 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Inversion Attacks on Homogeneous and Heterogeneous Graph Neural Networks
Oct 15, 2023Recently, Graph Neural Networks (GNNs), including Homogeneous Graph Neural Networks (HomoGNNs) and Heterogeneous Graph Neural Networks (HeteGNNs), have made remarkable progress in many physical scenarios, especially in communication applications. Despite achieving great success, the privacy issue of such models has also received considerable attention. Previous studies have shown that given a well-fitted target GNN, the attacker can reconstruct the sensitive training graph of this model via model inversion attacks, leading to significant privacy worries for the AI service provider. We advocate that the vulnerability comes from the target GNN itself and the prior knowledge about the shared properties in real-world graphs. Inspired by this, we propose a novel model inversion attack method on HomoGNNs and HeteGNNs, namely HomoGMI and HeteGMI. Specifically, HomoGMI and HeteGMI are gradient-descent-based optimization methods that aim to maximize the cross-entropy loss on the target GNN and the $1^{st}$ and $2^{nd}$-order proximities on the reconstructed graph. Notably, to the best of our knowledge, HeteGMI is the first attempt to perform model inversion attacks on HeteGNNs. Extensive experiments on multiple benchmarks demonstrate that the proposed method can achieve better performance than the competitors.
SCME: A Self-Contrastive Method for Data-free and Query-Limited Model Extraction Attack
Oct 15, 2023Previous studies have revealed that artificial intelligence (AI) systems are vulnerable to adversarial attacks. Among them, model extraction attacks fool the target model by generating adversarial examples on a substitute model. The core of such an attack is training a substitute model as similar to the target model as possible, where the simulation process can be categorized in a data-dependent and data-free manner. Compared with the data-dependent method, the data-free one has been proven to be more practical in the real world since it trains the substitute model with synthesized data. However, the distribution of these fake data lacks diversity and cannot detect the decision boundary of the target model well, resulting in the dissatisfactory simulation effect. Besides, these data-free techniques need a vast number of queries to train the substitute model, increasing the time and computing consumption and the risk of exposure. To solve the aforementioned problems, in this paper, we propose a novel data-free model extraction method named SCME (Self-Contrastive Model Extraction), which considers both the inter- and intra-class diversity in synthesizing fake data. In addition, SCME introduces the Mixup operation to augment the fake data, which can explore the target model's decision boundary effectively and improve the simulating capacity. Extensive experiments show that the proposed method can yield diversified fake data. Moreover, our method has shown superiority in many different attack settings under the query-limited scenario, especially for untargeted attacks, the SCME outperforms SOTA methods by 11.43\% on average for five baseline datasets.
AFLOW: Developing Adversarial Examples under Extremely Noise-limited Settings
Oct 15, 2023Extensive studies have demonstrated that deep neural networks (DNNs) are vulnerable to adversarial attacks. Despite the significant progress in the attack success rate that has been made recently, the adversarial noise generated by most of the existing attack methods is still too conspicuous to the human eyes and proved to be easily detected by defense mechanisms. Resulting that these malicious examples cannot contribute to exploring the vulnerabilities of existing DNNs sufficiently. Thus, to better reveal the defects of DNNs and further help enhance their robustness under noise-limited situations, a new inconspicuous adversarial examples generation method is exactly needed to be proposed. To bridge this gap, we propose a novel Normalize Flow-based end-to-end attack framework, called AFLOW, to synthesize imperceptible adversarial examples under strict constraints. Specifically, rather than the noise-adding manner, AFLOW directly perturbs the hidden representation of the corresponding image to craft the desired adversarial examples. Compared with existing methods, extensive experiments on three benchmark datasets show that the adversarial examples built by AFLOW exhibit superiority in imperceptibility, image quality and attack capability. Even on robust models, AFLOW can still achieve higher attack results than previous methods.
