 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMRT: Learning Accurate Feature Matching with Reconciliatory Transformer
Oct 20, 2023Local Feature Matching, an essential component of several computer vision tasks (e.g., structure from motion and visual localization), has been effectively settled by Transformer-based methods. However, these methods only integrate long-range context information among keypoints with a fixed receptive field, which constrains the network from reconciling the importance of features with different receptive fields to realize complete image perception, hence limiting the matching accuracy. In addition, these methods utilize a conventional handcrafted encoding approach to integrate the positional information of keypoints into the visual descriptors, which limits the capability of the network to extract reliable positional encoding message. In this study, we propose Feature Matching with Reconciliatory Transformer (FMRT), a novel Transformer-based detector-free method that reconciles different features with multiple receptive fields adaptively and utilizes parallel networks to realize reliable positional encoding. Specifically, FMRT proposes a dedicated Reconciliatory Transformer (RecFormer) that consists of a Global Perception Attention Layer (GPAL) to extract visual descriptors with different receptive fields and integrate global context information under various scales, Perception Weight Layer (PWL) to measure the importance of various receptive fields adaptively, and Local Perception Feed-forward Network (LPFFN) to extract deep aggregated multi-scale local feature representation. Extensive experiments demonstrate that FMRT yields extraordinary performance on multiple benchmarks, including pose estimation, visual localization, homography estimation, and image matching.
OFVL-MS: Once for Visual Localization across Multiple Indoor Scenes
Aug 23, 2023



In this work, we seek to predict camera poses across scenes with a multi-task learning manner, where we view the localization of each scene as a new task. We propose OFVL-MS, a unified framework that dispenses with the traditional practice of training a model for each individual scene and relieves gradient conflict induced by optimizing multiple scenes collectively, enabling efficient storage yet precise visual localization for all scenes. Technically, in the forward pass of OFVL-MS, we design a layer-adaptive sharing policy with a learnable score for each layer to automatically determine whether the layer is shared or not. Such sharing policy empowers us to acquire task-shared parameters for a reduction of storage cost and task-specific parameters for learning scene-related features to alleviate gradient conflict. In the backward pass of OFVL-MS, we introduce a gradient normalization algorithm that homogenizes the gradient magnitude of the task-shared parameters so that all tasks converge at the same pace. Furthermore, a sparse penalty loss is applied on the learnable scores to facilitate parameter sharing for all tasks without performance degradation. We conduct comprehensive experiments on multiple benchmarks and our new released indoor dataset LIVL, showing that OFVL-MS families significantly outperform the state-of-the-arts with fewer parameters. We also verify that OFVL-MS can generalize to a new scene with much few parameters while gaining superior localization performance.
Poly-MOT: A Polyhedral Framework For 3D Multi-Object Tracking
Jul 31, 2023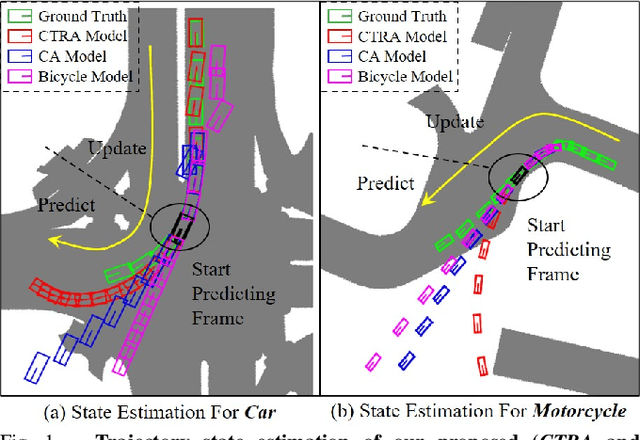
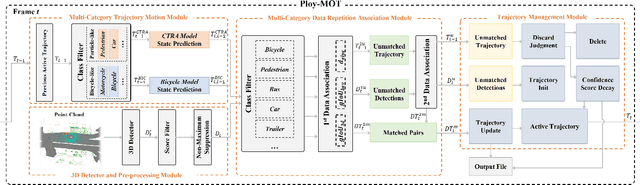
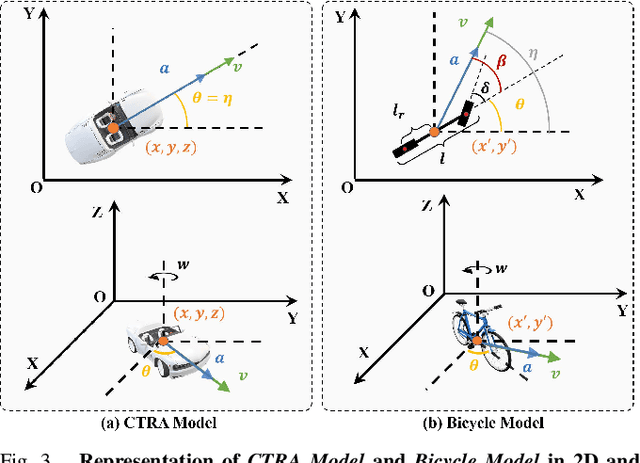

