 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Knowledge Distillation via Label Revision and Data Selection
Apr 03, 2024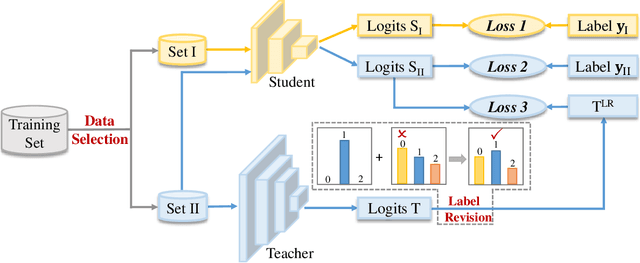
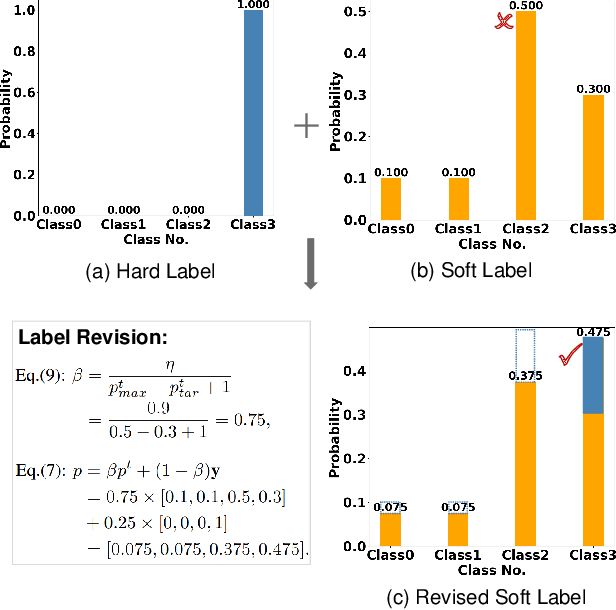
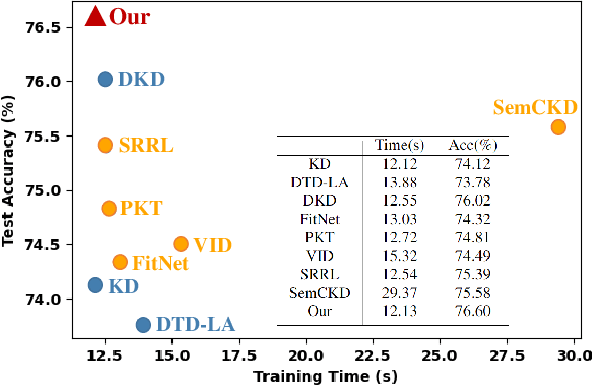

Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Feature Fusion from Head to Tail: an Extreme Augmenting Strategy for Long-Tailed Visual Recognition
Jun 12, 2023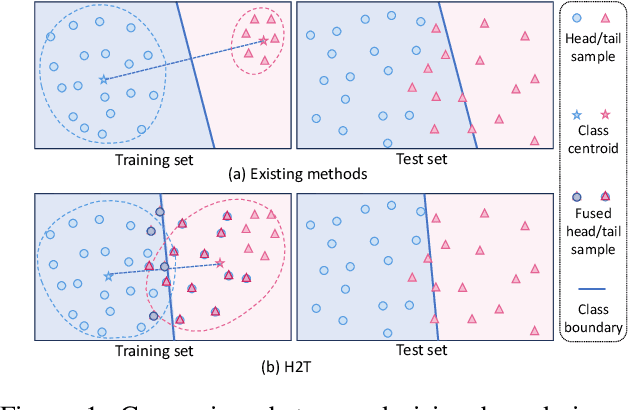
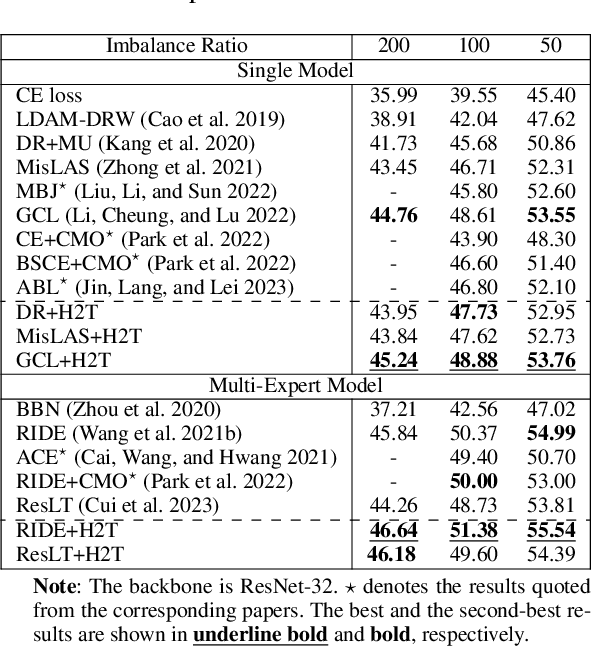
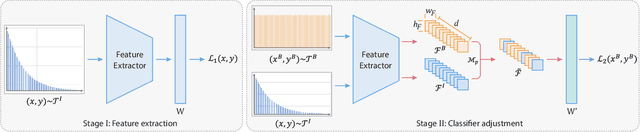

