 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification
Apr 14, 2026Recent Audio-Visual Question Answering (AVQA) methods have advanced significantly. However, most AVQA methods lack effective mechanisms for handling missing modalities, suffering from severe performance degradation in real-world scenarios with data interruptions. Furthermore, prevailing methods for handling missing modalities predominantly rely on generative imputation to synthesize missing features. While partially effective, these methods tend to capture inter-modal commonalities but struggle to acquire unique, modality-specific knowledge within the missing data, leading to hallucinations and compromised reasoning accuracy. To tackle these challenges, we propose R$^{2}$ScP, a novel framework that shifts the paradigm of missing modality handling from traditional generative imputation to retrieval-based recovery. Specifically, we leverage cross-modal retrieval via unified semantic embeddings to acquire missing domain-specific knowledge. To maximize semantic restoration, we introduce a context-aware adaptive purification mechanism that eliminates latent semantic noise within the retrieved data. Additionally, we employ a two-stage training strategy to explicitly model the semantic relationships between knowledge from different sources. Extensive experiments demonstrate that R$^{2}$ScP significantly improves AVQA and enhances robustness in modal-incomplete scenarios.
YUV20K: A Complexity-Driven Benchmark and Trajectory-Aware Alignment Model for Video Camouflaged Object Detection
Apr 11, 2026Video Camouflaged Object Detection (VCOD) is currently constrained by the scarcity of challenging benchmarks and the limited robustness of models against erratic motion dynamics. Existing methods often struggle with Motion-Induced Appearance Instability and Temporal Feature Misalignment caused by complex motion scenarios. To address the data bottleneck, we present YUV20K, a pixel-level annoated complexity-driven VCOD benchmark. Comprising 24,295 annotated frames across 91 scenes and 47 kinds of species, it specifically targets challenging scenarios like large-displacement motion, camera motion and other 4 types scenarios. On the methodological front, we propose a novel framework featuring two key modules: Motion Feature Stabilization (MFS) and Trajectory-Aware Alignment (TAA). The MFS module utilizes frame-agnostic Semantic Basis Primitives to stablize features, while the TAA module leverages trajectory-guided deformable sampling to ensure precise temporal alignment. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art competitors on existing datasets and establishes a new baseline on the challenging YUV20K. Notably, our framework exhibits superior cross-domain generalization and robustness when confronting complex spatiotemporal scenarios. Our code and dataset will be available at https://github.com/K1NSA/YUV20K
SVC 2026: the Second Multimodal Deception Detection Challenge and the First Domain Generalized Remote Physiological Measurement Challenge
Apr 07, 2026Subtle visual signals, although difficult to perceive with the naked eye, contain important information that can reveal hidden patterns in visual data. These signals play a key role in many applications, including biometric security, multimedia forensics, medical diagnosis, industrial inspection, and affective computing. With the rapid development of computer vision and representation learning techniques, detecting and interpreting such subtle signals has become an emerging research direction. However, existing studies often focus on specific tasks or modalities, and models still face challenges in robustness, representation ability, and generalization when handling subtle and weak signals in real-world environments. To promote research in this area, we organize the Subtle visual Challenge, which aims to learn robust representations for subtle visual signals. The challenge includes two tasks: cross-domain multimodal deception detection and remote photoplethysmography (rPPG) estimation. We hope that this challenge will encourage the development of more robust and generalizable models for subtle visual understanding, and further advance research in computer vision and multimodal learning. A total of 22 teams submitted their final results to this workshop competition, and the corresponding baseline models have been released on the \href{https://sites.google.com/view/svc-cvpr26}{MMDD2026 platform}\footnote{https://sites.google.com/view/svc-cvpr26}
High-Resolution Underwater Camouflaged Object Detection: GBU-UCOD Dataset and Topology-Aware and Frequency-Decoupled Networks
Feb 03, 2026Underwater Camouflaged Object Detection (UCOD) is a challenging task due to the extreme visual similarity between targets and backgrounds across varying marine depths. Existing methods often struggle with topological fragmentation of slender creatures in the deep sea and the subtle feature extraction of transparent organisms. In this paper, we propose DeepTopo-Net, a novel framework that integrates topology-aware modeling with frequency-decoupled perception. To address physical degradation, we design the Water-Conditioned Adaptive Perceptor (WCAP), which employs Riemannian metric tensors to dynamically deform convolutional sampling fields. Furthermore, the Abyssal-Topology Refinement Module (ATRM) is developed to maintain the structural connectivity of spindly targets through skeletal priors. Specifically, we first introduce GBU-UCOD, the first high-resolution (2K) benchmark tailored for marine vertical zonation, filling the data gap for hadal and abyssal zones. Extensive experiments on MAS3K, RMAS, and our proposed GBU-UCOD datasets demonstrate that DeepTopo-Net achieves state-of-the-art performance, particularly in preserving the morphological integrity of complex underwater patterns. The datasets and codes will be released at https://github.com/Wuwenji18/GBU-UCOD.
