 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSC: Multi-Scale Spatio-Temporal Causal Attention for Autoregressive Video Diffusion
Dec 13, 2024Diffusion transformers enable flexible generative modeling for video. However, it is still technically challenging and computationally expensive to generate high-resolution videos with rich semantics and complex motion. Similar to languages, video data are also auto-regressive by nature, so it is counter-intuitive to use attention mechanism with bi-directional dependency in the model. Here we propose a Multi-Scale Causal (MSC) framework to address these problems. Specifically, we introduce multiple resolutions in the spatial dimension and high-low frequencies in the temporal dimension to realize efficient attention calculation. Furthermore, attention blocks on multiple scales are combined in a controlled way to allow causal conditioning on noisy image frames for diffusion training, based on the idea that noise destroys information at different rates on different resolutions. We theoretically show that our approach can greatly reduce the computational complexity and enhance the efficiency of training. The causal attention diffusion framework can also be used for auto-regressive long video generation, without violating the natural order of frame sequences.
DCMS: Motion Forecasting with Dual Consistency and Multi-Pseudo-Target Supervision
Apr 12, 2022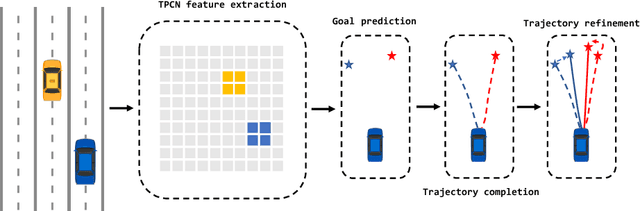
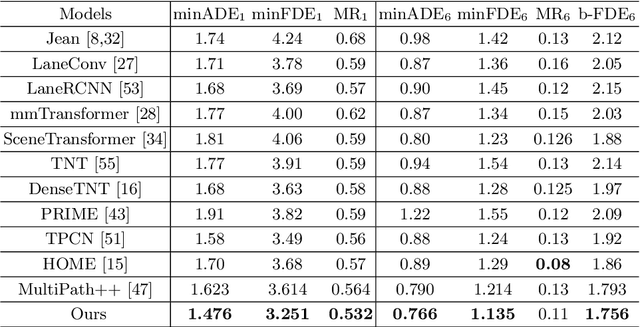
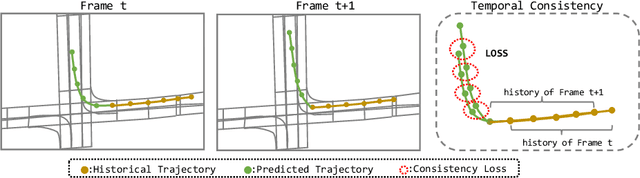
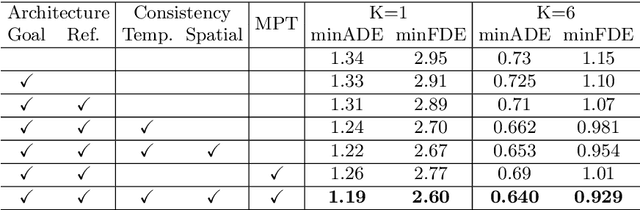
We present a novel framework for motion forecasting with Dual Consistency Constraints and Multi-Pseudo-Target supervision. The motion forecasting task predicts future trajectories of vehicles by incorporating spatial and temporal information from the past. A key design of DCMS is the proposed Dual Consistency Constraints that regularize the predicted trajectories under spatial and temporal perturbation during the training stage. In addition, we design a novel self-ensembling scheme to obtain accurate pseudo targets to model the multi-modality in motion forecasting through supervision with multiple targets explicitly, namely Multi-Pseudo-Target supervision. Our experimental results on the Argoverse motion forecasting benchmark show that DCMS significantly outperforms the state-of-the-art methods, achieving 1st place on the leaderboard. We also demonstrate that our proposed strategies can be incorporated into other motion forecasting approaches as general training schemes.
