 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Medical Endoscopic Image Analysis via Progressive Disentangle-aware Contrastive Learning
Aug 23, 2025

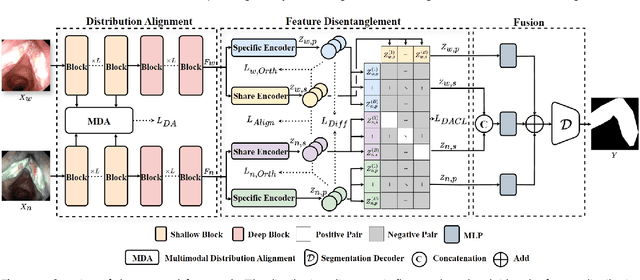

Accurate segmentation of laryngo-pharyngeal tumors is crucial for precise diagnosis and effective treatment planning. However, traditional single-modality imaging methods often fall short of capturing the complex anatomical and pathological features of these tumors. In this study, we present an innovative multi-modality representation learning framework based on the `Align-Disentangle-Fusion' mechanism that seamlessly integrates 2D White Light Imaging (WLI) and Narrow Band Imaging (NBI) pairs to enhance segmentation performance. A cornerstone of our approach is multi-scale distribution alignment, which mitigates modality discrepancies by aligning features across multiple transformer layers. Furthermore, a progressive feature disentanglement strategy is developed with the designed preliminary disentanglement and disentangle-aware contrastive learning to effectively separate modality-specific and shared features, enabling robust multimodal contrastive learning and efficient semantic fusion. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art approaches, achieving superior accuracy across diverse real clinical scenarios.
LoCo: Low-Contrast-Enhanced Contrastive Learning for Semi-Supervised Endoscopic Image Segmentation
Dec 03, 2024The segmentation of endoscopic images plays a vital role in computer-aided diagnosis and treatment. The advancements in deep learning have led to the employment of numerous models for endoscopic tumor segmentation, achieving promising segmentation performance. Despite recent advancements, precise segmentation remains challenging due to limited annotations and the issue of low contrast. To address these issues, we propose a novel semi-supervised segmentation framework termed LoCo via low-contrast-enhanced contrastive learning (LCC). This innovative approach effectively harnesses the vast amounts of unlabeled data available for endoscopic image segmentation, improving both accuracy and robustness in the segmentation process. Specifically, LCC incorporates two advanced strategies to enhance the distinctiveness of low-contrast pixels: inter-class contrast enhancement (ICE) and boundary contrast enhancement (BCE), enabling models to segment low-contrast pixels among malignant tumors, benign tumors, and normal tissues. Additionally, a confidence-based dynamic filter (CDF) is designed for pseudo-label selection, enhancing the utilization of generated pseudo-labels for unlabeled data with a specific focus on minority classes. Extensive experiments conducted on two public datasets, as well as a large proprietary dataset collected over three years, demonstrate that LoCo achieves state-of-the-art results, significantly outperforming previous methods. The source code of LoCo is available at the URL of https://github.com/AnoK3111/LoCo.
SAM-Swin: SAM-Driven Dual-Swin Transformers with Adaptive Lesion Enhancement for Laryngo-Pharyngeal Tumor Detection
Oct 29, 2024Laryngo-pharyngeal cancer (LPC) is a highly lethal malignancy in the head and neck region. Recent advancements in tumor detection, particularly through dual-branch network architectures, have significantly improved diagnostic accuracy by integrating global and local feature extraction. However, challenges remain in accurately localizing lesions and fully capitalizing on the complementary nature of features within these branches. To address these issues, we propose SAM-Swin, an innovative SAM-driven Dual-Swin Transformer for laryngo-pharyngeal tumor detection. This model leverages the robust segmentation capabilities of the Segment Anything Model 2 (SAM2) to achieve precise lesion segmentation. Meanwhile, we present a multi-scale lesion-aware enhancement module (MS-LAEM) designed to adaptively enhance the learning of nuanced complementary features across various scales, improving the quality of feature extraction and representation. Furthermore, we implement a multi-scale class-aware guidance (CAG) loss that delivers multi-scale targeted supervision, thereby enhancing the model's capacity to extract class-specific features. To validate our approach, we compiled three LPC datasets from the First Affiliated Hospital (FAHSYSU), the Sixth Affiliated Hospital (SAHSYSU) of Sun Yat-sen University, and Nanfang Hospital of Southern Medical University (NHSMU). The FAHSYSU dataset is utilized for internal training, while the SAHSYSU and NHSMU datasets serve for external evaluation. Extensive experiments demonstrate that SAM-Swin outperforms state-of-the-art methods, showcasing its potential for advancing LPC detection and improving patient outcomes. The source code of SAM-Swin is available at the URL of \href{https://github.com/VVJia/SAM-Swin}{https://github.com/VVJia/SAM-Swin}.
