 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInTrain: Intrinsic Trainability for Zero-Cost Neural Architecture Search
Jun 17, 2026Training-free neural architecture search promises efficient discovery of high-performance networks without costly training. However, existing zero-cost proxies rely on fragmented heuristics that fail to capture the fundamental question: what makes an architecture trainable? This paper introduces Intrinsic Trainability (InTrain), a unified theoretical proxy that formalizes trainability as an architectural invariant emerging from two synergistic components: geometric capacity and optimization resilience. We operationalize intrinsic trainability through analysis of neural information processing. Geometric capacity is quantified via the participation ratio of activation covariance eigenspectrum, capturing the effective dimensionality of representation manifolds. Optimization resilience is measured through cumulative gradient health, assessing the robustness of backpropagation across network depth. InTrain synthesizes these dimensions through a scale-invariant multiplicative coupling, which we hypothesize is essential for capturing their synergistic, non-additive relationship. Extensive experiments on standard NAS benchmarks and search spaces demonstrate that InTrain achieves ranking correlations on par with state-of-the-art ensemble-based proxies and outperforms other single-metric methods.
MedCoRAG: Interpretable Hepatology Diagnosis via Hybrid Evidence Retrieval and Multispecialty Consensus
Mar 05, 2026Diagnosing hepatic diseases accurately and interpretably is critical, yet it remains challenging in real-world clinical settings. Existing AI approaches for clinical diagnosis often lack transparency, structured reasoning, and deployability. Recent efforts have leveraged large language models (LLMs), retrieval-augmented generation (RAG), and multi-agent collaboration. However, these approaches typically retrieve evidence from a single source and fail to support iterative, role-specialized deliberation grounded in structured clinical data. To address this, we propose MedCoRAG (i.e., Medical Collaborative RAG), an end-to-end framework that generates diagnostic hypotheses from standardized abnormal findings and constructs a patient-specific evidence package by jointly retrieving and pruning UMLS knowledge graph paths and clinical guidelines. It then performs Multi-Agent Collaborative Reasoning: a Router Agent dynamically dispatches Specialist Agents based on case complexity; these agents iteratively reason over the evidence and trigger targeted re-retrievals when needed, while a Generalist Agent synthesizes all deliberations into a traceable consensus diagnosis that emulates multidisciplinary consultation. Experimental results on hepatic disease cases from MIMIC-IV show that MedCoRAG outperforms existing methods and closed-source models in both diagnostic performance and reasoning interpretability.
SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Jun 09, 2025Recent advances in large language models (LLMs) and vision-language models (VLMs) have enabled powerful autonomous agents capable of complex reasoning and multi-modal tool use. Despite their growing capabilities, today's agent frameworks remain fragile, lacking principled mechanisms for secure information flow, reliability, and multi-agent coordination. In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments. By constraining LLM reasoning to respect these security labels, SAFEFLOW prevents untrusted or adversarial inputs from contaminating high-integrity decisions. To ensure robustness in concurrent multi-agent settings, SAFEFLOW introduces transactional execution, conflict resolution, and secure scheduling over shared state, preserving global consistency across agents. We further introduce mechanisms, including write-ahead logging, rollback, and secure caches, that further enhance resilience against runtime errors and policy violations. To validate the performances, we built SAFEFLOWBENCH, a comprehensive benchmark suite designed to evaluate agent reliability under adversarial, noisy, and concurrent operational conditions. Extensive experiments demonstrate that agents built with SAFEFLOW maintain impressive task performance and security guarantees even in hostile environments, substantially outperforming state-of-the-art. Together, SAFEFLOW and SAFEFLOWBENCH lay the groundwork for principled, robust, and secure agent ecosystems, advancing the frontier of reliable autonomy.
