 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSVBench: Benchmarking LLMs on Specification Generation Tasks for Operating System Verification
Apr 29, 2025



We introduce OSVBench, a new benchmark for evaluating Large Language Models (LLMs) in generating complete specification code pertaining to operating system kernel verification tasks. The benchmark first defines the specification generation problem into a program synthesis problem within a confined scope of syntax and semantics by providing LLMs with the programming model. The LLMs are required to understand the provided verification assumption and the potential syntax and semantics space to search for, then generate the complete specification for the potentially buggy operating system code implementation under the guidance of the high-level functional description of the operating system. This benchmark is built upon a real-world operating system kernel, Hyperkernel, and consists of 245 complex specification generation tasks in total, each is a long context task of about 20k-30k tokens. Our comprehensive evaluation of 12 LLMs exhibits the limited performance of the current LLMs on the specification generation tasks for operating system verification. Significant disparities in their performance on the benchmark highlight differences in their ability to handle long-context code generation tasks. The evaluation toolkit and benchmark are available at https://github.com/lishangyu-hkust/OSVBench.
KaSA: Knowledge-Aware Singular-Value Adaptation of Large Language Models
Dec 08, 2024The increasing sizes of large language models (LLMs) result in significant computational overhead and memory usage when adapting these models to specific tasks or domains. Various parameter-efficient fine-tuning (PEFT) methods have been devised to mitigate these challenges by training a small set of parameters for the task-specific updates of the model weights. Among PEFT methods, LoRA stands out for its simplicity and efficiency, inspiring the development of a series of variants. However, LoRA and its successors disregard the knowledge that is noisy or irrelevant to the targeted task, detrimentally impacting model performance and leading to suboptimality. To address this limitation, we introduce Knowledge-aware Singular-value Adaptation (KaSA), a PEFT method that leverages singular value decomposition (SVD) with knowledge-aware singular values to dynamically activate knowledge based on its relevance to the task at hand. We conduct extensive experiments across a range of LLMs on tasks spanning natural language understanding (NLU), generation (NLG), instruction following, and commonsense reasoning. The experimental results demonstrate that KaSA consistently outperforms FFT and 14 popular PEFT baselines across 16 benchmarks and 4 synthetic datasets, underscoring our method's efficacy and adaptability. The source code of our method is available at https://github.com/juyongjiang/KaSA.
LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs
Aug 24, 2024The widespread adoption of cloud-based proprietary large language models (LLMs) has introduced significant challenges, including operational dependencies, privacy concerns, and the necessity of continuous internet connectivity. In this work, we introduce an LLMOps pipeline, "LlamaDuo", for the seamless migration of knowledge and abilities from service-oriented LLMs to smaller, locally manageable models. This pipeline is crucial for ensuring service continuity in the presence of operational failures, strict privacy policies, or offline requirements. Our LlamaDuo involves fine-tuning a small language model against the service LLM using a synthetic dataset generated by the latter. If the performance of the fine-tuned model falls short of expectations, it is enhanced by further fine-tuning with additional similar data created by the service LLM. This iterative process guarantees that the smaller model can eventually match or even surpass the service LLM's capabilities in specific downstream tasks, offering a practical and scalable solution for managing AI deployments in constrained environments. Extensive experiments with leading edge LLMs are conducted to demonstrate the effectiveness, adaptability, and affordability of LlamaDuo across various downstream tasks. Our pipeline implementation is available at https://github.com/deep-diver/llamaduo.