3D-LSPTM: An Automatic Framework with 3D-Large-Scale Pretrained Model for Laryngeal Cancer Detection Using Laryngoscopic Videos
Sep 02, 2024Laryngeal cancer is a malignant disease with a high morality rate in otorhinolaryngology, posing an significant threat to human health. Traditionally larygologists manually visual-inspect laryngeal cancer in laryngoscopic videos, which is quite time-consuming and subjective. In this study, we propose a novel automatic framework via 3D-large-scale pretrained models termed 3D-LSPTM for laryngeal cancer detection. Firstly, we collect 1,109 laryngoscopic videos from the First Affiliated Hospital Sun Yat-sen University with the approval of the Ethics Committee. Then we utilize the 3D-large-scale pretrained models of C3D, TimeSformer, and Video-Swin-Transformer, with the merit of advanced featuring videos, for laryngeal cancer detection with fine-tuning techniques. Extensive experiments show that our proposed 3D-LSPTM can achieve promising performance on the task of laryngeal cancer detection. Particularly, 3D-LSPTM with the backbone of Video-Swin-Transformer can achieve 92.4% accuracy, 95.6% sensitivity, 94.1% precision, and 94.8% F_1.
SAM-FNet: SAM-Guided Fusion Network for Laryngo-Pharyngeal Tumor Detection
Aug 15, 2024Laryngo-pharyngeal cancer (LPC) is a highly fatal malignant disease affecting the head and neck region. Previous studies on endoscopic tumor detection, particularly those leveraging dual-branch network architectures, have shown significant advancements in tumor detection. These studies highlight the potential of dual-branch networks in improving diagnostic accuracy by effectively integrating global and local (lesion) feature extraction. However, they are still limited in their capabilities to accurately locate the lesion region and capture the discriminative feature information between the global and local branches. To address these issues, we propose a novel SAM-guided fusion network (SAM-FNet), a dual-branch network for laryngo-pharyngeal tumor detection. By leveraging the powerful object segmentation capabilities of the Segment Anything Model (SAM), we introduce the SAM into the SAM-FNet to accurately segment the lesion region. Furthermore, we propose a GAN-like feature optimization (GFO) module to capture the discriminative features between the global and local branches, enhancing the fusion feature complementarity. Additionally, we collect two LPC datasets from the First Affiliated Hospital (FAHSYSU) and the Sixth Affiliated Hospital (SAHSYSU) of Sun Yat-sen University. The FAHSYSU dataset is used as the internal dataset for training the model, while the SAHSYSU dataset is used as the external dataset for evaluating the model's performance. Extensive experiments on both datasets of FAHSYSU and SAHSYSU demonstrate that the SAM-FNet can achieve competitive results, outperforming the state-of-the-art counterparts. The source code of SAM-FNet is available at the URL of https://github.com/VVJia/SAM-FNet.
Rethinking Radiology Report Generation via Causal Reasoning and Counterfactual Augmentation
Dec 05, 2023



Radiology Report Generation (RRG) draws attention as an interaction between vision and language fields. Previous works inherited the ideology of vision-to-language generation tasks,aiming to generate paragraphs with high consistency as reports. However, one unique characteristic of RRG, the independence between diseases, was neglected, leading to the injection of disease co-occurrence as a confounder that effects the results through backdoor path. Unfortunately, this confounder confuses the process of report generation worse because of the biased RRG data distribution. In this paper, to rethink this issue thoroughly, we reason about its causes and effects from a novel perspective of statistics and causality, where the Joint Vision Coupling and the Conditional Sentence Coherence Coupling are two aspects prone to implicitly decrease the accuracy of reports. Then, a counterfactual augmentation strategy that contains the Counterfactual Sample Synthesis and the Counterfactual Report Reconstruction sub-methods is proposed to break these two aspects of spurious effects. Experimental results and further analyses on two widely used datasets justify our reasoning and proposed methods.