 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recursive Decomposition Framework for Causal Structure Learning in the Presence of Latent Variables
May 11, 2026Constraint-based causal discovery is widely used for learning causal structures, but heavy reliance on conditional independence (CI) testing makes it computationally expensive in high-dimensional settings. To mitigate this limitation, many divide-and-conquer frameworks have been proposed, but most assume causal sufficiency, i.e., no latent variables. In this paper, we show that divide-and-conquer strategies can be theoretically generalized beyond causal sufficiency to settings with latent variables. Specifically, we propose a recursive decomposition framework, termed DiCoLa, that enables divide-and-conquer causal discovery in the presence of latent variables. It recursively decomposes the global learning task into smaller subproblems and integrates their solutions through a principled reconstruction step to recover the global structure. We theoretically establish the soundness and completeness of the proposed framework. Extensive experiments on synthetic data demonstrate that our approach significantly improves computational efficiency across a range of causal discovery algorithms, while experiments on a real-world dataset further illustrate its practical effectiveness.
Multimodal Medical Endoscopic Image Analysis via Progressive Disentangle-aware Contrastive Learning
Aug 23, 2025

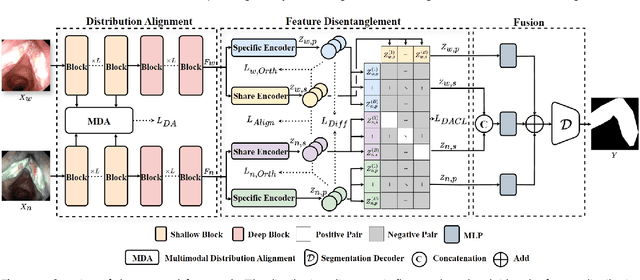

Accurate segmentation of laryngo-pharyngeal tumors is crucial for precise diagnosis and effective treatment planning. However, traditional single-modality imaging methods often fall short of capturing the complex anatomical and pathological features of these tumors. In this study, we present an innovative multi-modality representation learning framework based on the `Align-Disentangle-Fusion' mechanism that seamlessly integrates 2D White Light Imaging (WLI) and Narrow Band Imaging (NBI) pairs to enhance segmentation performance. A cornerstone of our approach is multi-scale distribution alignment, which mitigates modality discrepancies by aligning features across multiple transformer layers. Furthermore, a progressive feature disentanglement strategy is developed with the designed preliminary disentanglement and disentangle-aware contrastive learning to effectively separate modality-specific and shared features, enabling robust multimodal contrastive learning and efficient semantic fusion. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art approaches, achieving superior accuracy across diverse real clinical scenarios.
Prototype Contrastive Consistency Learning for Semi-Supervised Medical Image Segmentation
Feb 10, 2025Medical image segmentation is a crucial task in medical image analysis, but it can be very challenging especially when there are less labeled data but with large unlabeled data. Contrastive learning has proven to be effective for medical image segmentation in semi-supervised learning by constructing contrastive samples from partial pixels. However, although previous contrastive learning methods can mine semantic information from partial pixels within images, they ignore the whole context information of unlabeled images, which is very important to precise segmentation. In order to solve this problem, we propose a novel prototype contrastive learning method called Prototype Contrastive Consistency Segmentation (PCCS) for semi-supervised medical image segmentation. The core idea is to enforce the prototypes of the same semantic class to be closer and push the prototypes in different semantic classes far away from each other. Specifically, we construct a signed distance map and an uncertainty map from unlabeled images. The signed distance map is used to construct prototypes for contrastive learning, and then we estimate the prototype uncertainty from the uncertainty map as trade-off among prototypes. In order to obtain better prototypes, based on the student-teacher architecture, a new mechanism named prototype updating prototype is designed to assist in updating the prototypes for contrastive learning. In addition, we propose an uncertainty-consistency loss to mine more reliable information from unlabeled data. Extensive experiments on medical image segmentation demonstrate that PCCS achieves better segmentation performance than the state-of-the-art methods. The code is available at https://github.com/comphsh/PCCS.
EGP3D: Edge-guided Geometric Preserving 3D Point Cloud Super-resolution for RGB-D camera
Dec 16, 2024