A Survey on Mixture of Experts
Jun 26, 2024Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts
Apr 07, 2024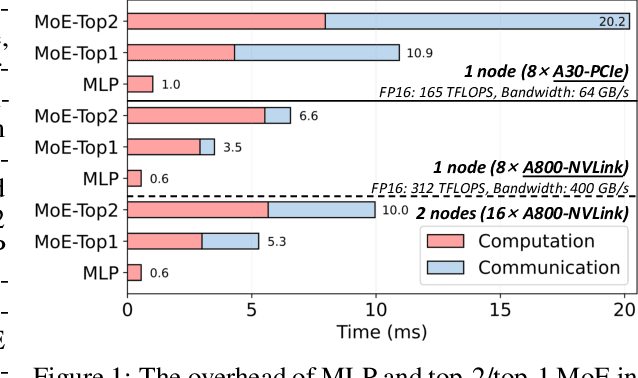
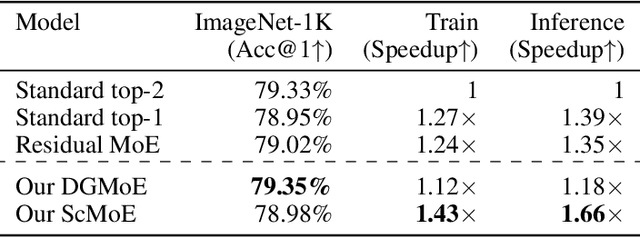
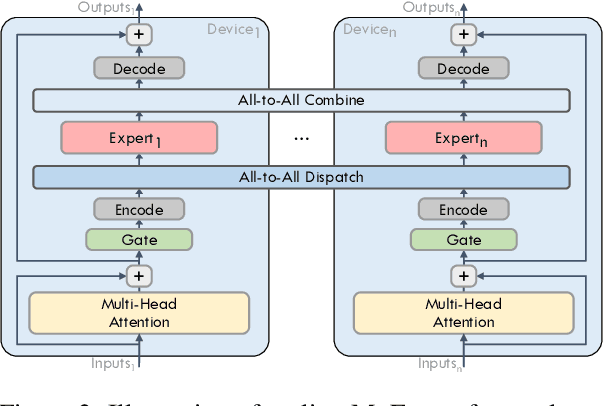
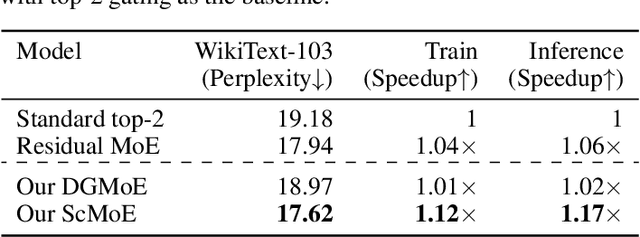
Expert parallelism has been introduced as a strategy to distribute the computational workload of sparsely-gated mixture-of-experts (MoE) models across multiple computing devices, facilitating the execution of these increasingly large-scale models. However, the All-to-All communication intrinsic to expert parallelism constitutes a significant overhead, diminishing the MoE models' efficiency. Current optimization approaches offer some relief, yet they are constrained by the sequential interdependence of communication and computation operations. To address this limitation, we present a novel shortcut-connected MoE architecture with overlapping parallel strategy, designated as ScMoE, which effectively decouples communication from its conventional sequence, allowing for a substantial overlap of 70% to 100% with computation. When compared with the prevalent top-2 MoE architecture, ScMoE demonstrates training speed improvements of 30% and 11%, and inference improvements of 40% and 15%, in our PCIe and NVLink hardware environments, respectively, where communication constitutes 60% and 15% of the total MoE time consumption. On the other hand, extensive experiments and theoretical analyses indicate that ScMoE not only achieves comparable but in some instances surpasses the model quality of existing approaches in vision and language tasks.
Feature-Balanced Loss for Long-Tailed Visual Recognition
May 18, 2023



Deep neural networks frequently suffer from performance degradation when the training data is long-tailed because several majority classes dominate the training, resulting in a biased model. Recent studies have made a great effort in solving this issue by obtaining good representations from data space, but few of them pay attention to the influence of feature norm on the predicted results. In this paper, we therefore address the long-tailed problem from feature space and thereby propose the feature-balanced loss. Specifically, we encourage larger feature norms of tail classes by giving them relatively stronger stimuli. Moreover, the stimuli intensity is gradually increased in the way of curriculum learning, which improves the generalization of the tail classes, meanwhile maintaining the performance of the head classes. Extensive experiments on multiple popular long-tailed recognition benchmarks demonstrate that the feature-balanced loss achieves superior performance gains compared with the state-of-the-art methods.
