 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFORGE: Multi-modal Attacks Reveal Vulnerable Concept Unlearning in Image Generation Models
Mar 17, 2026Recent progress in image generation models (IGMs) enables high-fidelity content creation but also amplifies risks, including the reproduction of copyrighted content and the generation of offensive content. Image Generation Model Unlearning (IGMU) mitigates these risks by removing harmful concepts without full retraining. Despite growing attention, the robustness under adversarial inputs, particularly image-side threats in black-box settings, remains underexplored. To bridge this gap, we present REFORGE, a black-box red-teaming framework that evaluates IGMU robustness via adversarial image prompts. REFORGE initializes stroke-based images and optimizes perturbations with a cross-attention-guided masking strategy that allocates noise to concept-relevant regions, balancing attack efficacy and visual fidelity. Extensive experiments across representative unlearning tasks and defenses demonstrate that REFORGE significantly improves attack success rate while achieving stronger semantic alignment and higher efficiency than involved baselines. These results expose persistent vulnerabilities in current IGMU methods and highlight the need for robustness-aware unlearning against multi-modal adversarial attacks. Our code is at: https://github.com/Imfatnoily/REFORGE.
PWAVEP: Purifying Imperceptible Adversarial Perturbations in 3D Point Clouds via Spectral Graph Wavelets
Feb 03, 2026Recent progress in adversarial attacks on 3D point clouds, particularly in achieving spatial imperceptibility and high attack performance, presents significant challenges for defenders. Current defensive approaches remain cumbersome, often requiring invasive model modifications, expensive training procedures or auxiliary data access. To address these threats, in this paper, we propose a plug-and-play and non-invasive defense mechanism in the spectral domain, grounded in a theoretical and empirical analysis of the relationship between imperceptible perturbations and high-frequency spectral components. Building upon these insights, we introduce a novel purification framework, termed PWAVEP, which begins by computing a spectral graph wavelet domain saliency score and local sparsity score for each point. Guided by these values, PWAVEP adopts a hierarchical strategy, it eliminates the most salient points, which are identified as hardly recoverable adversarial outliers. Simultaneously, it applies a spectral filtering process to a broader set of moderately salient points. This process leverages a graph wavelet transform to attenuate high-frequency coefficients associated with the targeted points, thereby effectively suppressing adversarial noise. Extensive evaluations demonstrate that the proposed PWAVEP achieves superior accuracy and robustness compared to existing approaches, advancing the state-of-the-art in 3D point cloud purification. Code and datasets are available at https://github.com/a772316182/pwavep
SafeRedir: Prompt Embedding Redirection for Robust Unlearning in Image Generation Models
Jan 13, 2026Image generation models (IGMs), while capable of producing impressive and creative content, often memorize a wide range of undesirable concepts from their training data, leading to the reproduction of unsafe content such as NSFW imagery and copyrighted artistic styles. Such behaviors pose persistent safety and compliance risks in real-world deployments and cannot be reliably mitigated by post-hoc filtering, owing to the limited robustness of such mechanisms and a lack of fine-grained semantic control. Recent unlearning methods seek to erase harmful concepts at the model level, which exhibit the limitations of requiring costly retraining, degrading the quality of benign generations, or failing to withstand prompt paraphrasing and adversarial attacks. To address these challenges, we introduce SafeRedir, a lightweight inference-time framework for robust unlearning via prompt embedding redirection. Without modifying the underlying IGMs, SafeRedir adaptively routes unsafe prompts toward safe semantic regions through token-level interventions in the embedding space. The framework comprises two core components: a latent-aware multi-modal safety classifier for identifying unsafe generation trajectories, and a token-level delta generator for precise semantic redirection, equipped with auxiliary predictors for token masking and adaptive scaling to localize and regulate the intervention. Empirical results across multiple representative unlearning tasks demonstrate that SafeRedir achieves effective unlearning capability, high semantic and perceptual preservation, robust image quality, and enhanced resistance to adversarial attacks. Furthermore, SafeRedir generalizes effectively across a variety of diffusion backbones and existing unlearned models, validating its plug-and-play compatibility and broad applicability. Code and data are available at https://github.com/ryliu68/SafeRedir.
