 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDLT: A Dataset with Concept Drift and Long-Tailed Distribution for Fine-Grained Visual Categorization
Jun 04, 2023



Data is the foundation for the development of computer vision, and the establishment of datasets plays an important role in advancing the techniques of fine-grained visual categorization~(FGVC). In the existing FGVC datasets used in computer vision, it is generally assumed that each collected instance has fixed characteristics and the distribution of different categories is relatively balanced. In contrast, the real world scenario reveals the fact that the characteristics of instances tend to vary with time and exhibit a long-tailed distribution. Hence, the collected datasets may mislead the optimization of the fine-grained classifiers, resulting in unpleasant performance in real applications. Starting from the real-world conditions and to promote the practical progress of fine-grained visual categorization, we present a Concept Drift and Long-Tailed Distribution dataset. Specifically, the dataset is collected by gathering 11195 images of 250 instances in different species for 47 consecutive months in their natural contexts. The collection process involves dozens of crowd workers for photographing and domain experts for labelling. Extensive baseline experiments using the state-of-the-art fine-grained classification models demonstrate the issues of concept drift and long-tailed distribution existed in the dataset, which require the attention of future researches.
Deep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Sep 26, 2022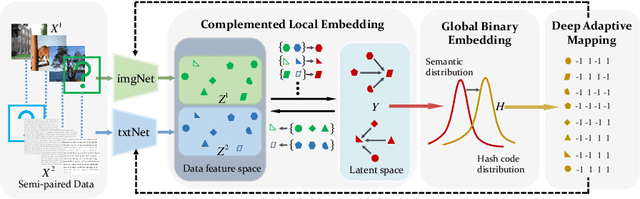

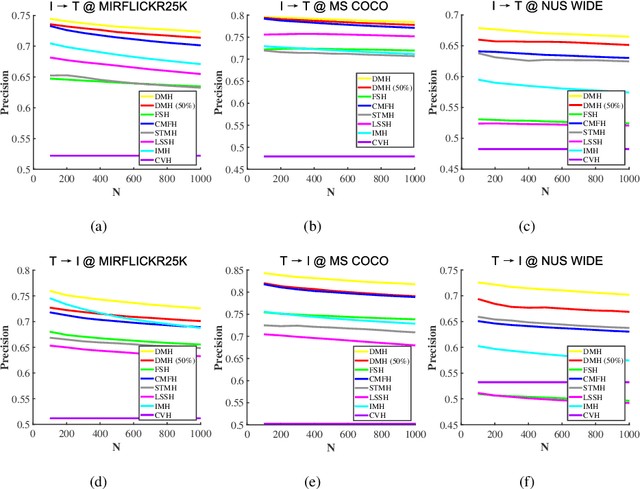

Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.
DCMS: Motion Forecasting with Dual Consistency and Multi-Pseudo-Target Supervision
Apr 12, 2022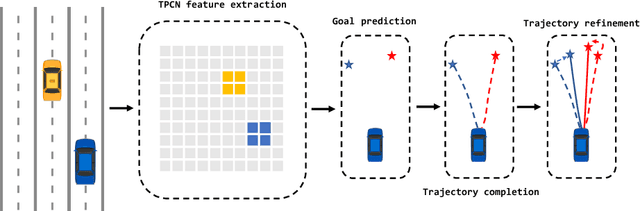
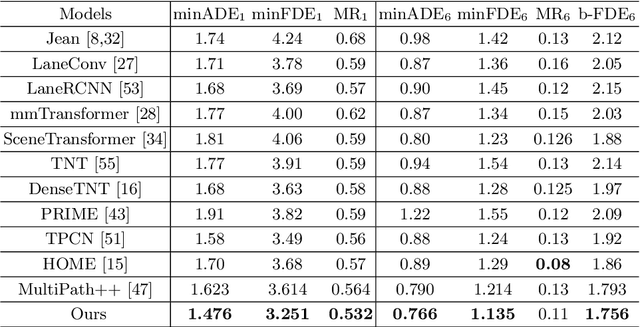
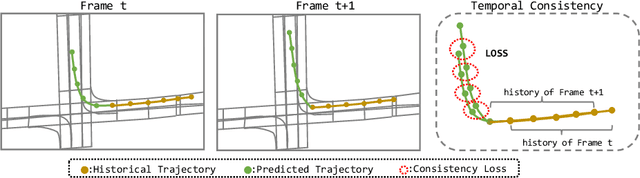
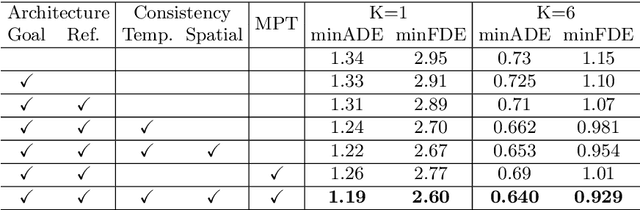
We present a novel framework for motion forecasting with Dual Consistency Constraints and Multi-Pseudo-Target supervision. The motion forecasting task predicts future trajectories of vehicles by incorporating spatial and temporal information from the past. A key design of DCMS is the proposed Dual Consistency Constraints that regularize the predicted trajectories under spatial and temporal perturbation during the training stage. In addition, we design a novel self-ensembling scheme to obtain accurate pseudo targets to model the multi-modality in motion forecasting through supervision with multiple targets explicitly, namely Multi-Pseudo-Target supervision. Our experimental results on the Argoverse motion forecasting benchmark show that DCMS significantly outperforms the state-of-the-art methods, achieving 1st place on the leaderboard. We also demonstrate that our proposed strategies can be incorporated into other motion forecasting approaches as general training schemes.
