 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanner Matters! An Efficient and Unbalanced Multi-agent Collaboration Framework for Long-horizon Planning
May 04, 2026Language model (LM)-based agents have demonstrated promising capabilities in automating complex tasks from natural language instructions, yet they continue to struggle with long-horizon planning and reasoning. To address this, we propose an enhanced multi-agent framework that decomposes automation into three roles: a planner for high-level decision-making, an actor for task execution, and a memory manager for contextual reasoning. While this modular decomposition aligns with established design patterns, our core contribution lies in a systematic compute-allocation analysis, revealing that planning is the dominant factor influencing task performance. Execution and memory management require significantly less compute and model capacity to achieve competitive results. Building on these insights, we introduce a planner-centric reinforcement learning approach, which exclusively optimizes the planner using trajectory-level rewards from a VLM-as-judge, while freezing the other components. Extensive experiments on benchmarks spanning web navigation, OS control, and tool use demonstrate that concentrating model capacity and learning on high-level planning yields robust and compute-efficient improvements in long-horizon agent automation. Our code is publicly released.
Hybrid Self-evolving Structured Memory for GUI Agents
Mar 11, 2026The remarkable progress of vision-language models (VLMs) has enabled GUI agents to interact with computers in a human-like manner. Yet real-world computer-use tasks remain difficult due to long-horizon workflows, diverse interfaces, and frequent intermediate errors. Prior work equips agents with external memory built from large collections of trajectories, but relies on flat retrieval over discrete summaries or continuous embeddings, falling short of the structured organization and self-evolving characteristics of human memory. Inspired by the brain, we propose Hybrid Self-evolving Structured Memory (HyMEM), a graph-based memory that couples discrete high-level symbolic nodes with continuous trajectory embeddings. HyMEM maintains a graph structure to support multi-hop retrieval, self-evolution via node update operations, and on-the-fly working-memory refreshing during inference. Extensive experiments show that HyMEM consistently improves open-source GUI agents, enabling 7B/8B backbones to match or surpass strong closed-source models; notably, it boosts Qwen2.5-VL-7B by +22.5% and outperforms Gemini2.5-Pro-Vision and GPT-4o.
Towards General Continuous Memory for Vision-Language Models
May 23, 2025



Language models (LMs) and their extension, vision-language models (VLMs), have achieved remarkable performance across various tasks. However, they still struggle with complex reasoning tasks that require multimodal or multilingual real-world knowledge. To support such capabilities, an external memory system that can efficiently provide relevant multimodal information is essential. Existing approaches generally concatenate image and text tokens into a long sequence as memory, which, however, may drastically increase context length and even degrade performance. In contrast, we propose using continuous memory, a compact set of dense embeddings to more effectively and efficiently represent multimodal and multilingual knowledge. Our key insight is that a VLM can serve as its own continuous memory encoder. We empirically show that this design improves performance on complex multimodal reasoning tasks. Building on this, we introduce a data-efficient and parameter-efficient method to fine-tune the VLM into a memory encoder, requiring only 1.2% of the model's parameters and a small corpus of 15.6K self-synthesized samples. Our approach CoMEM utilizes VLM's original capabilities to encode arbitrary multimodal and multilingual knowledge into just 8 continuous embeddings. Since the inference-time VLM remains frozen, our memory module is plug-and-play and can be flexibly integrated as needed. Extensive experiments across eight multimodal reasoning benchmarks demonstrate the effectiveness of our approach.
Causal-Copilot: An Autonomous Causal Analysis Agent
Apr 21, 2025Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data -- including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle -- expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis. A live interactive demo of Causal-Copilot is available at https://causalcopilot.com/.
Source-free domain adaptation based on label reliability for cross-domain bearing fault diagnosis
Mar 11, 2025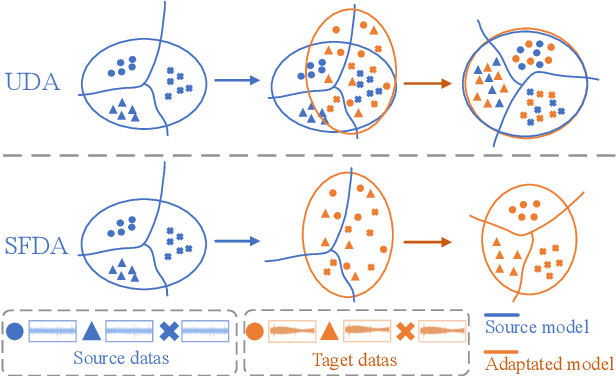

