 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHATS: High-Accuracy Triple-Set Watermarking for Large Language Models
Dec 22, 2025Misuse of LLM-generated text can be curbed by watermarking techniques that embed implicit signals into the output. We propose a watermark that partitions the vocabulary at each decoding step into three sets (Green/Yellow/Red) with fixed ratios and restricts sampling to the Green and Yellow sets. At detection time, we replay the same partitions, compute Green-enrichment and Red-depletion statistics, convert them to one-sided z-scores, and aggregate their p-values via Fisher's method to decide whether a passage is watermarked. We implement generation, detection, and testing on Llama 2 7B, and evaluate true-positive rate, false-positive rate, and text quality. Results show that the triple-partition scheme achieves high detection accuracy at fixed FPR while preserving readability.
* Camera-ready version of the paper accepted for oral presentation at the 11th International Conference on Computer and Communications (ICCC 2025)
Shifting Long-Context LLMs Research from Input to Output
Mar 07, 2025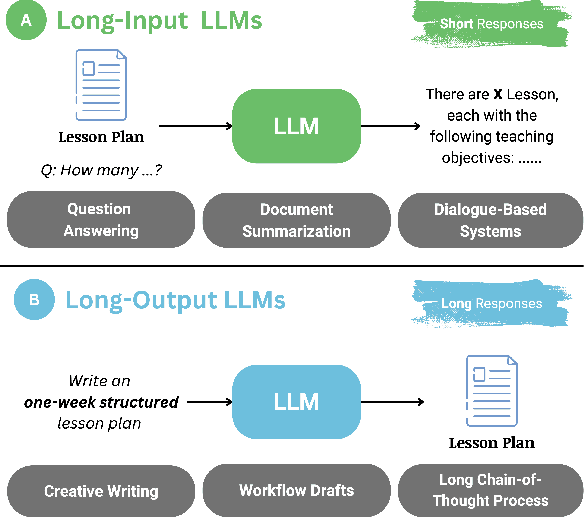
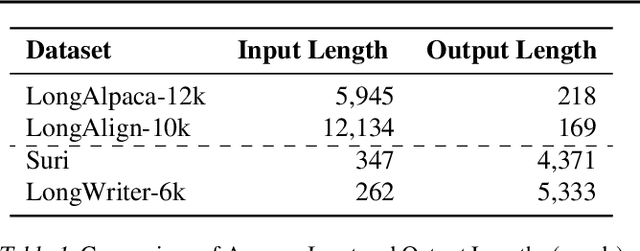
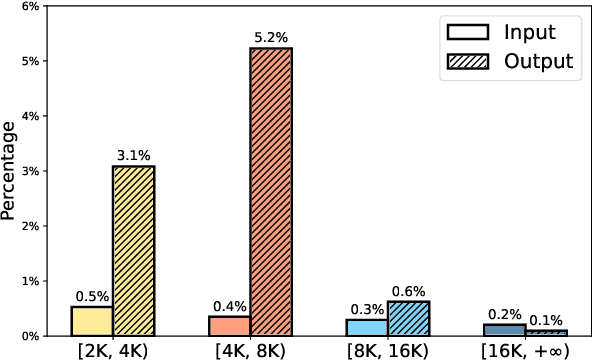
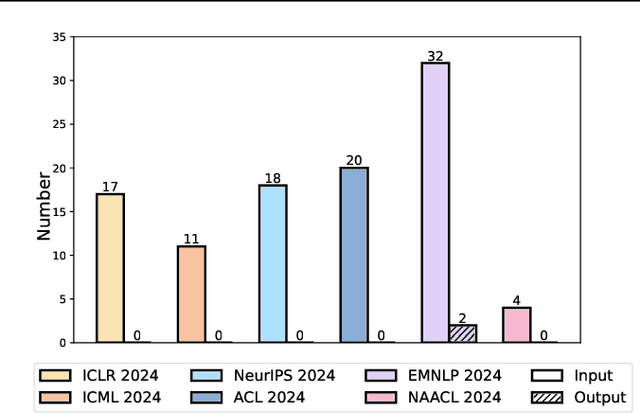
Recent advancements in long-context Large Language Models (LLMs) have primarily concentrated on processing extended input contexts, resulting in significant strides in long-context comprehension. However, the equally critical aspect of generating long-form outputs has received comparatively less attention. This paper advocates for a paradigm shift in NLP research toward addressing the challenges of long-output generation. Tasks such as novel writing, long-term planning, and complex reasoning require models to understand extensive contexts and produce coherent, contextually rich, and logically consistent extended text. These demands highlight a critical gap in current LLM capabilities. We underscore the importance of this under-explored domain and call for focused efforts to develop foundational LLMs tailored for generating high-quality, long-form outputs, which hold immense potential for real-world applications.
