 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining GCN and Transformer for Chinese Grammatical Error Detection
Paper and Code
May 30, 2021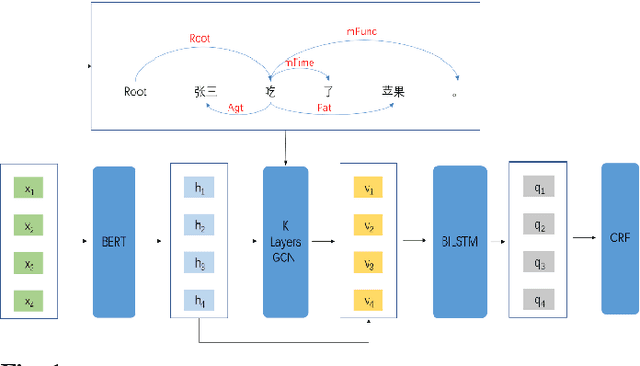
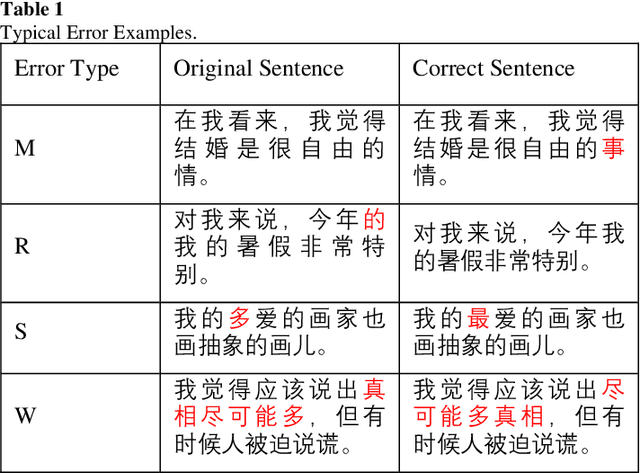
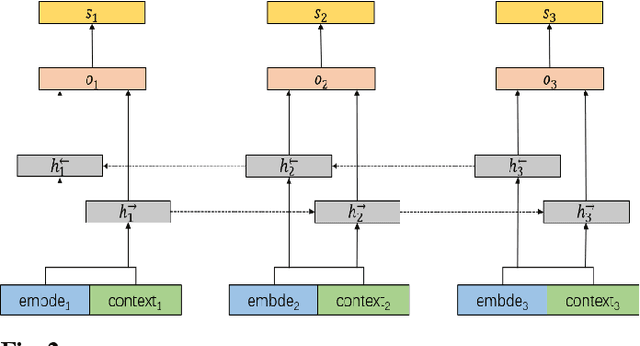
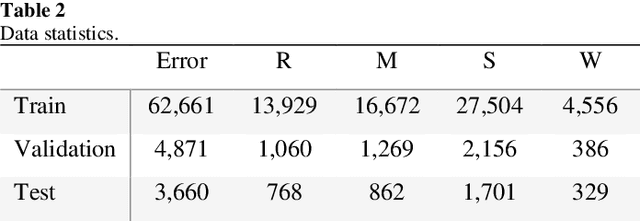
This paper describes our system at NLPTEA-2020 Task: Chinese Grammatical Error Diagnosis (CGED). The goal of CGED is to diagnose four types of grammatical errors: word selection (S), redundant words (R), missing words (M), and disordered words (W). The automatic CGED system contains two parts including error detection and error correction and our system is designed to solve the error detection problem. Our system is built on three models: 1) a BERT-based model leveraging syntactic information; 2) a BERT-based model leveraging contextual embeddings; 3) a lexicon-based graph neural network leveraging lexical information. We also design an ensemble mechanism to improve the single model's performance. Finally, our system achieves the highest F1 scores at detection level and identification level among all teams participating in the CGED 2020 task.