Point clouds or depth images captured by current RGB-D cameras often suffer from low resolution, rendering them insufficient for applications such as 3D reconstruction and robots. Existing point cloud super-resolution (PCSR) methods are either constrained by geometric artifacts or lack attention to edge details. To address these issues, we propose an edge-guided geometric-preserving 3D point cloud super-resolution (EGP3D) method tailored for RGB-D cameras. Our approach innovatively optimizes the point cloud with an edge constraint on a projected 2D space, thereby ensuring high-quality edge preservation in the 3D PCSR task. To tackle geometric optimization challenges in super-resolution point clouds, particularly preserving edge shapes and smoothness, we introduce a multi-faceted loss function that simultaneously optimizes the Chamfer distance, Hausdorff distance, and gradient smoothness. Existing datasets used for point cloud upsampling are predominantly synthetic and inadequately represent real-world scenarios, neglecting noise and stray light effects. To address the scarcity of realistic RGB-D data for PCSR tasks, we built a dataset that captures real-world noise and stray-light effects, offering a more accurate representation of authentic environments. Validated through simulations and real-world experiments, the proposed method exhibited superior performance in preserving edge clarity and geometric details.
LoCo: Low-Contrast-Enhanced Contrastive Learning for Semi-Supervised Endoscopic Image Segmentation
Dec 03, 2024The segmentation of endoscopic images plays a vital role in computer-aided diagnosis and treatment. The advancements in deep learning have led to the employment of numerous models for endoscopic tumor segmentation, achieving promising segmentation performance. Despite recent advancements, precise segmentation remains challenging due to limited annotations and the issue of low contrast. To address these issues, we propose a novel semi-supervised segmentation framework termed LoCo via low-contrast-enhanced contrastive learning (LCC). This innovative approach effectively harnesses the vast amounts of unlabeled data available for endoscopic image segmentation, improving both accuracy and robustness in the segmentation process. Specifically, LCC incorporates two advanced strategies to enhance the distinctiveness of low-contrast pixels: inter-class contrast enhancement (ICE) and boundary contrast enhancement (BCE), enabling models to segment low-contrast pixels among malignant tumors, benign tumors, and normal tissues. Additionally, a confidence-based dynamic filter (CDF) is designed for pseudo-label selection, enhancing the utilization of generated pseudo-labels for unlabeled data with a specific focus on minority classes. Extensive experiments conducted on two public datasets, as well as a large proprietary dataset collected over three years, demonstrate that LoCo achieves state-of-the-art results, significantly outperforming previous methods. The source code of LoCo is available at the URL of https://github.com/AnoK3111/LoCo.
Causality-inspired Latent Feature Augmentation for Single Domain Generalization
Jun 10, 2024Single domain generalization (Single-DG) intends to develop a generalizable model with only one single training domain to perform well on other unknown target domains. Under the domain-hungry configuration, how to expand the coverage of source domain and find intrinsic causal features across different distributions is the key to enhancing the models' generalization ability. Existing methods mainly depend on the meticulous design of finite image-level transformation techniques and learning invariant features across domains based on statistical correlation between samples and labels in source domain. This makes it difficult to capture stable semantics between source and target domains, which hinders the improvement of the model's generalization performance. In this paper, we propose a novel causality-inspired latent feature augmentation method for Single-DG by learning the meta-knowledge of feature-level transformation based on causal learning and interventions. Instead of strongly relying on the finite image-level transformation, with the learned meta-knowledge, we can generate diverse implicit feature-level transformations in latent space based on the consistency of causal features and diversity of non-causal features, which can better compensate for the domain-hungry defect and reduce the strong reliance on initial finite image-level transformations and capture more stable domain-invariant causal features for generalization. Extensive experiments on several open-access benchmarks demonstrate the outstanding performance of our model over other state-of-the-art single domain generalization and also multi-source domain generalization methods.
Mitigating Label Noise on Graph via Topological Sample Selection
Mar 04, 2024
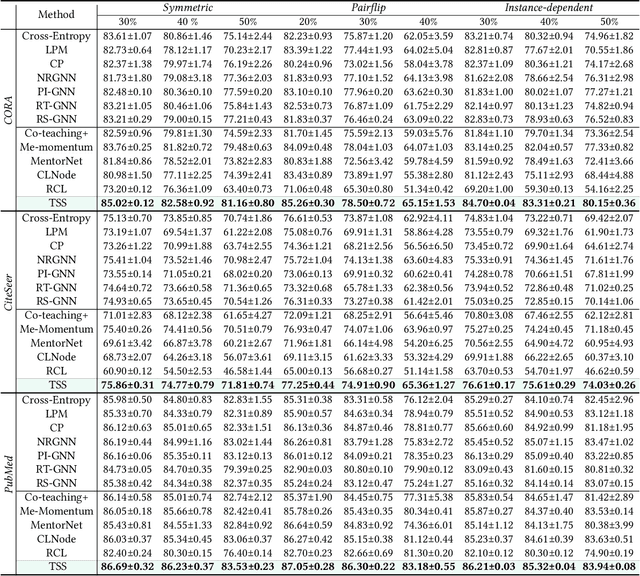


