 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Paper and Code
Sep 26, 2022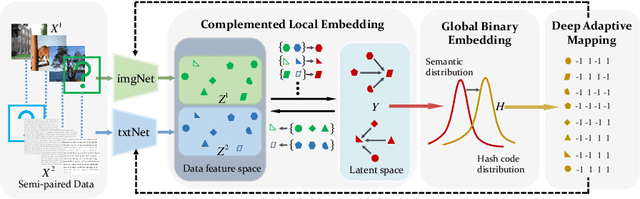

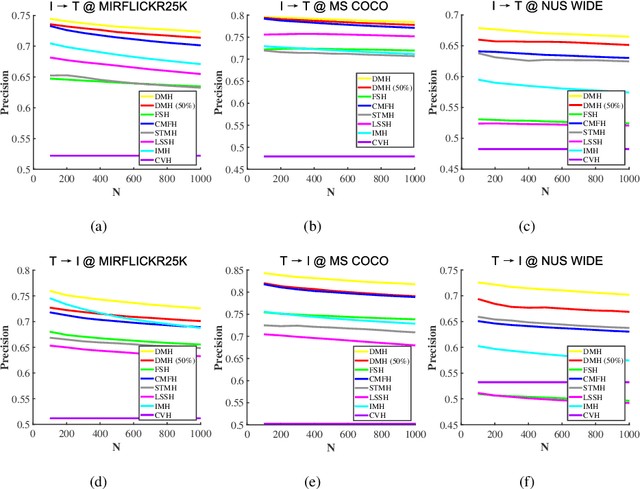

Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.