior Mask (CAPM) that leverages additional nearby semantic cues for better locating the objects in query images. Second, since the maximum correlation value is vulnerable to noisy features, we take one step further by incorporating a lightweight Noise Suppression Module (NSM) to screen out the unnecessary responses, yielding high-quality masks for providing the prior knowledge. Both two contributions are experimentally shown to have substantial practical merit, and the new model named PFENet++ significantly outperforms the baseline PFENet as well as all other competitors on three challenging benchmarks PASCAL-5$^i$, COCO-20$^i$ and FSS-1000. The new state-of-the-art performance is achieved without compromising the efficiency, manifesting the potential for being a new strong baseline in few-shot semantic segmentation. Our code will be available at https://github.com/dvlab-research/PFENet++.