The imbalanced distribution of long-tailed data poses a challenge for deep neural networks, as models tend to prioritize correctly classifying head classes over others so that perform poorly on tail classes. The lack of semantics for tail classes is one of the key factors contributing to their low recognition accuracy. To rectify this issue, we propose to augment tail classes by borrowing the diverse semantic information from head classes, referred to as head-to-tail fusion (H2T). We randomly replace a portion of the feature maps of the tail class with those of the head class. The fused feature map can effectively enhance the diversity of tail classes by incorporating features from head classes that are relevant to them. The proposed method is easy to implement due to its additive fusion module, making it highly compatible with existing long-tail recognition methods for further performance boosting. Extensive experiments on various long-tailed benchmarks demonstrate the effectiveness of the proposed H2T. The source code is temporarily available at https://github.com/Keke921/H2T.
Adjusting Logit in Gaussian Form for Long-Tailed Visual Recognition
May 18, 2023



It is not uncommon that real-world data are distributed with a long tail. For such data, the learning of deep neural networks becomes challenging because it is hard to classify tail classes correctly. In the literature, several existing methods have addressed this problem by reducing classifier bias provided that the features obtained with long-tailed data are representative enough. However, we find that training directly on long-tailed data leads to uneven embedding space. That is, the embedding space of head classes severely compresses that of tail classes, which is not conducive to subsequent classifier learning. %further improving model performance. This paper therefore studies the problem of long-tailed visual recognition from the perspective of feature level. We introduce feature augmentation to balance the embedding distribution. The features of different classes are perturbed with varying amplitudes in Gaussian form. Based on these perturbed features, two novel logit adjustment methods are proposed to improve model performance at a modest computational overhead. Subsequently, the distorted embedding spaces of all classes can be calibrated. In such balanced-distributed embedding spaces, the biased classifier can be eliminated by simply retraining the classifier with class-balanced sampling data. Extensive experiments conducted on benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art ones.
Compact Neural Networks via Stacking Designed Basic Units
May 03, 2022
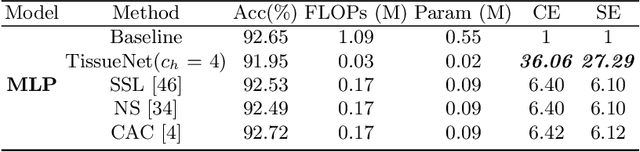


