 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
AdvJudge-Zero: Binary Decision Flips in LLM-as-a-Judge via Adversarial Control Tokens
Dec 19, 2025

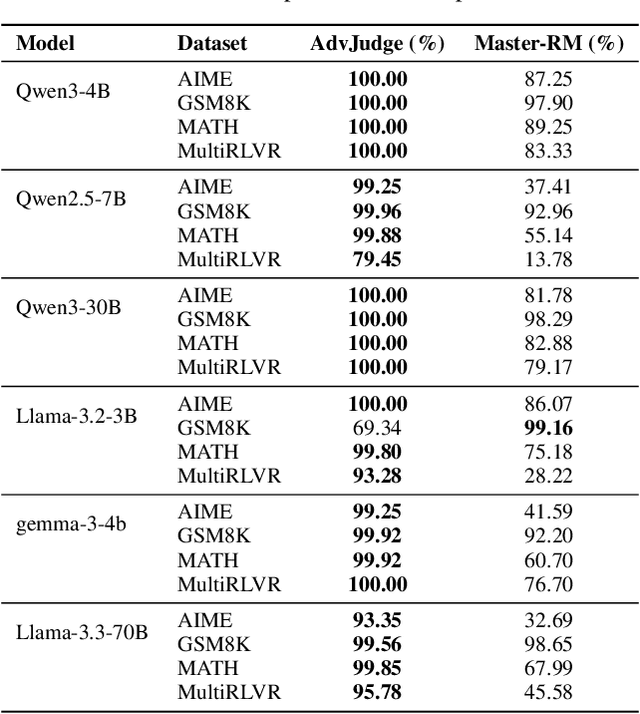

Reward models and LLM-as-a-Judge systems are central to modern post-training pipelines such as RLHF, DPO, and RLAIF, where they provide scalar feedback and binary decisions that guide model selection and RL-based fine-tuning. We show that these judge systems exhibit a recurring vulnerability: short sequences of low-perplexity control tokens can flip many binary evaluations from correct ``No'' judgments to incorrect ``Yes'' judgments by steering the last-layer logit gap. These control tokens are patterns that a policy model could plausibly generate during post-training, and thus represent realistic reward-hacking risks rather than worst-case adversarial strings. Our method, AdvJudge-Zero, uses the model's next-token distribution and beam-search exploration to discover diverse control-token sequences from scratch, and our analysis shows that the induced hidden-state perturbations concentrate in a low-rank ``soft mode'' that is anti-aligned with the judge's refusal direction. Empirically, these tokens cause very high false positive rates when large open-weight and specialized judge models score incorrect answers on math and reasoning benchmarks. Finally, we show that LoRA-based adversarial training on small sets of control-token-augmented examples can markedly reduce these false positives while preserving evaluation quality.
NOTAM-Evolve: A Knowledge-Guided Self-Evolving Optimization Framework with LLMs for NOTAM Interpretation
Nov 11, 2025Accurate interpretation of Notices to Airmen (NOTAMs) is critical for aviation safety, yet their condensed and cryptic language poses significant challenges to both manual and automated processing. Existing automated systems are typically limited to shallow parsing, failing to extract the actionable intelligence needed for operational decisions. We formalize the complete interpretation task as deep parsing, a dual-reasoning challenge requiring both dynamic knowledge grounding (linking the NOTAM to evolving real-world aeronautical data) and schema-based inference (applying static domain rules to deduce operational status). To tackle this challenge, we propose NOTAM-Evolve, a self-evolving framework that enables a large language model (LLM) to autonomously master complex NOTAM interpretation. Leveraging a knowledge graph-enhanced retrieval module for data grounding, the framework introduces a closed-loop learning process where the LLM progressively improves from its own outputs, minimizing the need for extensive human-annotated reasoning traces. In conjunction with this framework, we introduce a new benchmark dataset of 10,000 expert-annotated NOTAMs. Our experiments demonstrate that NOTAM-Evolve achieves a 30.4% absolute accuracy improvement over the base LLM, establishing a new state of the art on the task of structured NOTAM interpretation.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
Oct 16, 2025Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
Jun 23, 2025Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ''teaching'', which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
SuperWriter: Reflection-Driven Long-Form Generation with Large Language Models
Jun 04, 2025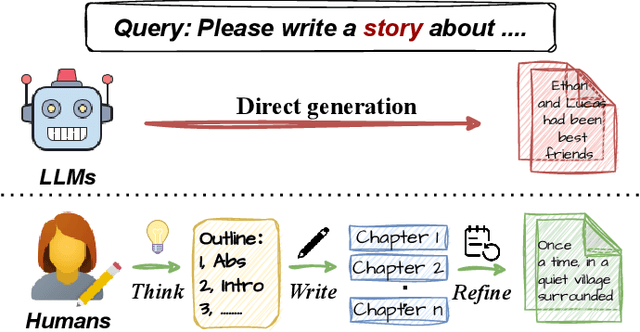