LongGenbench: Benchmarking Long-Form Generation in Long Context LLMs
Sep 11, 2024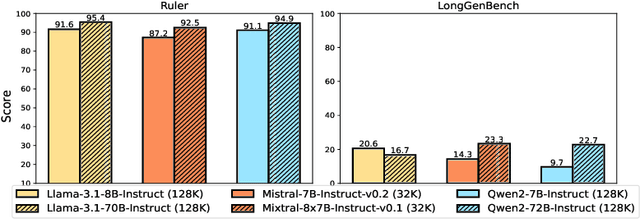
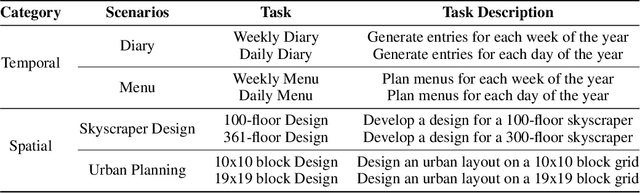
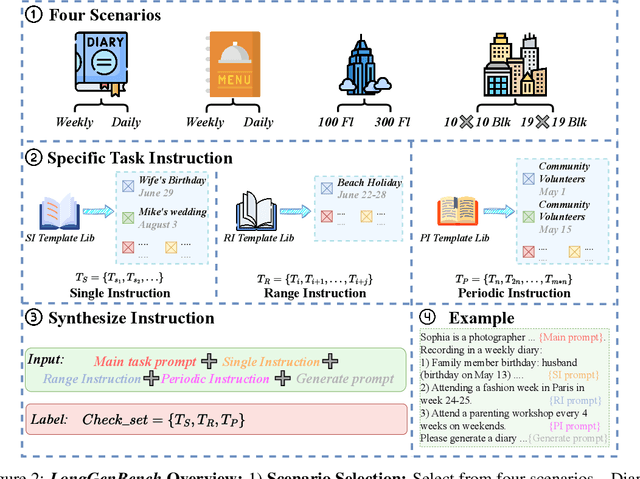
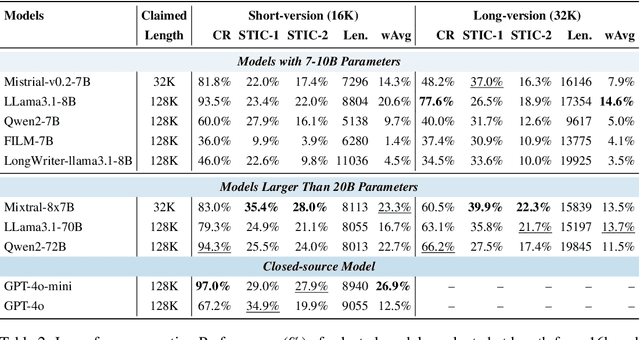
The abilities of long-context language models (LMs) are often evaluated using the "Needle-in-a-Haystack" (NIAH) test, which comprises tasks designed to assess a model's ability to identify specific information ("needle") within large text sequences ("haystack"). While these benchmarks measure how well models understand long-context input sequences, they do not effectively gauge the quality of long-form text generation--a critical aspect for applications such as design proposals and creative writing. To address this gap, we have introduced a new long-form text evaluation benchmark, LongGenbench, which tests models' ability to identify specific events within generated long text sequences. In this benchmark, we prompt long-context LMs to create long-form text that must include particular events or constraints and evaluate their ability to incorporate these elements. We evaluated ten long-context LMs across four distinct scenarios, three types of prompt instructions, and two different generation-length settings (16K and 32K). Although these models perform well on NIAH benchmarks, none demonstrated satisfactory performance on the LongGenbench, raising concerns about their ability to generate coherent long-form text that follows instructions. Additionally, as the length of the generated text increases, all models exhibit a significant drop in performance.
Spinning the Golden Thread: Benchmarking Long-Form Generation in Language Models
Sep 03, 2024The abilities of long-context language models (LMs) are often evaluated using the "Needle-in-a-Haystack" (NIAH) test, which comprises tasks designed to assess a model's ability to identify specific information ("needle") within large text sequences ("haystack"). While these benchmarks measure how well models understand long-context input sequences, they do not effectively gauge the quality of long-form text generation--a critical aspect for applications such as design proposals and creative writing. To address this gap, we have introduced a new long-form text evaluation benchmark, Spinning the Golden Thread (SGT), which tests models' ability to identify specific events within generated long text sequences. In this benchmark, we prompt long-context LMs to create long-form text that must include particular events or constraints and evaluate their ability to incorporate these elements. We evaluated ten long-context LMs across four distinct scenarios, three types of prompt instructions, and two different generation-length settings (16K and 32K). Although these models perform well on NIAH benchmarks, none demonstrated satisfactory performance on the Spinning the Golden Thread, raising concerns about their ability to generate coherent long-form text that follows instructions. Additionally, as the length of the generated text increases, all models exhibit a significant drop in performance.