Towards a Systematic Computational Framework for Modeling Multi-Agent Decision-Making at Micro Level for Smart Vehicles in a Smart World
Sep 25, 2020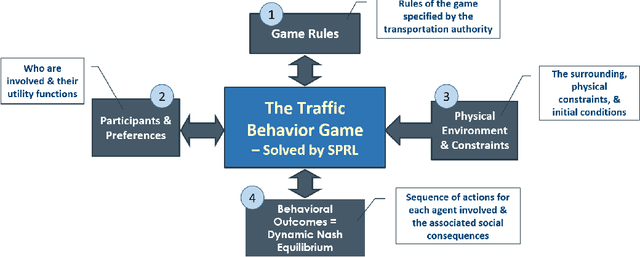
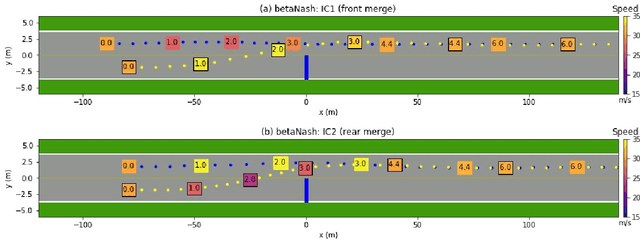
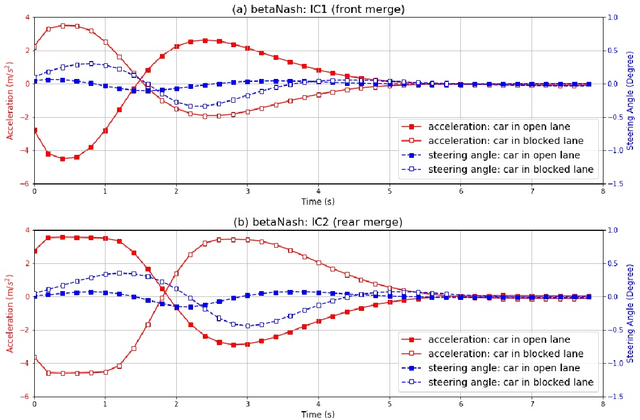
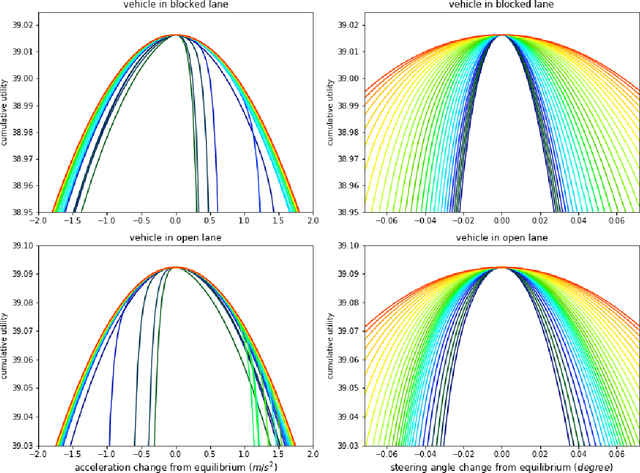
We propose a multi-agent based computational framework for modeling decision-making and strategic interaction at micro level for smart vehicles in a smart world. The concepts of Markov game and best response dynamics are heavily leveraged. Our aim is to make the framework conceptually sound and computationally practical for a range of realistic applications, including micro path planning for autonomous vehicles. To this end, we first convert the would-be stochastic game problem into a closely related deterministic one by introducing risk premium in the utility function for each individual agent. We show how the sub-game perfect Nash equilibrium of the simplified deterministic game can be solved by an algorithm based on best response dynamics. In order to better model human driving behaviors with bounded rationality, we seek to further simplify the solution concept by replacing the Nash equilibrium condition with a heuristic and adaptive optimization with finite look-ahead anticipation. In addition, the algorithm corresponding to the new solution concept drastically improves the computational efficiency. To demonstrate how our approach can be applied to realistic traffic settings, we conduct a simulation experiment: to derive merging and yielding behaviors on a double-lane highway with an unexpected barrier. Despite assumption differences involved in the two solution concepts, the derived numerical solutions show that the endogenized driving behaviors are very similar. We also briefly comment on how the proposed framework can be further extended in a number of directions in our forthcoming work, such as behavioral calibration using real traffic video data, computational mechanism design for traffic policy optimization, and so on.