Spec-o3: A Tool-Augmented Vision-Language Agent for Rare Celestial Object Candidate Vetting via Automated Spectral Inspection
Jan 10, 2026Due to the limited generalization and interpretability of deep learning classifiers, The final vetting of rare celestial object candidates still relies on expert visual inspection--a manually intensive process. In this process, astronomers leverage specialized tools to analyze spectra and construct reliable catalogs. However, this practice has become the primary bottleneck, as it is fundamentally incapable of scaling with the data deluge from modern spectroscopic surveys. To bridge this gap, we propose Spec-o3, a tool-augmented vision-language agent that performs astronomer-aligned spectral inspection via interleaved multimodal chain-of-thought reasoning. Spec-o3 is trained with a two-stage post-training recipe: cold-start supervised fine-tuning on expert inspection trajectories followed by outcome-based reinforcement learning on rare-type verification tasks. Evaluated on five rare-object identification tasks from LAMOST, Spec-o3 establishes a new State-of-the-Art, boosting the macro-F1 score from 28.3 to 76.5 with a 7B parameter base model and outperforming both proprietary VLMs and specialized deep models. Crucially, the agent demonstrates strong generalization to unseen inspection tasks across survey shifts (from LAMOST to SDSS/DESI). Expert evaluations confirm that its reasoning traces are coherent and physically consistent, supporting transparent and trustworthy decision-making. Code, data, and models are available at \href{https://github.com/Maxwell-Jia/spec-o3}{Project HomePage}.
HRR: Hierarchical Retrospection Refinement for Generated Image Detection
Feb 25, 2025



Generative artificial intelligence holds significant potential for abuse, and generative image detection has become a key focus of research. However, existing methods primarily focused on detecting a specific generative model and emphasizing the localization of synthetic regions, while neglecting the interference caused by image size and style on model learning. Our goal is to reach a fundamental conclusion: Is the image real or generated? To this end, we propose a diffusion model-based generative image detection framework termed Hierarchical Retrospection Refinement~(HRR). It designs a multi-scale style retrospection module that encourages the model to generate detailed and realistic multi-scale representations, while alleviating the learning biases introduced by dataset styles and generative models. Additionally, based on the principle of correntropy sparse additive machine, a feature refinement module is designed to reduce the impact of redundant features on learning and capture the intrinsic structure and patterns of the data, thereby improving the model's generalization ability. Extensive experiments demonstrate the HRR framework consistently delivers significant performance improvements, outperforming state-of-the-art methods in generated image detection task.
Toward Realistic Camouflaged Object Detection: Benchmarks and Method
Jan 13, 2025



Camouflaged object detection (COD) primarily relies on semantic or instance segmentation methods. While these methods have made significant advancements in identifying the contours of camouflaged objects, they may be inefficient or cost-effective for tasks that only require the specific location of the object. Object detection algorithms offer an optimized solution for Realistic Camouflaged Object Detection (RCOD) in such cases. However, detecting camouflaged objects remains a formidable challenge due to the high degree of similarity between the features of the objects and their backgrounds. Unlike segmentation methods that perform pixel-wise comparisons to differentiate between foreground and background, object detectors omit this analysis, further aggravating the challenge. To solve this problem, we propose a camouflage-aware feature refinement (CAFR) strategy. Since camouflaged objects are not rare categories, CAFR fully utilizes a clear perception of the current object within the prior knowledge of large models to assist detectors in deeply understanding the distinctions between background and foreground. Specifically, in CAFR, we introduce the Adaptive Gradient Propagation (AGP) module that fine-tunes all feature extractor layers in large detection models to fully refine class-specific features from camouflaged contexts. We then design the Sparse Feature Refinement (SFR) module that optimizes the transformer-based feature extractor to focus primarily on capturing class-specific features in camouflaged scenarios. To facilitate the assessment of RCOD tasks, we manually annotate the labels required for detection on three existing segmentation COD datasets, creating a new benchmark for RCOD tasks. Code and datasets are available at: https://github.com/zhimengXin/RCOD.
Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Sep 15, 2023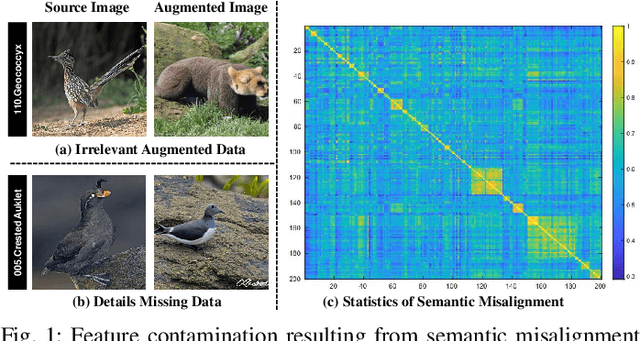
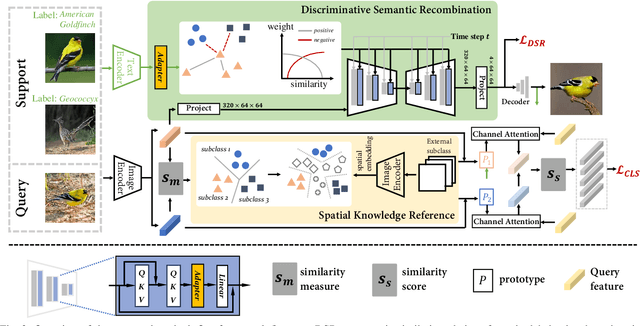
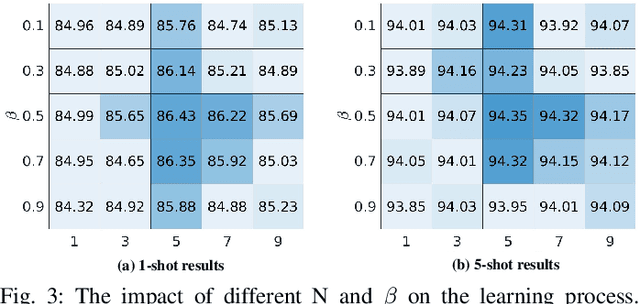

The challenge in fine-grained visual categorization lies in how to explore the subtle differences between different subclasses and achieve accurate discrimination. Previous research has relied on large-scale annotated data and pre-trained deep models to achieve the objective. However, when only a limited amount of samples is available, similar methods may become less effective. Diffusion models have been widely adopted in data augmentation due to their outstanding diversity in data generation. However, the high level of detail required for fine-grained images makes it challenging for existing methods to be directly employed. To address this issue, we propose a novel approach termed the detail reinforcement diffusion model~(DRDM), which leverages the rich knowledge of large models for fine-grained data augmentation and comprises two key components including discriminative semantic recombination (DSR) and spatial knowledge reference~(SKR). Specifically, DSR is designed to extract implicit similarity relationships from the labels and reconstruct the semantic mapping between labels and instances, which enables better discrimination of subtle differences between different subclasses. Furthermore, we introduce the SKR module, which incorporates the distributions of different datasets as references in the feature space. This allows the SKR to aggregate the high-dimensional distribution of subclass features in few-shot FGVC tasks, thus expanding the decision boundary. Through these two critical components, we effectively utilize the knowledge from large models to address the issue of data scarcity, resulting in improved performance for fine-grained visual recognition tasks. Extensive experiments demonstrate the consistent performance gain offered by our DRDM.
Coping with Change: Learning Invariant and Minimum Sufficient Representations for Fine-Grained Visual Categorization
Jun 08, 2023Fine-grained visual categorization (FGVC) is a challenging task due to similar visual appearances between various species. Previous studies always implicitly assume that the training and test data have the same underlying distributions, and that features extracted by modern backbone architectures remain discriminative and generalize well to unseen test data. However, we empirically justify that these conditions are not always true on benchmark datasets. To this end, we combine the merits of invariant risk minimization (IRM) and information bottleneck (IB) principle to learn invariant and minimum sufficient (IMS) representations for FGVC, such that the overall model can always discover the most succinct and consistent fine-grained features. We apply the matrix-based R{\'e}nyi's $\alpha$-order entropy to simplify and stabilize the training of IB; we also design a ``soft" environment partition scheme to make IRM applicable to FGVC task. To the best of our knowledge, we are the first to address the problem of FGVC from a generalization perspective and develop a new information-theoretic solution accordingly. Extensive experiments demonstrate the consistent performance gain offered by our IMS.
CDLT: A Dataset with Concept Drift and Long-Tailed Distribution for Fine-Grained Visual Categorization
Jun 04, 2023



Data is the foundation for the development of computer vision, and the establishment of datasets plays an important role in advancing the techniques of fine-grained visual categorization~(FGVC). In the existing FGVC datasets used in computer vision, it is generally assumed that each collected instance has fixed characteristics and the distribution of different categories is relatively balanced. In contrast, the real world scenario reveals the fact that the characteristics of instances tend to vary with time and exhibit a long-tailed distribution. Hence, the collected datasets may mislead the optimization of the fine-grained classifiers, resulting in unpleasant performance in real applications. Starting from the real-world conditions and to promote the practical progress of fine-grained visual categorization, we present a Concept Drift and Long-Tailed Distribution dataset. Specifically, the dataset is collected by gathering 11195 images of 250 instances in different species for 47 consecutive months in their natural contexts. The collection process involves dozens of crowd workers for photographing and domain experts for labelling. Extensive baseline experiments using the state-of-the-art fine-grained classification models demonstrate the issues of concept drift and long-tailed distribution existed in the dataset, which require the attention of future researches.