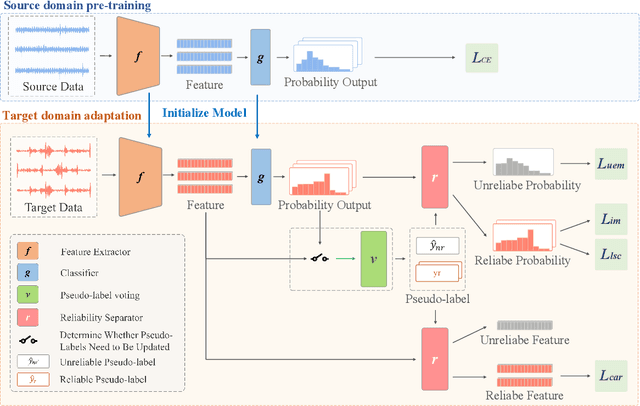

Source-free domain adaptation (SFDA) has been exploited for cross-domain bearing fault diagnosis without access to source data. Current methods select partial target samples with reliable pseudo-labels for model adaptation, which is sub-optimal due to the ignored target samples. We argue that every target sample can contribute to model adaptation, and accordingly propose in this paper a novel SFDA-based approach for bearing fault diagnosis that exploits both reliable and unreliable pseudo-labels. We develop a data-augmentation-based label voting strategy to divide the target samples into reliable and unreliable ones. We propose to explore the underlying relation between feature space and label space by using the reliable pseudo-labels as ground-truth labels, meanwhile, alleviating negative transfer by maximizing the entropy of the unreliable pseudo-labels. The proposed method achieves well-balance between discriminability and diversity by taking advantage of reliable and unreliable pseudo-labels. Extensive experiments are conducted on two bearing fault benchmarks, demonstrating that our approach achieves significant performance improvements against existing SFDA-based bearing fault diagnosis methods. Our code is available at https://github.com/BdLab405/SDALR.
MIVC: Multiple Instance Visual Component for Visual-Language Models
Dec 28, 2023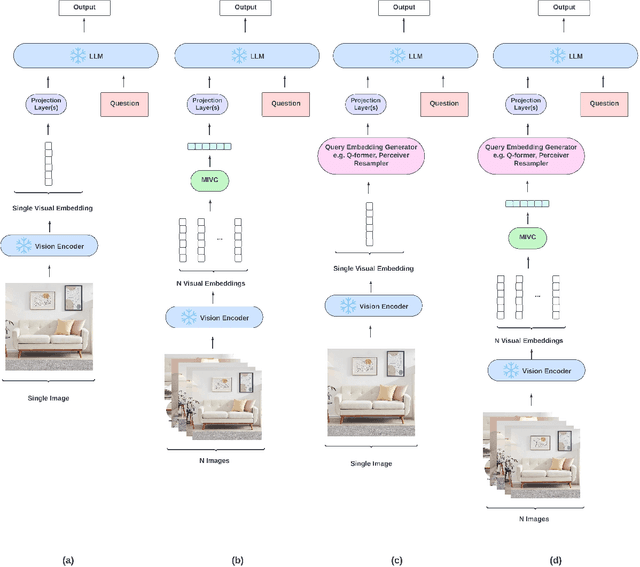

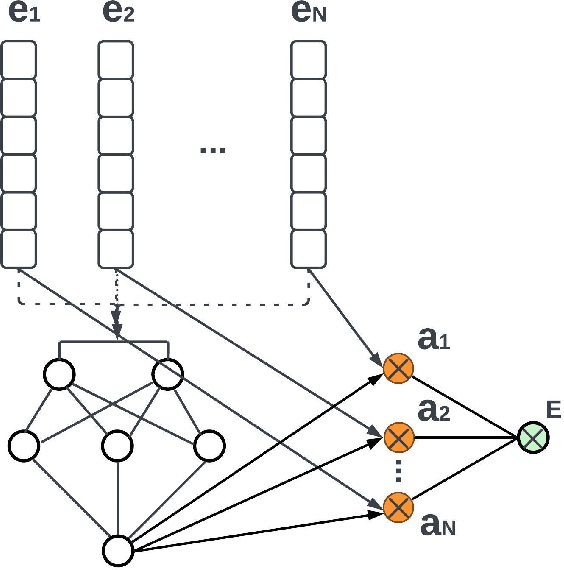

Vision-language models have been widely explored across a wide range of tasks and achieve satisfactory performance. However, it's under-explored how to consolidate entity understanding through a varying number of images and to align it with the pre-trained language models for generative tasks. In this paper, we propose MIVC, a general multiple instance visual component to bridge the gap between various image inputs with off-the-shelf vision-language models by aggregating visual representations in a permutation-invariant fashion through a neural network. We show that MIVC could be plugged into the visual-language models to improve the model performance consistently on visual question answering, classification and captioning tasks on a public available e-commerce dataset with multiple images per product. Furthermore, we show that the component provides insight into the contribution of each image to the downstream tasks.
Catalog Phrase Grounding (CPG): Grounding of Product Textual Attributes in Product Images for e-commerce Vision-Language Applications
Aug 30, 2023


We present Catalog Phrase Grounding (CPG), a model that can associate product textual data (title, brands) into corresponding regions of product images (isolated product region, brand logo region) for e-commerce vision-language applications. We use a state-of-the-art modulated multimodal transformer encoder-decoder architecture unifying object detection and phrase-grounding. We train the model in self-supervised fashion with 2.3 million image-text pairs synthesized from an e-commerce site. The self-supervision data is annotated with high-confidence pseudo-labels generated with a combination of teacher models: a pre-trained general domain phrase grounding model (e.g. MDETR) and a specialized logo detection model. This allows CPG, as a student model, to benefit from transfer knowledge from these base models combining general-domain knowledge and specialized knowledge. Beyond immediate catalog phrase grounding tasks, we can benefit from CPG representations by incorporating them as ML features into downstream catalog applications that require deep semantic understanding of products. Our experiments on product-brand matching, a challenging e-commerce application, show that incorporating CPG representations into the existing production ensemble system leads to on average 5% recall improvement across all countries globally (with the largest lift of 11% in a single country) at fixed 95% precision, outperforming other alternatives including a logo detection teacher model and ResNet50.