Modal Regression based Structured Low-rank Matrix Recovery for Multi-view Learning
Mar 22, 2020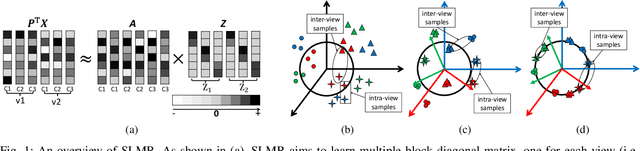
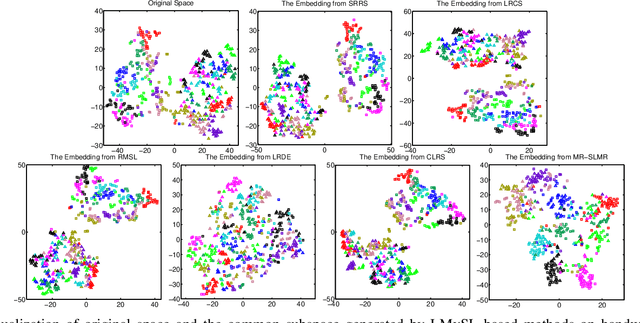

Low-rank Multi-view Subspace Learning (LMvSL) has shown great potential in cross-view classification in recent years. Despite their empirical success, existing LMvSL based methods are incapable of well handling view discrepancy and discriminancy simultaneously, which thus leads to the performance degradation when there is a large discrepancy among multi-view data. To circumvent this drawback, motivated by the block-diagonal representation learning, we propose Structured Low-rank Matrix Recovery (SLMR), a unique method of effectively removing view discrepancy and improving discriminancy through the recovery of structured low-rank matrix. Furthermore, recent low-rank modeling provides a satisfactory solution to address data contaminated by predefined assumptions of noise distribution, such as Gaussian or Laplacian distribution. However, these models are not practical since complicated noise in practice may violate those assumptions and the distribution is generally unknown in advance. To alleviate such limitation, modal regression is elegantly incorporated into the framework of SLMR (term it MR-SLMR). Different from previous LMvSL based methods, our MR-SLMR can handle any zero-mode noise variable that contains a wide range of noise, such as Gaussian noise, random noise and outliers. The alternating direction method of multipliers (ADMM) framework and half-quadratic theory are used to efficiently optimize MR-SLMR. Experimental results on four public databases demonstrate the superiority of MR-SLMR and its robustness to complicated noise.