Despite the success of the carefully-annotated benchmarks, the effectiveness of existing graph neural networks (GNNs) can be considerably impaired in practice when the real-world graph data is noisily labeled. Previous explorations in sample selection have been demonstrated as an effective way for robust learning with noisy labels, however, the conventional studies focus on i.i.d data, and when moving to non-iid graph data and GNNs, two notable challenges remain: (1) nodes located near topological class boundaries are very informative for classification but cannot be successfully distinguished by the heuristic sample selection. (2) there is no available measure that considers the graph topological information to promote sample selection in a graph. To address this dilemma, we propose a $\textit{Topological Sample Selection}$ (TSS) method that boosts the informative sample selection process in a graph by utilising topological information. We theoretically prove that our procedure minimizes an upper bound of the expected risk under target clean distribution, and experimentally show the superiority of our method compared with state-of-the-art baselines.
DTA: Distribution Transform-based Attack for Query-Limited Scenario
Dec 12, 2023In generating adversarial examples, the conventional black-box attack methods rely on sufficient feedback from the to-be-attacked models by repeatedly querying until the attack is successful, which usually results in thousands of trials during an attack. This may be unacceptable in real applications since Machine Learning as a Service Platform (MLaaS) usually only returns the final result (i.e., hard-label) to the client and a system equipped with certain defense mechanisms could easily detect malicious queries. By contrast, a feasible way is a hard-label attack that simulates an attacked action being permitted to conduct a limited number of queries. To implement this idea, in this paper, we bypass the dependency on the to-be-attacked model and benefit from the characteristics of the distributions of adversarial examples to reformulate the attack problem in a distribution transform manner and propose a distribution transform-based attack (DTA). DTA builds a statistical mapping from the benign example to its adversarial counterparts by tackling the conditional likelihood under the hard-label black-box settings. In this way, it is no longer necessary to query the target model frequently. A well-trained DTA model can directly and efficiently generate a batch of adversarial examples for a certain input, which can be used to attack un-seen models based on the assumed transferability. Furthermore, we surprisingly find that the well-trained DTA model is not sensitive to the semantic spaces of the training dataset, meaning that the model yields acceptable attack performance on other datasets. Extensive experiments validate the effectiveness of the proposed idea and the superiority of DTA over the state-of-the-art.
Rethinking Radiology Report Generation via Causal Reasoning and Counterfactual Augmentation
Dec 05, 2023



Radiology Report Generation (RRG) draws attention as an interaction between vision and language fields. Previous works inherited the ideology of vision-to-language generation tasks,aiming to generate paragraphs with high consistency as reports. However, one unique characteristic of RRG, the independence between diseases, was neglected, leading to the injection of disease co-occurrence as a confounder that effects the results through backdoor path. Unfortunately, this confounder confuses the process of report generation worse because of the biased RRG data distribution. In this paper, to rethink this issue thoroughly, we reason about its causes and effects from a novel perspective of statistics and causality, where the Joint Vision Coupling and the Conditional Sentence Coherence Coupling are two aspects prone to implicitly decrease the accuracy of reports. Then, a counterfactual augmentation strategy that contains the Counterfactual Sample Synthesis and the Counterfactual Report Reconstruction sub-methods is proposed to break these two aspects of spurious effects. Experimental results and further analyses on two widely used datasets justify our reasoning and proposed methods.
CDLT: A Dataset with Concept Drift and Long-Tailed Distribution for Fine-Grained Visual Categorization
Jun 04, 2023



Data is the foundation for the development of computer vision, and the establishment of datasets plays an important role in advancing the techniques of fine-grained visual categorization~(FGVC). In the existing FGVC datasets used in computer vision, it is generally assumed that each collected instance has fixed characteristics and the distribution of different categories is relatively balanced. In contrast, the real world scenario reveals the fact that the characteristics of instances tend to vary with time and exhibit a long-tailed distribution. Hence, the collected datasets may mislead the optimization of the fine-grained classifiers, resulting in unpleasant performance in real applications. Starting from the real-world conditions and to promote the practical progress of fine-grained visual categorization, we present a Concept Drift and Long-Tailed Distribution dataset. Specifically, the dataset is collected by gathering 11195 images of 250 instances in different species for 47 consecutive months in their natural contexts. The collection process involves dozens of crowd workers for photographing and domain experts for labelling. Extensive baseline experiments using the state-of-the-art fine-grained classification models demonstrate the issues of concept drift and long-tailed distribution existed in the dataset, which require the attention of future researches.