Dynamic Adaptive and Adversarial Graph Convolutional Network for Traffic Forecasting
Aug 05, 2022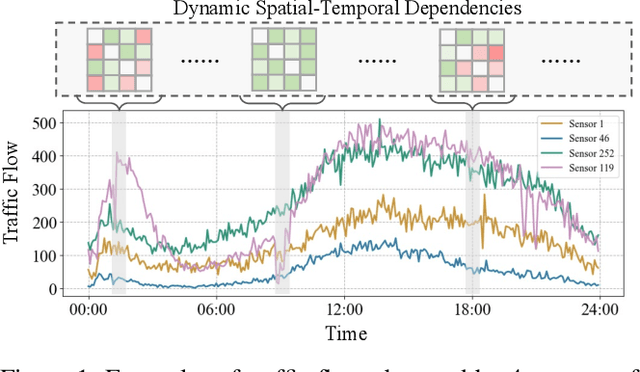
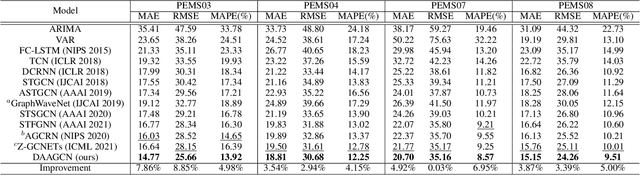

Traffic forecasting is challenging due to dynamic and complicated spatial-temporal dependencies. However, existing methods still suffer from two critical limitations. Firstly, many approaches typically utilize static pre-defined or adaptively learned spatial graphs to capture dynamic spatial-temporal dependencies in the traffic system, which limits the flexibility and only captures shared patterns for the whole time, thus leading to sub-optimal performance. In addition, most approaches individually and independently consider the absolute error between ground truth and predictions at each time step, which fails to maintain the global properties and statistics of time series as a whole and results in trend discrepancy between ground truth and predictions. To this end, in this paper, we propose a Dynamic Adaptive and Adversarial Graph Convolutional Network (DAAGCN), which combines Graph Convolution Networks (GCNs) with Generative Adversarial Networks (GANs) for traffic forecasting. Specifically, DAAGCN leverages a universal paradigm with a gate module to integrate time-varying embeddings with node embeddings to generate dynamic adaptive graphs for inferring spatial-temporal dependencies at each time step. Then, two discriminators are designed to maintain the consistency of the global properties and statistics of predicted time series with ground truth at the sequence and graph levels. Extensive experiments on four benchmark datasets manifest that DAAGCN outperforms the state-of-the-art by average 5.05%, 3.80%, and 5.27%, in terms of MAE, RMSE, and MAPE, meanwhile, speeds up convergence up to 9 times. Code is available at https://github.com/juyongjiang/DAAGCN.