Robust Visual Tracking using Multi-Frame Multi-Feature Joint Modeling
Nov 19, 2018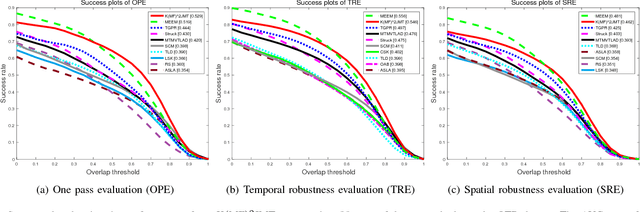
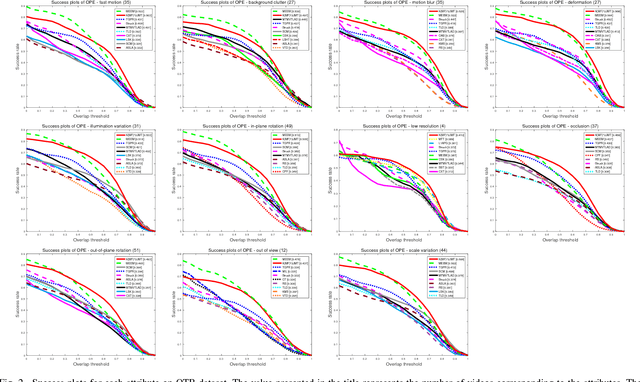
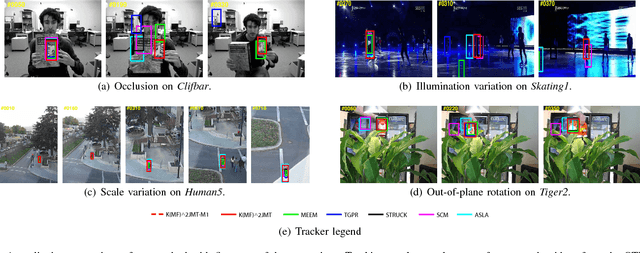
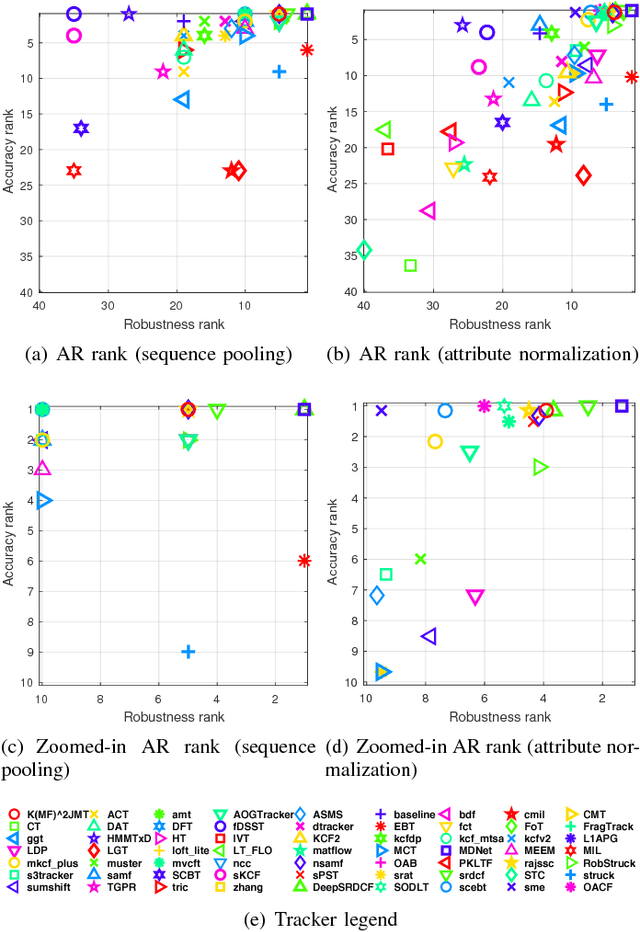
It remains a huge challenge to design effective and efficient trackers under complex scenarios, including occlusions, illumination changes and pose variations. To cope with this problem, a promising solution is to integrate the temporal consistency across consecutive frames and multiple feature cues in a unified model. Motivated by this idea, we propose a novel correlation filter-based tracker in this work, in which the temporal relatedness is reconciled under a multi-task learning framework and the multiple feature cues are modeled using a multi-view learning approach. We demonstrate the resulting regression model can be efficiently learned by exploiting the structure of blockwise diagonal matrix. A fast blockwise diagonal matrix inversion algorithm is developed thereafter for efficient online tracking. Meanwhile, we incorporate an adaptive scale estimation mechanism to strengthen the stability of scale variation tracking. We implement our tracker using two types of features and test it on two benchmark datasets. Experimental results demonstrate the superiority of our proposed approach when compared with other state-of-the-art trackers. project homepage http://bmal.hust.edu.cn/project/KMF2JMTtracking.html
Multi-view Common Component Discriminant Analysis for Cross-view Classification
May 20, 2018


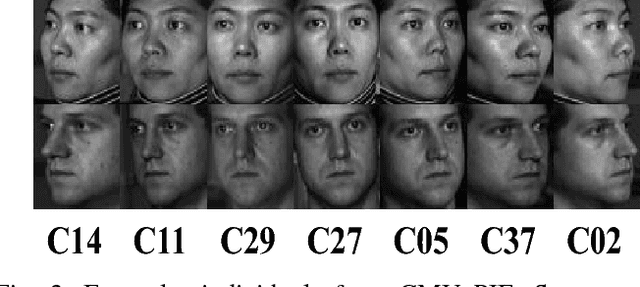
Cross-view classification that means to classify samples from heterogeneous views is a significant yet challenging problem in computer vision. A promising approach to handle this problem is the multi-view subspace learning (MvSL), which intends to find a common subspace for multi-view data. Despite the satisfactory results achieved by existing methods, the performance of previous work will be dramatically degraded when multi-view data lies on nonlinear manifolds. To circumvent this drawback, we propose Multi-view Common Component