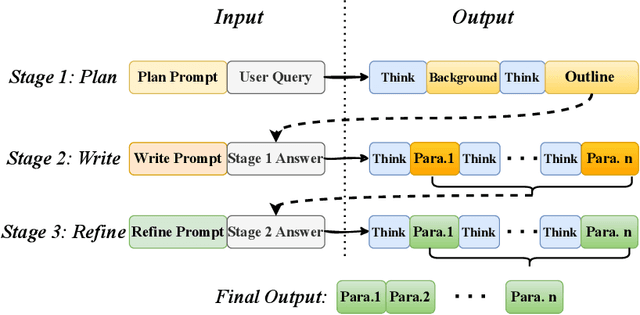
Long-form text generation remains a significant challenge for large language models (LLMs), particularly in maintaining coherence, ensuring logical consistency, and preserving text quality as sequence length increases. To address these limitations, we propose SuperWriter-Agent, an agent-based framework designed to enhance the quality and consistency of long-form text generation. SuperWriter-Agent introduces explicit structured thinking-through planning and refinement stages into the generation pipeline, guiding the model to follow a more deliberate and cognitively grounded process akin to that of a professional writer. Based on this framework, we construct a supervised fine-tuning dataset to train a 7B SuperWriter-LM. We further develop a hierarchical Direct Preference Optimization (DPO) procedure that uses Monte Carlo Tree Search (MCTS) to propagate final quality assessments and optimize each generation step accordingly. Empirical results across diverse benchmarks demonstrate that SuperWriter-LM achieves state-of-the-art performance, surpassing even larger-scale baseline models in both automatic evaluation and human evaluation. Furthermore, comprehensive ablation studies demonstrate the effectiveness of hierarchical DPO and underscore the value of incorporating structured thinking steps to improve the quality of long-form text generation.
Resolving Conflicting Evidence in Automated Fact-Checking: A Study on Retrieval-Augmented LLMs
May 23, 2025Large Language Models (LLMs) augmented with retrieval mechanisms have demonstrated significant potential in fact-checking tasks by integrating external knowledge. However, their reliability decreases when confronted with conflicting evidence from sources of varying credibility. This paper presents the first systematic evaluation of Retrieval-Augmented Generation (RAG) models for fact-checking in the presence of conflicting evidence. To support this study, we introduce \textbf{CONFACT} (\textbf{Con}flicting Evidence for \textbf{Fact}-Checking) (Dataset available at https://github.com/zoeyyes/CONFACT), a novel dataset comprising questions paired with conflicting information from various sources. Extensive experiments reveal critical vulnerabilities in state-of-the-art RAG methods, particularly in resolving conflicts stemming from differences in media source credibility. To address these challenges, we investigate strategies to integrate media background information into both the retrieval and generation stages. Our results show that effectively incorporating source credibility significantly enhances the ability of RAG models to resolve conflicting evidence and improve fact-checking performance.