FactGuard: Event-Centric and Commonsense-Guided Fake News Detection
Nov 13, 2025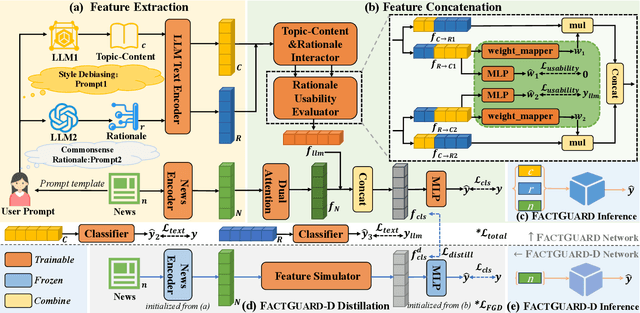
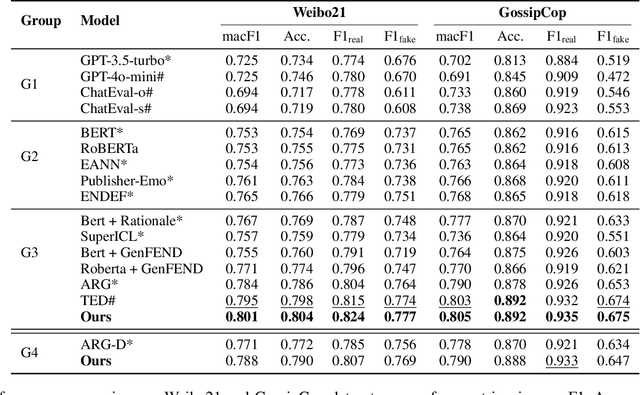
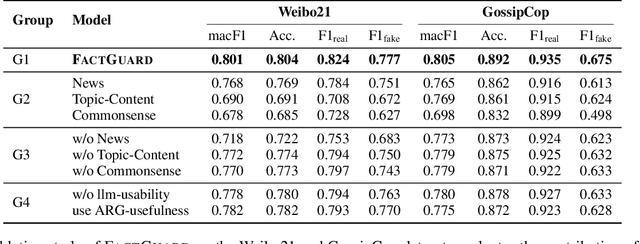
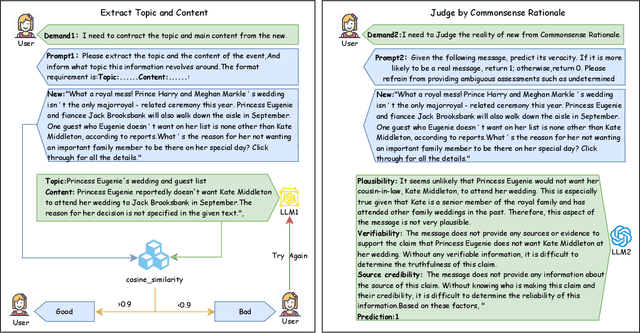
Fake news detection methods based on writing style have achieved remarkable progress. However, as adversaries increasingly imitate the style of authentic news, the effectiveness of such approaches is gradually diminishing. Recent research has explored incorporating large language models (LLMs) to enhance fake news detection. Yet, despite their transformative potential, LLMs remain an untapped goldmine for fake news detection, with their real-world adoption hampered by shallow functionality exploration, ambiguous usability, and prohibitive inference costs. In this paper, we propose a novel fake news detection framework, dubbed FactGuard, that leverages LLMs to extract event-centric content, thereby reducing the impact of writing style on detection performance. Furthermore, our approach introduces a dynamic usability mechanism that identifies contradictions and ambiguous cases in factual reasoning, adaptively incorporating LLM advice to improve decision reliability. To ensure efficiency and practical deployment, we employ knowledge distillation to derive FactGuard-D, enabling the framework to operate effectively in cold-start and resource-constrained scenarios. Comprehensive experiments on two benchmark datasets demonstrate that our approach consistently outperforms existing methods in both robustness and accuracy, effectively addressing the challenges of style sensitivity and LLM usability in fake news detection.