Discriminant Analysis (MvCCDA) to handle view discrepancy, discriminability and nonlinearity in a joint manner. Specifically, our MvCCDA incorporates supervised information and local geometric information into the common component extraction process to learn a discriminant common subspace and to discover the nonlinear structure embedded in multi-view data. We develop a kernel method of MvCCDA to further boost the performance of MvCCDA. Beyond kernel extension, optimization and complexity analysis of MvCCDA are also presented for completeness. Our MvCCDA is competitive with the state-of-the-art MvSL based methods on four benchmark datasets, demonstrating its superiority.
Multi-view Hybrid Embedding: A Divide-and-Conquer Approach
Apr 19, 2018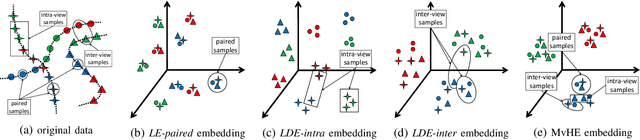
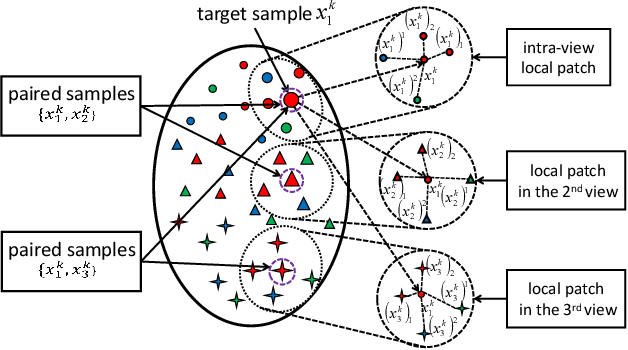
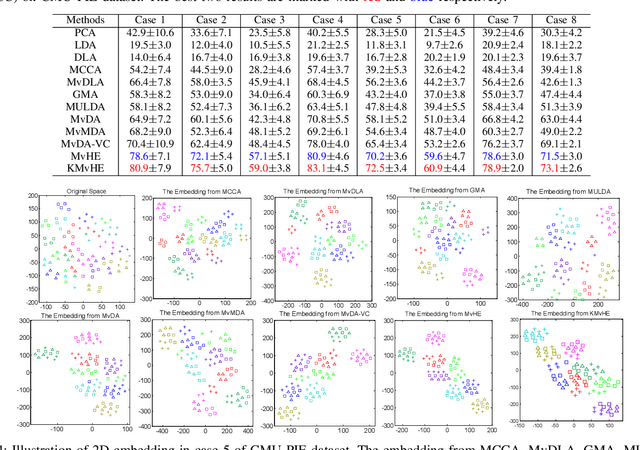
We present a novel cross-view classification algorithm where the gallery and probe data come from different views. A popular approach to tackle this problem is the multi-view subspace learning (MvSL) that aims to learn a latent subspace shared by multi-view data. Despite promising results obtained on some applications, the performance of existing methods deteriorates dramatically when the multi-view data is sampled from nonlinear manifolds or suffers from heavy outliers. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Multi-view Hybrid Embedding (MvHE), a unique method of dividing the problem of cross-view classification into three subproblems and building one model for each subproblem. Specifically, the first model is designed to remove view discrepancy, whereas the second and third models attempt to discover the intrinsic nonlinear structure and to increase discriminability in intra-view and inter-view samples respectively. The kernel extension is conducted to further boost the representation power of MvHE. Extensive experiments are conducted on four benchmark datasets. Our methods demonstrate overwhelming advantages against the state-of-the-art MvSL based cross-view classification approaches in terms of classification accuracy and robustness.