 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTFH: A Matrix Tri-Factorization Hashing Framework for Efficient Cross-Modal Retrieval
Paper and Code
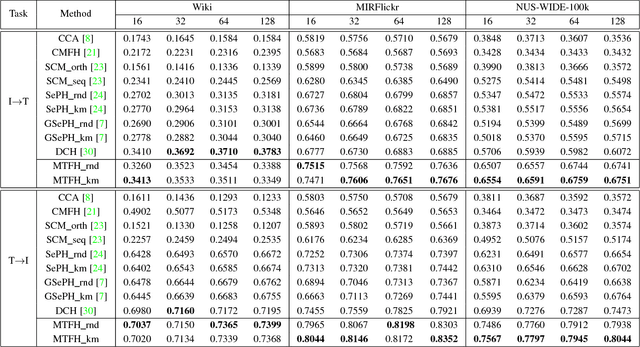
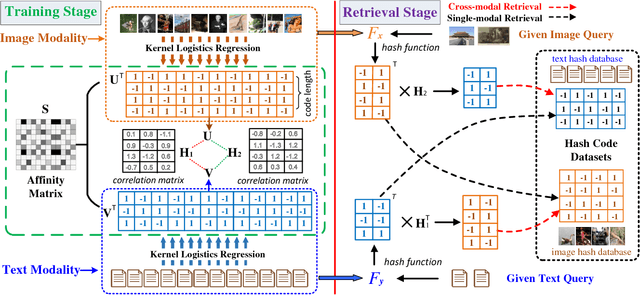
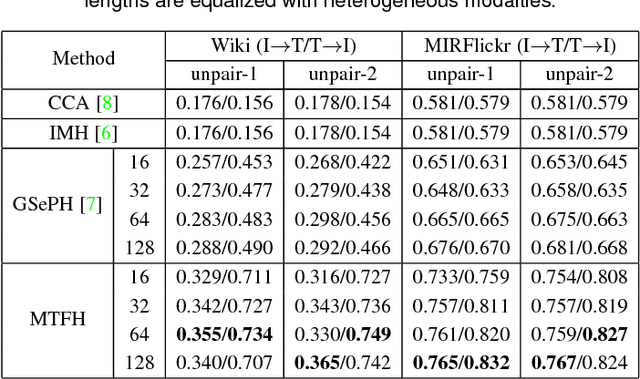
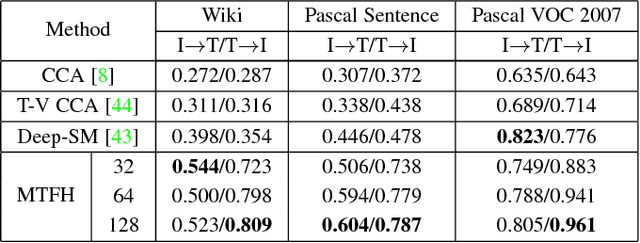
Hashing has recently sparked a great revolution in cross-modal retrieval due to its low storage cost and high query speed. Most existing cross-modal hashing methods learn unified hash codes in a common Hamming space to represent all multi-modal data and make them intuitively comparable. However, such unified hash codes could inherently sacrifice their representation scalability because the data from different modalities may not have one-to-one correspondence and could be stored more efficiently by different hash codes of unequal lengths. To mitigate this problem, this paper proposes a generalized and flexible cross-modal hashing framework, termed Matrix Tri-Factorization Hashing (MTFH), which not only preserves the semantic similarity between the multi-modal data points, but also works seamlessly in various settings including paired or unpaired multi-modal data, and equal or varying hash length encoding scenarios. Specifically, MTFH exploits an efficient objective function to jointly learn the flexible modality-specific hash codes with different length settings, while simultaneously excavating two semantic correlation matrices to ensure heterogeneous data comparable. As a result, the derived hash codes are more semantically meaningful for various challenging cross-modal retrieval tasks. Extensive experiments evaluated on public benchmark datasets highlight the superiority of MTFH under various retrieval scenarios and show its very competitive performance with the state-of-the-arts.