3D Multi-object tracking (MOT) empowers mobile robots to accomplish well-informed motion planning and navigation tasks by providing motion trajectories of surrounding objects. However, existing 3D MOT methods typically employ a single similarity metric and physical model to perform data association and state estimation for all objects. With large-scale modern datasets and real scenes, there are a variety of object categories that commonly exhibit distinctive geometric properties and motion patterns. In this way, such distinctions would enable various object categories to behave differently under the same standard, resulting in erroneous matches between trajectories and detections, and jeopardizing the reliability of downstream tasks (navigation, etc.). Towards this end, we propose Poly-MOT, an efficient 3D MOT method based on the Tracking-By-Detection framework that enables the tracker to choose the most appropriate tracking criteria for each object category. Specifically, Poly-MOT leverages different motion models for various object categories to characterize distinct types of motion accurately. We also introduce the constraint of the rigid structure of objects into a specific motion model to accurately describe the highly nonlinear motion of the object. Additionally, we introduce a two-stage data association strategy to ensure that objects can find the optimal similarity metric from three custom metrics for their categories and reduce missing matches. On the NuScenes dataset, our proposed method achieves state-of-the-art performance with 75.4\% AMOTA. The code is available at https://github.com/lixiaoyu2000/Poly-MOT
YOWOv2: A Stronger yet Efficient Multi-level Detection Framework for Real-time Spatio-temporal Action Detection
Feb 14, 2023Designing a real-time framework for the spatio-temporal action detection task is still a challenge. In this paper, we propose a novel real-time action detection framework, YOWOv2. In this new framework, YOWOv2 takes advantage of both the 3D backbone and 2D backbone for accurate action detection. A multi-level detection pipeline is designed to detect action instances of different scales. To achieve this goal, we carefully build a simple and efficient 2D backbone with a feature pyramid network to extract different levels of classification features and regression features. For the 3D backbone, we adopt the existing efficient 3D CNN to save development time. By combining 3D backbones and 2D backbones of different sizes, we design a YOWOv2 family including YOWOv2-Tiny, YOWOv2-Medium, and YOWOv2-Large. We also introduce the popular dynamic label assignment strategy and anchor-free mechanism to make the YOWOv2 consistent with the advanced model architecture design. With our improvement, YOWOv2 is significantly superior to YOWO, and can still keep real-time detection. Without any bells and whistles, YOWOv2 achieves 87.0 % frame mAP and 52.8 % video mAP with over 20 FPS on the UCF101-24. On the AVA, YOWOv2 achieves 21.7 % frame mAP with over 20 FPS. Our code is available on https://github.com/yjh0410/YOWOv2.
OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching
Feb 12, 2023Local feature matching is an essential component in many visual applications. In this work, we propose OAMatcher, a Tranformer-based detector-free method that imitates humans behavior to generate dense and accurate matches. Firstly, OAMatcher predicts overlapping areas to promote effective and clean global context aggregation, with the key insight that humans focus on the overlapping areas instead of the entire images after multiple observations when matching keypoints in image pairs. Technically, we first perform global information integration across all keypoints to imitate the humans behavior of observing the entire images at the beginning of feature matching. Then, we propose Overlapping Areas Prediction Module (OAPM) to capture the keypoints in co-visible regions and conduct feature enhancement among them to simulate that humans transit the focus regions from the entire images to overlapping regions, hence realizeing effective information exchange without the interference coming from the keypoints in non overlapping areas. Besides, since humans tend to leverage probability to determine whether the match labels are correct or not, we propose a Match Labels Weight Strategy (MLWS) to generate the coefficients used to appraise the reliability of the ground-truth match labels, while alleviating the influence of measurement noise coming from the data. Moreover, we integrate depth-wise convolution into Tranformer encoder layers to ensure OAMatcher extracts local and global feature representation concurrently. Comprehensive experiments demonstrate that OAMatcher outperforms the state-of-the-art methods on several benchmarks, while exhibiting excellent robustness to extreme appearance variants. The source code is available at https://github.com/DK-HU/OAMatcher.
DeepMatcher: A Deep Transformer-based Network for Robust and Accurate Local Feature Matching
Jan 08, 2023



Local feature matching between images remains a challenging task, especially in the presence of significant appearance variations, e.g., extreme viewpoint changes. In this work, we propose DeepMatcher, a deep Transformer-based network built upon our investigation of local feature matching in detector-free methods. The key insight is that local feature matcher with deep layers can capture more human-intuitive and simpler-to-match features. Based on this, we propose a Slimming Transformer (SlimFormer) dedicated for DeepMatcher, which leverages vector-based attention to model relevance among all keypoints and achieves long-range context aggregation in an efficient and effective manner. A relative position encoding is applied to each SlimFormer so as to explicitly disclose relative distance information, further improving the representation of keypoints. A layer-scale strategy is also employed in each SlimFormer to enable the network to assimilate message exchange from the residual block adaptively, thus allowing it to simulate the human behaviour that humans can acquire different matching cues each time they scan an image pair. To facilitate a better adaption of the SlimFormer, we introduce a Feature Transition Module (FTM) to ensure a smooth transition in feature scopes with different receptive fields. By interleaving the self- and cross-SlimFormer multiple times, DeepMatcher can easily establish pixel-wise dense matches at coarse level. Finally, we perceive the match refinement as a combination of classification and regression problems and design Fine Matches Module to predict confidence and offset concurrently, thereby generating robust and accurate matches. Experimentally, we show that DeepMatcher significantly outperforms the state-of-the-art methods on several benchmarks, demonstrating the superior matching capability of DeepMatcher.