 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed2Scale: A Self-Evolving Data Engine for Embodied AI via Small to Large Model Synergy and Multimodal Evaluation
Mar 09, 2026Existing data generation methods suffer from exploration limits, embodiment gaps, and low signal-to-noise ratios, leading to performance degradation during self-iteration. To address these challenges, we propose Seed2Scale, a self-evolving data engine that overcomes the data bottleneck through a heterogeneous synergy of "small-model collection, large-model evaluation, and target-model learning". Starting with as few as four seed demonstrations, the engine employs the lightweight Vision-Language-Action model, SuperTiny, as a dedicated collector, leveraging its strong inductive bias for robust exploration in parallel environments. Concurrently, a pre-trained Vision-Language Model is integrated as a Verifer to autonomously perform success/failure judgment and quality scoring for the massive generated trajectories. Seed2Scale effectively mitigates model collapse, ensuring the stability of the self-evolution process. Experimental results demonstrate that Seed2Scale exhibits signifcant scaling potential: as iterations progress, the success rate of the target model shows a robust upward trend, achieving a performance improvement of 131.2%. Furthermore, Seed2Scale signifcantly outperforms existing data augmentation methods, providing a scalable and cost-effective pathway for the large-scale development of Generalist Embodied AI. Project page: https://terminators2025.github.io/Seed2Scale.github.io
LiDAR Prompted Spatio-Temporal Multi-View Stereo for Autonomous Driving
Mar 04, 2026Accurate metric depth is critical for autonomous driving perception and simulation, yet current approaches struggle to achieve high metric accuracy, multi-view and temporal consistency, and cross-domain generalization. To address these challenges, we present DriveMVS, a novel multi-view stereo framework that reconciles these competing objectives through two key insights: (1) Sparse but metrically accurate LiDAR observations can serve as geometric prompts to anchor depth estimation in absolute scale, and (2) deep fusion of diverse cues is essential for resolving ambiguities and enhancing robustness, while a spatio-temporal decoder ensures consistency across frames. Built upon these principles, DriveMVS embeds the LiDAR prompt in two ways: as a hard geometric prior that anchors the cost volume, and as soft feature-wise guidance fused by a triple-cue combiner. Regarding temporal consistency, DriveMVS employs a spatio-temporal decoder that jointly leverages geometric cues from the MVS cost volume and temporal context from neighboring frames. Experiments show that DriveMVS achieves state-of-the-art performance on multiple benchmarks, excelling in metric accuracy, temporal stability, and zero-shot cross-domain transfer, demonstrating its practical value for scalable, reliable autonomous driving systems.
RealMirror: A Comprehensive, Open-Source Vision-Language-Action Platform for Embodied AI
Sep 18, 2025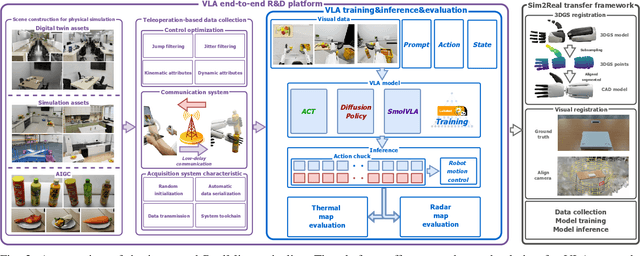
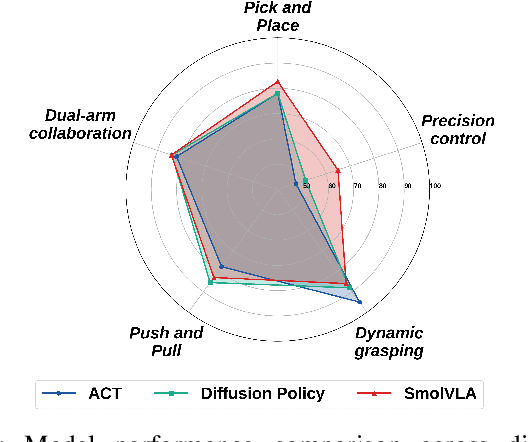
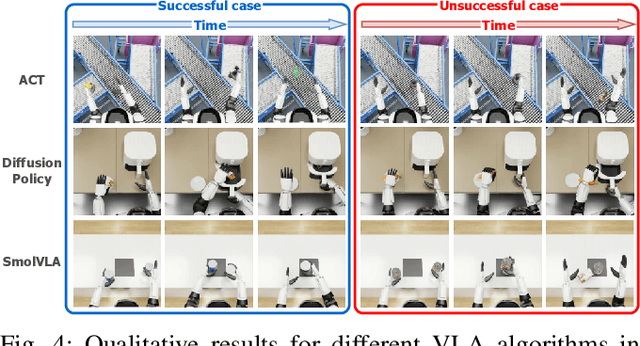

The emerging field of Vision-Language-Action (VLA) for humanoid robots faces several fundamental challenges, including the high cost of data acquisition, the lack of a standardized benchmark, and the significant gap between simulation and the real world. To overcome these obstacles, we propose RealMirror, a comprehensive, open-source embodied AI VLA platform. RealMirror builds an efficient, low-cost data collection, model training, and inference system that enables end-to-end VLA research without requiring a real robot. To facilitate model evolution and fair comparison, we also