Improve Knowledge Distillation via Label Revision and Data Selection
Apr 03, 2024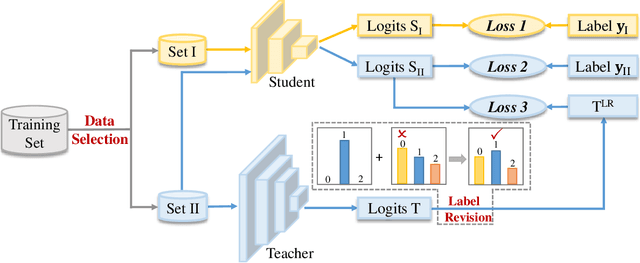
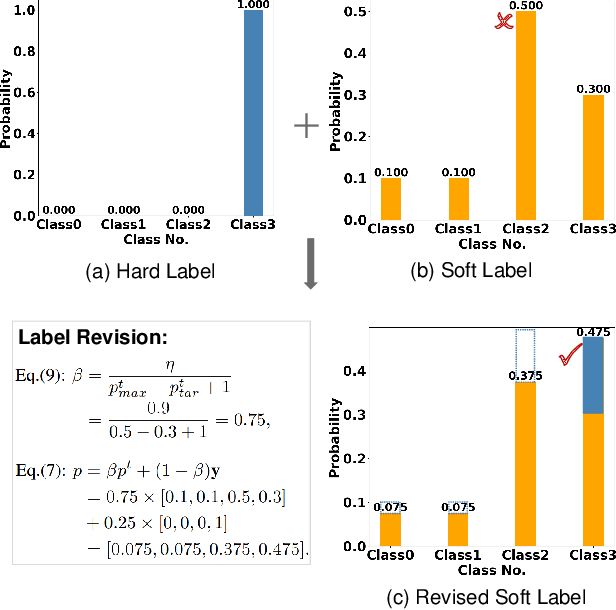
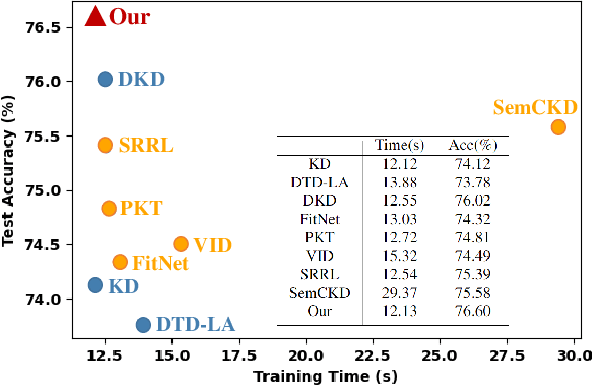

Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Feature Fusion from Head to Tail: an Extreme Augmenting Strategy for Long-Tailed Visual Recognition
Jun 12, 2023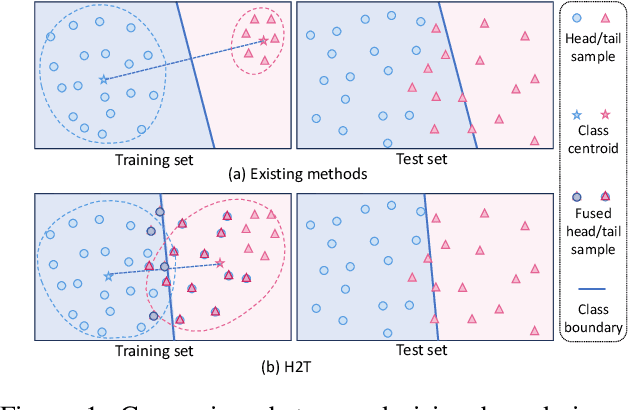
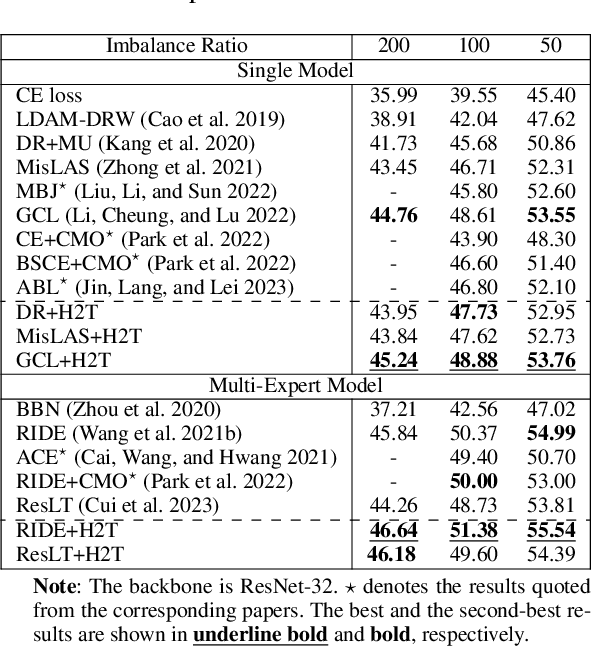
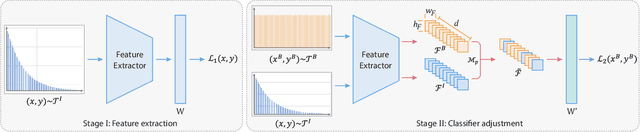

The imbalanced distribution of long-tailed data poses a challenge for deep neural networks, as models tend to prioritize correctly classifying head classes over others so that perform poorly on tail classes. The lack of semantics for tail classes is one of the key factors contributing to their low recognition accuracy. To rectify this issue, we propose to augment tail classes by borrowing the diverse semantic information from head classes, referred to as head-to-tail fusion (H2T). We randomly replace a portion of the feature maps of the tail class with those of the head class. The fused feature map can effectively enhance the diversity of tail classes by incorporating features from head classes that are relevant to them. The proposed method is easy to implement due to its additive fusion module, making it highly compatible with existing long-tail recognition methods for further performance boosting. Extensive experiments on various long-tailed benchmarks demonstrate the effectiveness of the proposed H2T. The source code is temporarily available at https://github.com/Keke921/H2T.