ANID: How Far Are We? Evaluating the Discrepancies Between AI-synthesized Images and Natural Images through Multimodal Guidance
Dec 23, 2024In the rapidly evolving field of Artificial Intelligence Generated Content (AIGC), one of the key challenges is distinguishing AI-synthesized images from natural images. Despite the remarkable capabilities of advanced AI generative models in producing visually compelling images, significant discrepancies remain when these images are compared to natural ones. To systematically investigate and quantify these discrepancies, we introduce an AI-Natural Image Discrepancy Evaluation benchmark aimed at addressing the critical question: \textit{how far are AI-generated images (AIGIs) from truly realistic images?} We have constructed a large-scale multimodal dataset, the Distinguishing Natural and AI-generated Images (DNAI) dataset, which includes over 440,000 AIGI samples generated by 8 representative models using both unimodal and multimodal prompts, such as Text-to-Image (T2I), Image-to-Image (I2I), and Text \textit{vs.} Image-to-Image (TI2I). Our fine-grained assessment framework provides a comprehensive evaluation of the DNAI dataset across five key dimensions: naive visual feature quality, semantic alignment in multimodal generation, aesthetic appeal, downstream task applicability, and coordinated human validation. Extensive evaluation results highlight significant discrepancies across these dimensions, underscoring the necessity of aligning quantitative metrics with human judgment to achieve a holistic understanding of AI-generated image quality. Code is available at \href{https://github.com/ryliu68/ANID}{https://github.com/ryliu68/ANID}.
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024



Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.
SSTA: Salient Spatially Transformed Attack
Dec 12, 2023
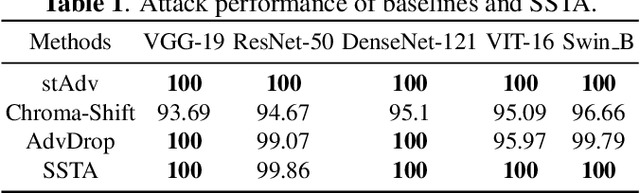

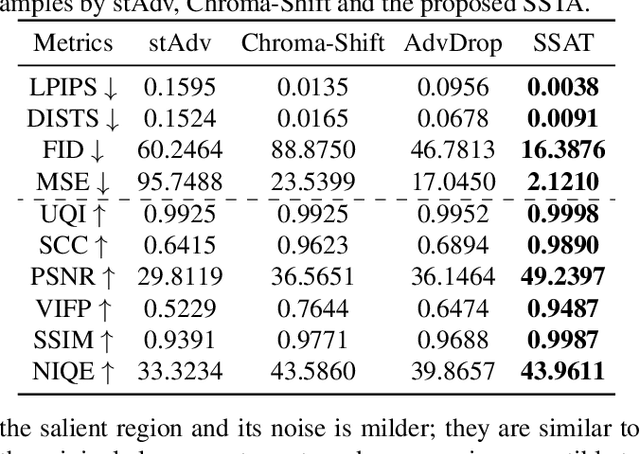
Extensive studies have demonstrated that deep neural networks (DNNs) are vulnerable to adversarial attacks, which brings a huge security risk to the further application of DNNs, especially for the AI models developed in the real world. Despite the significant progress that has been made recently, existing attack methods still suffer from the unsatisfactory performance of escaping from being detected by naked human eyes due to the formulation of adversarial example (AE) heavily relying on a noise-adding manner. Such mentioned challenges will significantly increase the risk of exposure and result in an attack to be failed. Therefore, in this paper, we propose the Salient Spatially Transformed Attack (SSTA), a novel framework to craft imperceptible AEs, which enhance the stealthiness of AEs by estimating a smooth spatial transform metric on a most critical area to generate AEs instead of adding external noise to the whole image. Compared to state-of-the-art baselines, extensive experiments indicated that SSTA could effectively improve the imperceptibility of the AEs while maintaining a 100\% attack success rate.