AdaMCT: Adaptive Mixture of CNN-Transformer for Sequential Recommendation
May 19, 2022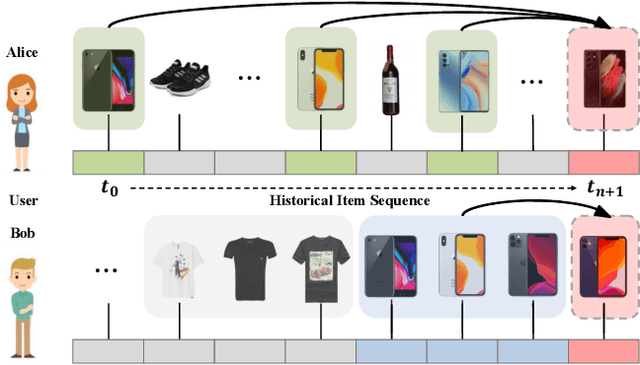
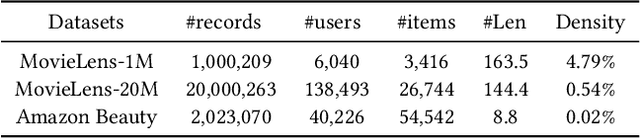
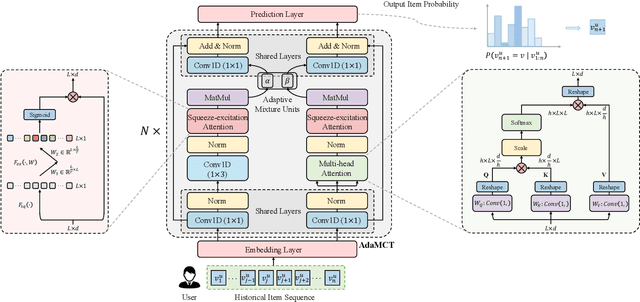
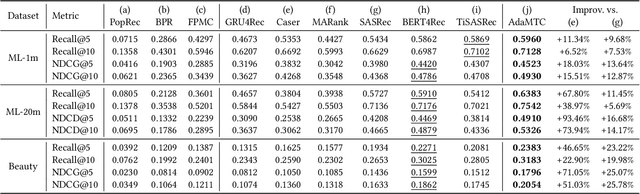
Sequential recommendation (SR) aims to model users' dynamic preferences from their historical interactions. Recently, Transformer and convolution neural networks (CNNs) have shown great success in learning representations for SR. Nevertheless, Transformer mainly focus on capturing content-based global interactions, while CNNs effectively exploit local features in practical recommendation scenarios. Thus, how to effectively aggregate CNNs and Transformer to model both \emph{local} and \emph{global} dependencies of historical item sequence still remains an open challenge and is rarely studied in SR. To this regard, we inject locality inductive bias into Transformer by combining its global attention mechanism with a local convolutional filter, and adaptively determine the mixing importance on a personalized basis through a module and layer-aware adaptive mixture units, named AdaMCT. Moreover, considering that softmax-based attention may encourage unimodal activation, we introduce the Squeeze-Excitation Attention (with sigmoid activation) into sequential recommendation to capture multiple relevant items (keys) simultaneously. Extensive experiments on three widely used benchmark datasets demonstrate that AdaMCT significantly outperforms the previous Transformer and CNNs-based models by an average of 18.46% and 60.85% respectively in terms of NDCG@5 and achieves state-of-the-art performance.
Compact Neural Networks via Stacking Designed Basic Units
May 03, 2022
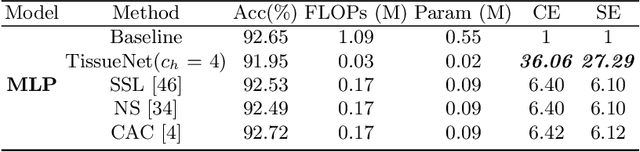


Unstructured pruning has the limitation of dealing with the sparse and irregular weights. By contrast, structured pruning can help eliminate this drawback but it requires complex criterion to determine which components to be pruned. To this end, this paper presents a new method termed TissueNet, which directly constructs compact neural networks with fewer weight parameters by independently stacking designed basic units, without requiring additional judgement criteria anymore. Given the basic units of various architectures, they are combined and stacked in a certain form to build up compact neural networks. We formulate TissueNet in diverse popular backbones for comparison with the state-of-the-art pruning methods on different benchmark datasets. Moreover, two new metrics are proposed to evaluate compression performance. Experiment results show that TissueNet can achieve comparable classification accuracy while saving up to around 80% FLOPs and 89.7% parameters. That is, stacking basic units provides a new promising way for network compression.