Unstructured pruning has the limitation of dealing with the sparse and irregular weights. By contrast, structured pruning can help eliminate this drawback but it requires complex criterion to determine which components to be pruned. To this end, this paper presents a new method termed TissueNet, which directly constructs compact neural networks with fewer weight parameters by independently stacking designed basic units, without requiring additional judgement criteria anymore. Given the basic units of various architectures, they are combined and stacked in a certain form to build up compact neural networks. We formulate TissueNet in diverse popular backbones for comparison with the state-of-the-art pruning methods on different benchmark datasets. Moreover, two new metrics are proposed to evaluate compression performance. Experiment results show that TissueNet can achieve comparable classification accuracy while saving up to around 80% FLOPs and 89.7% parameters. That is, stacking basic units provides a new promising way for network compression.
Compressing Deep Convolutional Neural Networks by Stacking Low-dimensional Binary Convolution Filters
Oct 06, 2020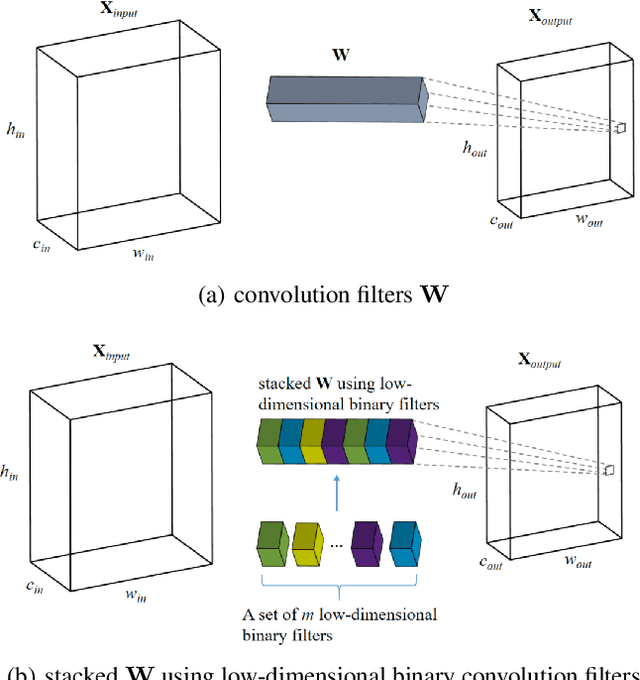

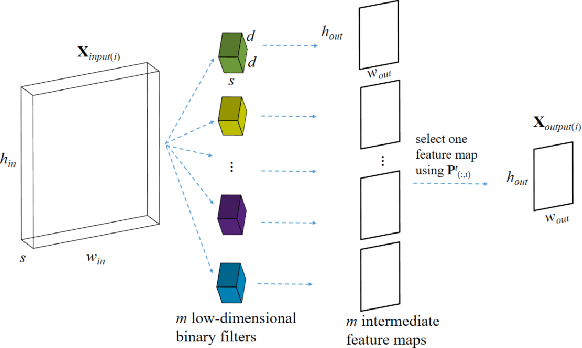
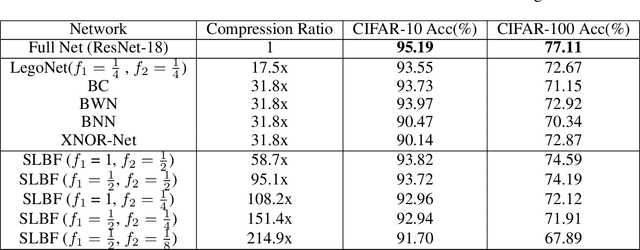
Deep Convolutional Neural Networks (CNN) have been successfully applied to many real-life problems. However, the huge memory cost of deep CNN models poses a great challenge of deploying them on memory-constrained devices (e.g., mobile phones). One popular way to reduce the memory cost of deep CNN model is to train binary CNN where the weights in convolution filters are either 1 or -1 and therefore each weight can be efficiently stored using a single bit. However, the compression ratio of existing binary CNN models is upper bounded by around 32. To address this limitation, we propose a novel method to compress deep CNN model by stacking low-dimensional binary convolution filters. Our proposed method approximates a standard convolution filter by selecting and stacking filters from a set of low-dimensional binary convolution filters. This set of low-dimensional binary convolution filters is shared across all filters for a given convolution layer. Therefore, our method will achieve much larger compression ratio than binary CNN models. In order to train our proposed model, we have theoretically shown that our proposed model is equivalent to select and stack intermediate feature maps generated by low-dimensional binary filters. Therefore, our proposed model can be efficiently trained using the split-transform-merge strategy. We also provide detailed analysis of the memory and computation cost of our model in model inference. We compared the proposed method with other five popular model compression techniques on two benchmark datasets. Our experimental results have demonstrated that our proposed method achieves much higher compression ratio than existing methods while maintains comparable accuracy.