introduce a dedicated VLA benchmark for humanoid robots, featuring multiple scenarios, extensive trajectories, and various VLA models. Furthermore, by integrating generative models and 3D Gaussian Splatting to reconstruct realistic environments and robot models, we successfully demonstrate zero-shot Sim2Real transfer, where models trained exclusively on simulation data can perform tasks on a real robot seamlessly, without any fine-tuning. In conclusion, with the unification of these critical components, RealMirror provides a robust framework that significantly accelerates the development of VLA models for humanoid robots. Project page: https://terminators2025.github.io/RealMirror.github.io
Convergent and divergent connectivity patterns of the arcuate fasciculus in macaques and humans
Jun 24, 2025The organization and connectivity of the arcuate fasciculus (AF) in nonhuman primates remain contentious, especially concerning how its anatomy diverges from that of humans. Here, we combined cross-scale single-neuron tracing - using viral-based genetic labeling and fluorescence micro-optical sectioning tomography in macaques (n = 4; age 3 - 11 years) - with whole-brain tractography from 11.7T diffusion MRI. Complemented by spectral embedding analysis of 7.0T MRI in humans, we performed a comparative connectomic analysis of the AF across species. We demonstrate that the macaque AF originates in the temporal-parietal cortex, traverses the auditory cortex and parietal operculum, and projects into prefrontal regions. In contrast, the human AF exhibits greater expansion into the middle temporal gyrus and stronger prefrontal and parietal operculum connectivity - divergences quantified by Kullback-Leibler analysis that likely underpin the evolutionary specialization of human language networks. These interspecies differences - particularly the human AF's broader temporal integration and strengthened frontoparietal linkages - suggest a connectivity-based substrate for the emergence of advanced language processing unique to humans. Furthermore, our findings offer a neuroanatomical framework for understanding AF-related disorders such as aphasia and dyslexia, where aberrant connectivity disrupts language function.
SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Jun 09, 2025Recent advances in large language models (LLMs) and vision-language models (VLMs) have enabled powerful autonomous agents capable of complex reasoning and multi-modal tool use. Despite their growing capabilities, today's agent frameworks remain fragile, lacking principled mechanisms for secure information flow, reliability, and multi-agent coordination. In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments. By constraining LLM reasoning to respect these security labels, SAFEFLOW prevents untrusted or adversarial inputs from contaminating high-integrity decisions. To ensure robustness in concurrent multi-agent settings, SAFEFLOW introduces transactional execution, conflict resolution, and secure scheduling over shared state, preserving global consistency across agents. We further introduce mechanisms, including write-ahead logging, rollback, and secure caches, that further enhance resilience against runtime errors and policy violations. To validate the performances, we built SAFEFLOWBENCH, a comprehensive benchmark suite designed to evaluate agent reliability under adversarial, noisy, and concurrent operational conditions. Extensive experiments demonstrate that agents built with SAFEFLOW maintain impressive task performance and security guarantees even in hostile environments, substantially outperforming state-of-the-art. Together, SAFEFLOW and SAFEFLOWBENCH lay the groundwork for principled, robust, and secure agent ecosystems, advancing the frontier of reliable autonomy.