DTA: Distribution Transform-based Attack for Query-Limited Scenario
Dec 12, 2023In generating adversarial examples, the conventional black-box attack methods rely on sufficient feedback from the to-be-attacked models by repeatedly querying until the attack is successful, which usually results in thousands of trials during an attack. This may be unacceptable in real applications since Machine Learning as a Service Platform (MLaaS) usually only returns the final result (i.e., hard-label) to the client and a system equipped with certain defense mechanisms could easily detect malicious queries. By contrast, a feasible way is a hard-label attack that simulates an attacked action being permitted to conduct a limited number of queries. To implement this idea, in this paper, we bypass the dependency on the to-be-attacked model and benefit from the characteristics of the distributions of adversarial examples to reformulate the attack problem in a distribution transform manner and propose a distribution transform-based attack (DTA). DTA builds a statistical mapping from the benign example to its adversarial counterparts by tackling the conditional likelihood under the hard-label black-box settings. In this way, it is no longer necessary to query the target model frequently. A well-trained DTA model can directly and efficiently generate a batch of adversarial examples for a certain input, which can be used to attack un-seen models based on the assumed transferability. Furthermore, we surprisingly find that the well-trained DTA model is not sensitive to the semantic spaces of the training dataset, meaning that the model yields acceptable attack performance on other datasets. Extensive experiments validate the effectiveness of the proposed idea and the superiority of DTA over the state-of-the-art.
Double-Flow-based Steganography without Embedding for Image-to-Image Hiding
Nov 25, 2023As an emerging concept, steganography without embedding (SWE) hides a secret message without directly embedding it into a cover. Thus, SWE has the unique advantage of being immune to typical steganalysis methods and can better protect the secret message from being exposed. However, existing SWE methods are generally criticized for their poor payload capacity and low fidelity of recovered secret messages. In this paper, we propose a novel steganography-without-embedding technique, named DF-SWE, which addresses the aforementioned drawbacks and produces diverse and natural stego images. Specifically, DF-SWE employs a reversible circulation of double flow to build a reversible bijective transformation between the secret image and the generated stego image. Hence, it provides a way to directly generate stego images from secret images without a cover image. Besides leveraging the invertible property, DF-SWE can invert a secret image from a generated stego image in a nearly lossless manner and increases the fidelity of extracted secret images. To the best of our knowledge, DF-SWE is the first SWE method that can hide large images and multiple images into one image with the same size, significantly enhancing the payload capacity. According to the experimental results, the payload capacity of DF-SWE achieves 24-72 BPP is 8000-16000 times compared to its competitors while producing diverse images to minimize the exposure risk. Importantly, DF-SWE can be applied in the steganography of secret images in various domains without requiring training data from the corresponding domains. This domain-agnostic property suggests that DF-SWE can 1) be applied to hiding private data and 2) be deployed in resource-limited systems.
SCME: A Self-Contrastive Method for Data-free and Query-Limited Model Extraction Attack
Oct 15, 2023Previous studies have revealed that artificial intelligence (AI) systems are vulnerable to adversarial attacks. Among them, model extraction attacks fool the target model by generating adversarial examples on a substitute model. The core of such an attack is training a substitute model as similar to the target model as possible, where the simulation process can be categorized in a data-dependent and data-free manner. Compared with the data-dependent method, the data-free one has been proven to be more practical in the real world since it trains the substitute model with synthesized data. However, the distribution of these fake data lacks diversity and cannot detect the decision boundary of the target model well, resulting in the dissatisfactory simulation effect. Besides, these data-free techniques need a vast number of queries to train the substitute model, increasing the time and computing consumption and the risk of exposure. To solve the aforementioned problems, in this paper, we propose a novel data-free model extraction method named SCME (Self-Contrastive Model Extraction), which considers both the inter- and intra-class diversity in synthesizing fake data. In addition, SCME introduces the Mixup operation to augment the fake data, which can explore the target model's decision boundary effectively and improve the simulating capacity. Extensive experiments show that the proposed method can yield diversified fake data. Moreover, our method has shown superiority in many different attack settings under the query-limited scenario, especially for untargeted attacks, the SCME outperforms SOTA methods by 11.43\% on average for five baseline datasets.