 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Mar 07, 2025The Mixture of Experts (MoE) is an effective architecture for scaling large language models by leveraging sparse expert activation, optimizing the trade-off between performance and efficiency. However, under expert parallelism, MoE suffers from inference inefficiencies due to imbalanced token-to-expert assignment, where some experts are overloaded while others remain underutilized. This imbalance leads to poor resource utilization and increased latency, as the most burdened expert dictates the overall delay, a phenomenon we define as the \textbf{\textit{Straggler Effect}}. To mitigate this, we propose Capacity-Aware Inference, including two key techniques: (1) \textbf{\textit{Capacity-Aware Token Drop}}, which discards overloaded tokens to regulate the maximum latency of MoE, and (2) \textbf{\textit{Capacity-Aware Token Reroute}}, which reallocates overflowed tokens to underutilized experts, balancing the token distribution. These techniques collectively optimize both high-load and low-load expert utilization, leading to a more efficient MoE inference pipeline. Extensive experiments demonstrate the effectiveness of our methods, showing significant improvements in inference efficiency, e.g., 0.2\% average performance increase and a 1.94$\times$ inference speedup on Mixtral-8$\times$7B-Instruct.
Partial Experts Checkpoint: Efficient Fault Tolerance for Sparse Mixture-of-Experts Model Training
Aug 08, 2024As large language models continue to scale up, the imperative for fault tolerance in distributed deep learning systems intensifies, becoming a focal area of AI infrastructure research. Checkpoint has emerged as the predominant fault tolerance strategy, with extensive studies dedicated to optimizing its efficiency. However, the advent of the sparse Mixture-of-Experts (MoE) model presents new challenges for traditional checkpoint techniques due to the substantial increase in model size, despite comparable computational demands to dense models. Breaking new ground in the realm of efficient fault tolerance for MoE model training, we introduce a novel Partial Experts Checkpoint (PEC) mechanism alongside a corresponding PEC fault-tolerant system. Our approach strategically checkpoints a selected subset of experts, thereby significantly reducing the checkpoint size for MoE models to a level comparable with that of dense models. The empirical analysis on our 8-expert GPT-MoE model demonstrates that the proposed PEC approach facilitates a substantial 54.2% decrease in the size of non-redundant checkpoint (no data-parallel duplication), without compromising the final model quality. Moreover, our PEC fault-tolerant system achieves a 76.9% reduction in checkpoint workload per data-parallel distributed rank, thereby correspondingly diminishing the checkpointing time and facilitating complete overlap with the training process.
A Survey on Mixture of Experts
Jun 26, 2024Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts
Apr 07, 2024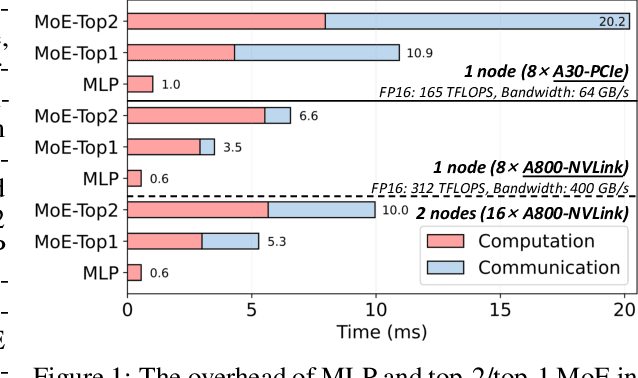
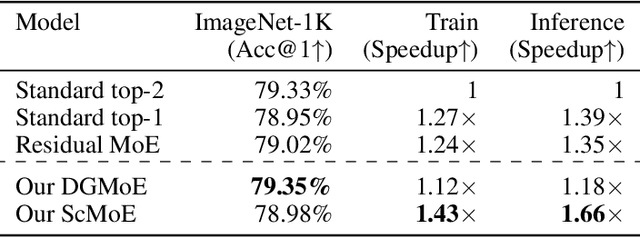
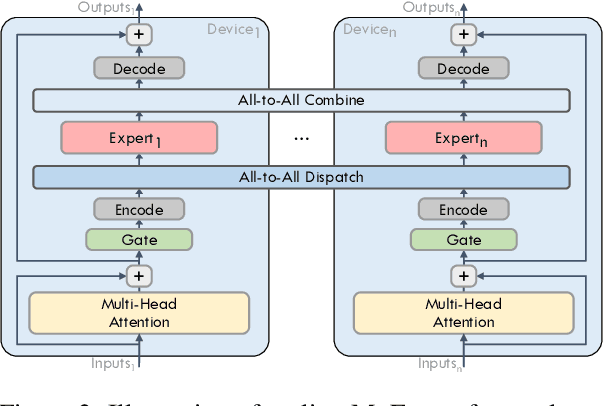
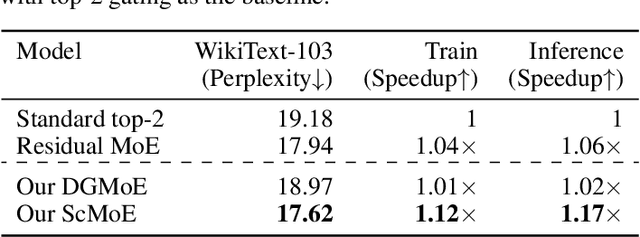
Expert parallelism has been introduced as a strategy to distribute the computational workload of sparsely-gated mixture-of-experts (MoE) models across multiple computing devices, facilitating the execution of these increasingly large-scale models. However, the All-to-All communication intrinsic to expert parallelism constitutes a significant overhead, diminishing the MoE models' efficiency. Current optimization approaches offer some relief, yet they are constrained by the sequential interdependence of communication and computation operations. To address this limitation, we present a novel shortcut-connected MoE architecture with overlapping parallel strategy, designated as ScMoE, which effectively decouples communication from its conventional sequence, allowing for a substantial overlap of 70% to 100% with computation. When compared with the prevalent top-2 MoE architecture, ScMoE demonstrates training speed improvements of 30% and 11%, and inference improvements of 40% and 15%, in our PCIe and NVLink hardware environments, respectively, where communication constitutes 60% and 15% of the total MoE time consumption. On the other hand, extensive experiments and theoretical analyses indicate that ScMoE not only achieves comparable but in some instances surpasses the model quality of existing approaches in vision and language tasks.