UniMatch: Universal Matching from Atom to Task for Few-Shot Drug Discovery
Feb 18, 2025Drug discovery is crucial for identifying candidate drugs for various diseases.However, its low success rate often results in a scarcity of annotations, posing a few-shot learning problem. Existing methods primarily focus on single-scale features, overlooking the hierarchical molecular structures that determine different molecular properties. To address these issues, we introduce Universal Matching Networks (UniMatch), a dual matching framework that integrates explicit hierarchical molecular matching with implicit task-level matching via meta-learning, bridging multi-level molecular representations and task-level generalization. Specifically, our approach explicitly captures structural features across multiple levels, such as atoms, substructures, and molecules, via hierarchical pooling and matching, facilitating precise molecular representation and comparison. Additionally, we employ a meta-learning strategy for implicit task-level matching, allowing the model to capture shared patterns across tasks and quickly adapt to new ones. This unified matching framework ensures effective molecular alignment while leveraging shared meta-knowledge for fast adaptation. Our experimental results demonstrate that UniMatch outperforms state-of-the-art methods on the MoleculeNet and FS-Mol benchmarks, achieving improvements of 2.87% in AUROC and 6.52% in delta AUPRC. UniMatch also shows excellent generalization ability on the Meta-MolNet benchmark.
Selective Kalman Filter: When and How to Fuse Multi-Sensor Information to Overcome Degeneracy in SLAM
Dec 23, 2024



Research trends in SLAM systems are now focusing more on multi-sensor fusion to handle challenging and degenerative environments. However, most existing multi-sensor fusion SLAM methods mainly use all of the data from a range of sensors, a strategy we refer to as the all-in method. This method, while merging the benefits of different sensors, also brings in their weaknesses, lowering the robustness and accuracy and leading to high computational demands. To address this, we propose a new fusion approach -- Selective Kalman Filter -- to carefully choose and fuse information from multiple sensors (using LiDAR and visual observations as examples in this paper). For deciding when to fuse data, we implement degeneracy detection in LiDAR SLAM, incorporating visual measurements only when LiDAR SLAM exhibits degeneracy. Regarding degeneracy detection, we propose an elegant yet straightforward approach to determine the degeneracy of LiDAR SLAM and to identify the specific degenerative direction. This method fully considers the coupled relationship between rotational and translational constraints. In terms of how to fuse data, we use visual measurements only to update the specific degenerative states. As a result, our proposed method improves upon the all-in method by greatly enhancing real-time performance due to less processing visual data, and it introduces fewer errors from visual measurements. Experiments demonstrate that our method for degeneracy detection and fusion, in addressing degeneracy issues, exhibits higher precision and robustness compared to other state-of-the-art methods, and offers enhanced real-time performance relative to the all-in method. The code is openly available.
MDHP-Net: Detecting Injection Attacks on In-vehicle Network using Multi-Dimensional Hawkes Process and Temporal Model
Nov 15, 2024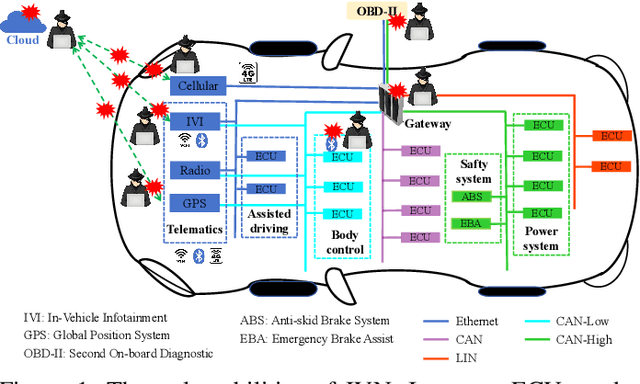

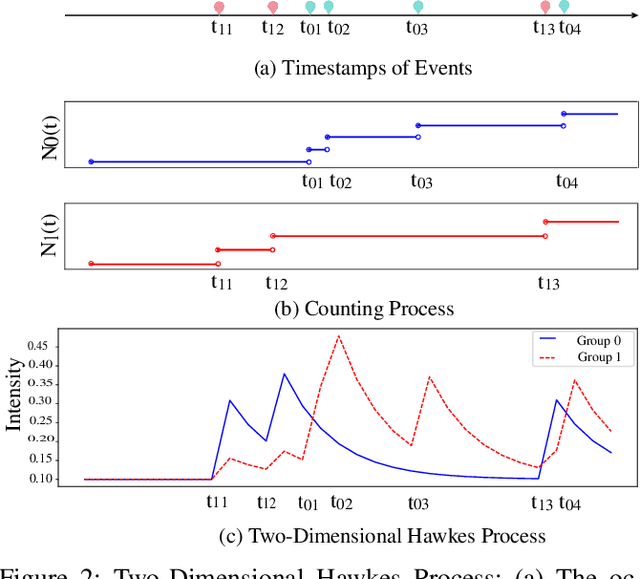
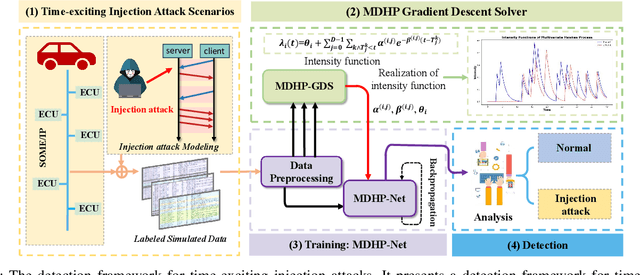
