 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Realistic Camouflaged Object Detection: Benchmarks and Method
Jan 13, 2025



Camouflaged object detection (COD) primarily relies on semantic or instance segmentation methods. While these methods have made significant advancements in identifying the contours of camouflaged objects, they may be inefficient or cost-effective for tasks that only require the specific location of the object. Object detection algorithms offer an optimized solution for Realistic Camouflaged Object Detection (RCOD) in such cases. However, detecting camouflaged objects remains a formidable challenge due to the high degree of similarity between the features of the objects and their backgrounds. Unlike segmentation methods that perform pixel-wise comparisons to differentiate between foreground and background, object detectors omit this analysis, further aggravating the challenge. To solve this problem, we propose a camouflage-aware feature refinement (CAFR) strategy. Since camouflaged objects are not rare categories, CAFR fully utilizes a clear perception of the current object within the prior knowledge of large models to assist detectors in deeply understanding the distinctions between background and foreground. Specifically, in CAFR, we introduce the Adaptive Gradient Propagation (AGP) module that fine-tunes all feature extractor layers in large detection models to fully refine class-specific features from camouflaged contexts. We then design the Sparse Feature Refinement (SFR) module that optimizes the transformer-based feature extractor to focus primarily on capturing class-specific features in camouflaged scenarios. To facilitate the assessment of RCOD tasks, we manually annotate the labels required for detection on three existing segmentation COD datasets, creating a new benchmark for RCOD tasks. Code and datasets are available at: https://github.com/zhimengXin/RCOD.
Few-Shot Object Detection: Research Advances and Challenges
Apr 07, 2024



Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
ECEA: Extensible Co-Existing Attention for Few-Shot Object Detection
Sep 15, 2023
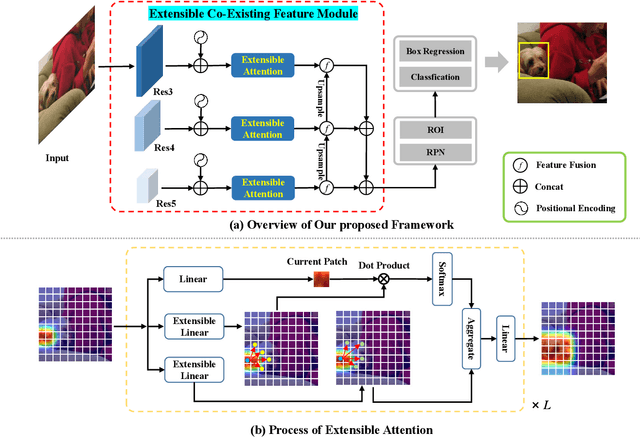
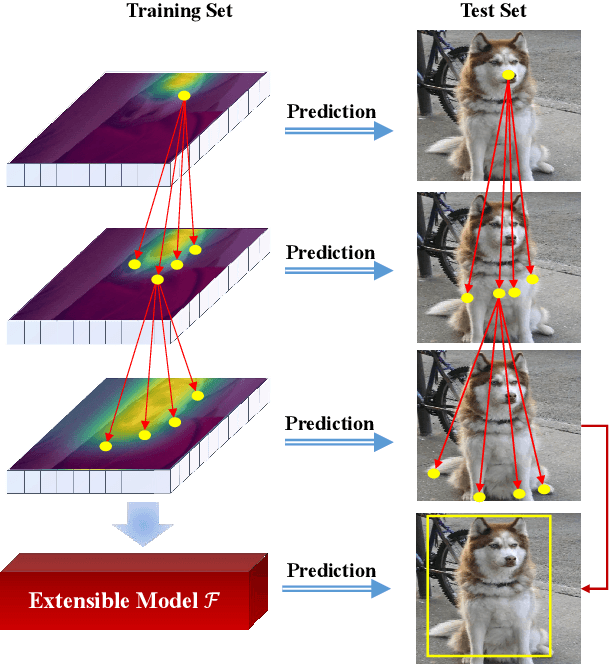
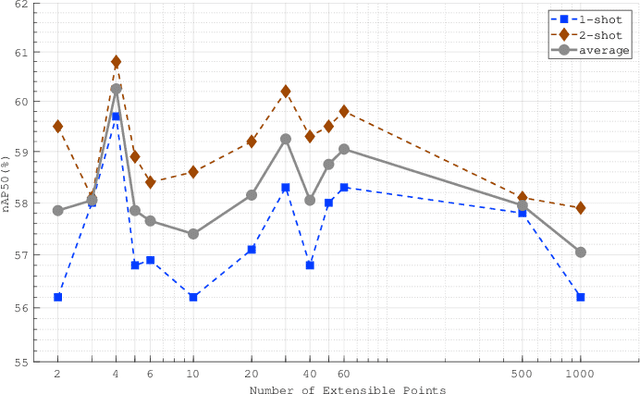
Few-shot object detection (FSOD) identifies objects from extremely few annotated samples. Most existing FSOD methods, recently, apply the two-stage learning paradigm, which transfers the knowledge learned from abundant base classes to assist the few-shot detectors by learning the global features. However, such existing FSOD approaches seldom consider the localization of objects from local to global. Limited by the scarce training data in FSOD, the training samples of novel classes typically capture part of objects, resulting in such FSOD methods cannot detect the completely unseen object during testing. To tackle this problem, we propose an Extensible Co-Existing Attention (ECEA) module to enable the model to infer the global object according to the local parts. Essentially, the proposed module continuously learns the extensible ability on the base stage with abundant samples and transfers it to the novel stage, which can assist the few-shot model to quickly adapt in extending local regions to co-existing regions. Specifically, we first devise an extensible attention mechanism that starts with a local region and extends attention to co-existing regions that are similar and adjacent to the given local region. We then implement the extensible attention mechanism in different feature scales to progressively discover the full object in various receptive fields. Extensive experiments on the PASCAL VOC and COCO datasets show that our ECEA module can assist the few-shot detector to completely predict the object despite some regions failing to appear in the training samples and achieve the new state of the art compared with existing FSOD methods.
Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Sep 15, 2023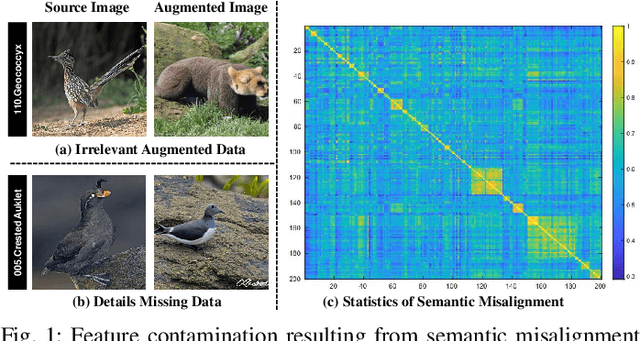
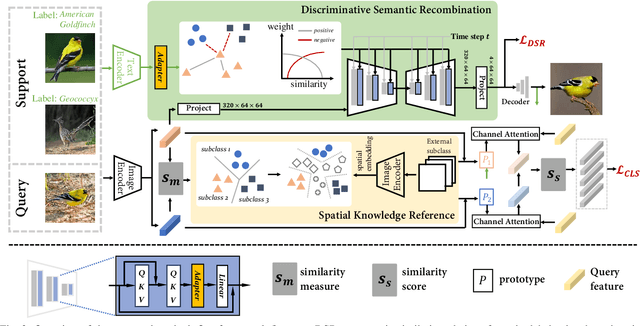
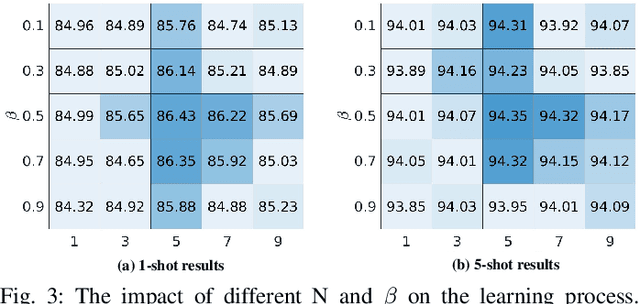

The challenge in fine-grained visual categorization lies in how to explore the subtle differences between different subclasses and achieve accurate discrimination. Previous research has relied on large-scale annotated data and pre-trained deep models to achieve the objective. However, when only a limited amount of samples is available, similar methods may become less effective. Diffusion models have been widely adopted in data augmentation due to their outstanding diversity in data generation. However, the high level of detail required for fine-grained images makes it challenging for existing methods to be directly employed. To address this issue, we propose a novel approach termed the detail reinforcement diffusion model~(DRDM), which leverages the rich knowledge of large models for fine-grained data augmentation and comprises two key components including discriminative semantic recombination (DSR) and spatial knowledge reference~(SKR). Specifically, DSR is designed to extract implicit similarity relationships from the labels and reconstruct the semantic mapping between labels and instances, which enables better discrimination of subtle differences between different subclasses. Furthermore, we introduce the SKR module, which incorporates the distributions of different datasets as references in the feature space. This allows the SKR to aggregate the high-dimensional distribution of subclass features in few-shot FGVC tasks, thus expanding the decision boundary. Through these two critical components, we effectively utilize the knowledge from large models to address the issue of data scarcity, resulting in improved performance for fine-grained visual recognition tasks. Extensive experiments demonstrate the consistent performance gain offered by our DRDM.