Adjusting Logit in Gaussian Form for Long-Tailed Visual Recognition
May 18, 2023



It is not uncommon that real-world data are distributed with a long tail. For such data, the learning of deep neural networks becomes challenging because it is hard to classify tail classes correctly. In the literature, several existing methods have addressed this problem by reducing classifier bias provided that the features obtained with long-tailed data are representative enough. However, we find that training directly on long-tailed data leads to uneven embedding space. That is, the embedding space of head classes severely compresses that of tail classes, which is not conducive to subsequent classifier learning. %further improving model performance. This paper therefore studies the problem of long-tailed visual recognition from the perspective of feature level. We introduce feature augmentation to balance the embedding distribution. The features of different classes are perturbed with varying amplitudes in Gaussian form. Based on these perturbed features, two novel logit adjustment methods are proposed to improve model performance at a modest computational overhead. Subsequently, the distorted embedding spaces of all classes can be calibrated. In such balanced-distributed embedding spaces, the biased classifier can be eliminated by simply retraining the classifier with class-balanced sampling data. Extensive experiments conducted on benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art ones.
MTFH: A Matrix Tri-Factorization Hashing Framework for Efficient Cross-Modal Retrieval
May 04, 2018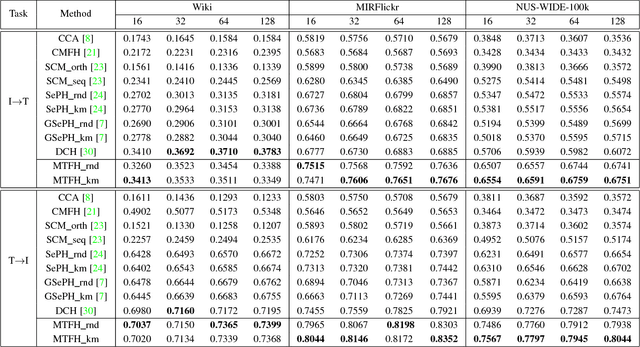
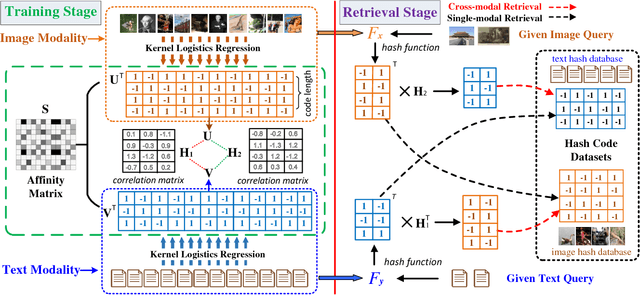
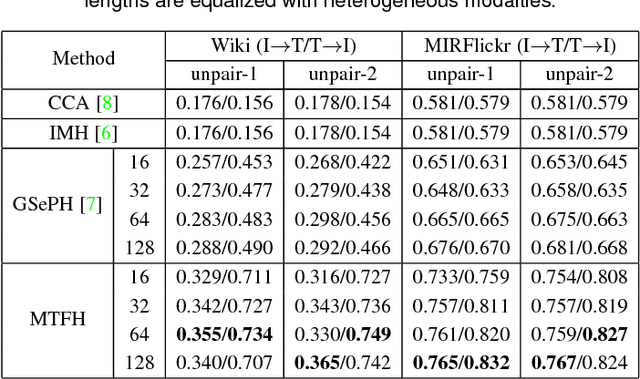
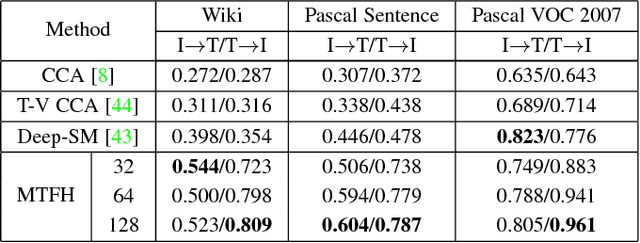
Hashing has recently sparked a great revolution in cross-modal retrieval due to its low storage cost and high query speed. Most existing cross-modal hashing methods learn unified hash codes in a common Hamming space to represent all multi-modal data and make them intuitively comparable. However, such unified hash codes could inherently sacrifice their representation scalability because the data from different modalities may not have one-to-one correspondence and could be stored more efficiently by different hash codes of unequal lengths. To mitigate this problem, this paper proposes a generalized and flexible cross-modal hashing framework, termed Matrix Tri-Factorization Hashing (MTFH), which not only preserves the semantic similarity between the multi-modal data points, but also works seamlessly in various settings including paired or unpaired multi-modal data, and equal or varying hash length encoding scenarios. Specifically, MTFH exploits an efficient objective function to jointly learn the flexible modality-specific hash codes with different length settings, while simultaneously excavating two semantic correlation matrices to ensure heterogeneous data comparable. As a result, the derived hash codes are more semantically meaningful for various challenging cross-modal retrieval tasks. Extensive experiments evaluated on public benchmark datasets highlight the superiority of MTFH under various retrieval scenarios and show its very competitive performance with the state-of-the-arts.