The integration of intelligent and connected technologies in modern vehicles, while offering enhanced functionalities through Electronic Control Unit and interfaces like OBD-II and telematics, also exposes the vehicle's in-vehicle network (IVN) to potential cyberattacks. In this paper, we consider a specific type of cyberattack known as the injection attack. As demonstrated by empirical data from real-world cybersecurity adversarial competitions(available at https://mimic2024.xctf.org.cn/race/qwmimic2024 ), these injection attacks have excitation effect over time, gradually manipulating network traffic and disrupting the vehicle's normal functioning, ultimately compromising both its stability and safety. To profile the abnormal behavior of attackers, we propose a novel injection attack detector to extract long-term features of attack behavior. Specifically, we first provide a theoretical analysis of modeling the time-excitation effects of the attack using Multi-Dimensional Hawkes Process (MDHP). A gradient descent solver specifically tailored for MDHP, MDHP-GDS, is developed to accurately estimate optimal MDHP parameters. We then propose an injection attack detector, MDHP-Net, which integrates optimal MDHP parameters with MDHP-LSTM blocks to enhance temporal feature extraction. By introducing MDHP parameters, MDHP-Net captures complex temporal features that standard Long Short-Term Memory (LSTM) cannot, enriching temporal dependencies within our customized structure. Extensive evaluations demonstrate the effectiveness of our proposed detection approach.
Contextual Representation Anchor Network to Alleviate Selection Bias in Few-Shot Drug Discovery
Oct 29, 2024In the drug discovery process, the low success rate of drug candidate screening often leads to insufficient labeled data, causing the few-shot learning problem in molecular property prediction. Existing methods for few-shot molecular property prediction overlook the sample selection bias, which arises from non-random sample selection in chemical experiments. This bias in data representativeness leads to suboptimal performance. To overcome this challenge, we present a novel method named contextual representation anchor Network (CRA), where an anchor refers to a cluster center of the representations of molecules and serves as a bridge to transfer enriched contextual knowledge into molecular representations and enhance their expressiveness. CRA introduces a dual-augmentation mechanism that includes context augmentation, which dynamically retrieves analogous unlabeled molecules and captures their task-specific contextual knowledge to enhance the anchors, and anchor augmentation, which leverages the anchors to augment the molecular representations. We evaluate our approach on the MoleculeNet and FS-Mol benchmarks, as well as in domain transfer experiments. The results demonstrate that CRA outperforms the state-of-the-art by 2.60% and 3.28% in AUC and $\Delta$AUC-PR metrics, respectively, and exhibits superior generalization capabilities.
Dual-Label Learning With Irregularly Present Labels
Oct 21, 2024In multi-task learning, we often encounter the case when the presence of labels across samples exhibits irregular patterns: samples can be fully labeled, partially labeled or unlabeled. Taking drug analysis as an example, multiple toxicity properties of a drug molecule may not be concurrently available due to experimental limitations. It triggers a demand for a new training and inference mechanism that could accommodate irregularly present labels and maximize the utility of any available label information. In this work, we focus on the two-label learning task, and propose a novel training and inference framework, Dual-Label Learning (DLL). The DLL framework formulates the problem into a dual-function system, in which the two functions should simultaneously satisfy standard supervision, structural duality and probabilistic duality. DLL features a dual-tower model architecture that explicitly captures the information exchange between labels, aimed at maximizing the utility of partially available labels in understanding label correlation. During training, label imputation for missing labels is conducted as part of the forward propagation process, while during inference, labels are regarded as unknowns of a bivariate system of equations and are solved jointly. Theoretical analysis guarantees the feasibility of DLL, and extensive experiments are conducted to verify that by explicitly modeling label correlation and maximizing the utility of available labels, our method makes consistently better predictions than baseline approaches by up to a 10% gain in F1-score or MAPE. Remarkably, our method provided with data at a label missing rate as high as 60% can achieve similar or even better results than baseline approaches at a label missing rate of only 10%.