Combining GCN and Transformer for Chinese Grammatical Error Detection
May 30, 2021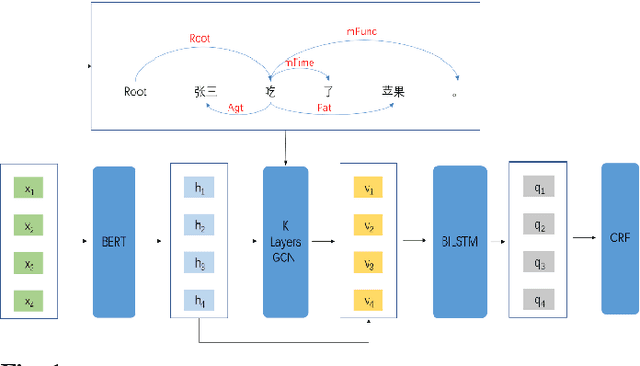
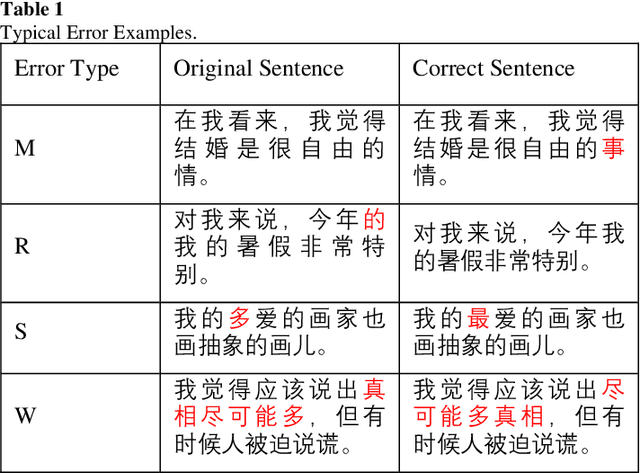
This paper describes our system at NLPTEA-2020 Task: Chinese Grammatical Error Diagnosis (CGED). The goal of CGED is to diagnose four types of grammatical errors: word selection (S), redundant words (R), missing words (M), and disordered words (W). The automatic CGED system contains two parts including error detection and error correction and our system is designed to solve the error detection problem. Our system is built on three models: 1) a BERT-based model leveraging syntactic information; 2) a BERT-based model leveraging contextual embeddings; 3) a lexicon-based graph neural network leveraging lexical information. We also design an ensemble mechanism to improve the single model's performance. Finally, our system achieves the highest F1 scores at detection level and identification level among all teams participating in the CGED 2020 task.
The Case for a Mixed-Initiative Collaborative Neuroevolution Approach
Aug 05, 2014

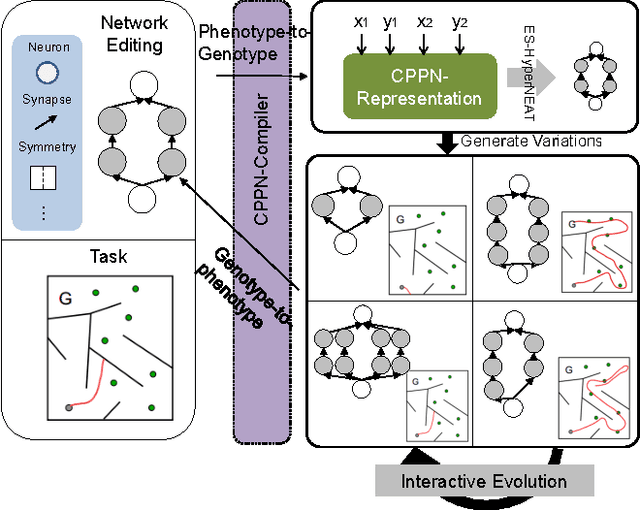
It is clear that the current attempts at using algorithms to create artificial neural networks have had mixed success at best when it comes to creating large networks and/or complex behavior. This should not be unexpected, as creating an artificial brain is essentially a design problem. Human design ingenuity still surpasses computational design for most tasks in most domains, including architecture, game design, and authoring literary fiction. This leads us to ask which the best way is to combine human and machine design capacities when it comes to designing artificial brains. Both of them have their strengths and weaknesses; for example, humans are much too slow to manually specify thousands of neurons, let alone the billions of neurons that go into a human brain, but on the other hand they can rely on a vast repository of common-sense understanding and design heuristics that can help them perform a much better guided search in design space than an algorithm. Therefore, in this paper we argue for a mixed-initiative approach for collaborative online brain building and present first results towards this goal.