 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOWOv2: A Stronger yet Efficient Multi-level Detection Framework for Real-time Spatio-temporal Action Detection
Feb 14, 2023Designing a real-time framework for the spatio-temporal action detection task is still a challenge. In this paper, we propose a novel real-time action detection framework, YOWOv2. In this new framework, YOWOv2 takes advantage of both the 3D backbone and 2D backbone for accurate action detection. A multi-level detection pipeline is designed to detect action instances of different scales. To achieve this goal, we carefully build a simple and efficient 2D backbone with a feature pyramid network to extract different levels of classification features and regression features. For the 3D backbone, we adopt the existing efficient 3D CNN to save development time. By combining 3D backbones and 2D backbones of different sizes, we design a YOWOv2 family including YOWOv2-Tiny, YOWOv2-Medium, and YOWOv2-Large. We also introduce the popular dynamic label assignment strategy and anchor-free mechanism to make the YOWOv2 consistent with the advanced model architecture design. With our improvement, YOWOv2 is significantly superior to YOWO, and can still keep real-time detection. Without any bells and whistles, YOWOv2 achieves 87.0 % frame mAP and 52.8 % video mAP with over 20 FPS on the UCF101-24. On the AVA, YOWOv2 achieves 21.7 % frame mAP with over 20 FPS. Our code is available on https://github.com/yjh0410/YOWOv2.
YOWO-Plus: An Incremental Improvement
Oct 20, 2022

In this technical report, we would like to introduce our updates to YOWO, a real-time method for spatio-temporal action detection. We make a bunch of little design changes to make it better. For network structure, we use the same ones of official implemented YOWO, including 3D-ResNext-101 and YOLOv2, but we use a better pretrained weight of our reimplemented YOLOv2, which is better than the official YOLOv2. We also optimize the label assignment used in YOWO. To accurately detection action instances, we deploy GIoU loss for box regression. After our incremental improvement, YOWO achieves 84.9\% frame mAP and 50.5\% video mAP on the UCF101-24, significantly higher than the official YOWO. On the AVA, our optimized YOWO achieves 20.6\% frame mAP with 16 frames, also exceeding the official YOWO. With 32 frames, our YOWO achieves 21.6 frame mAP with 25 FPS on an RTX 3090 GPU. We name the optimized YOWO as YOWO-Plus. Moreover, we replace the 3D-ResNext-101 with the efficient 3D-ShuffleNet-v2 to design a lightweight action detector, YOWO-Nano. YOWO-Nano achieves 81.0 \% frame mAP and 49.7\% video frame mAP with over 90 FPS on the UCF101-24. It also achieves 18.4 \% frame mAP with about 90 FPS on the AVA. As far as we know, YOWO-Nano is the fastest state-of-the-art action detector. Our code is available on https://github.com/yjh0410/PyTorch_YOWO.
CMF: Cascaded Multi-model Fusion for Referring Image Segmentation
Jun 16, 2021

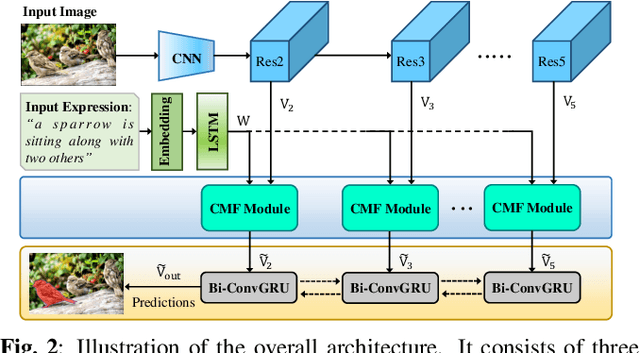
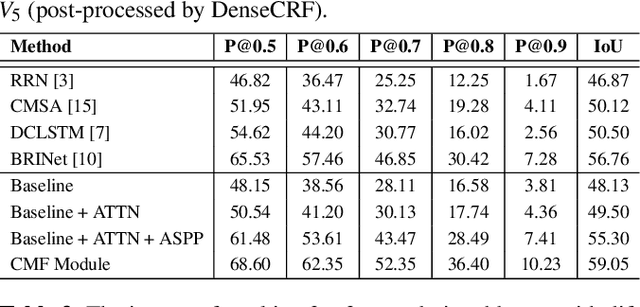
In this work, we address the task of referring image segmentation (RIS), which aims at predicting a segmentation mask for the object described by a natural language expression. Most existing methods focus on establishing unidirectional or directional relationships between visual and linguistic features to associate two modalities together, while the multi-scale context is ignored or insufficiently modeled. Multi-scale context is crucial to localize and segment those objects that have large scale variations during the multi-modal fusion process. To solve this problem, we propose a simple yet effective Cascaded Multi-modal Fusion (CMF) module, which stacks multiple atrous convolutional layers in parallel and further introduces a cascaded branch to fuse visual and linguistic features. The cascaded branch can progressively integrate multi-scale contextual information and facilitate the alignment of two modalities during the multi-modal fusion process. Experimental results on four benchmark datasets demonstrate that our method outperforms most state-of-the-art methods. Code is available at https://github.com/jianhua2022/CMF-Refseg.
Actor and Action Modular Network for Text-based Video Segmentation
Nov 02, 2020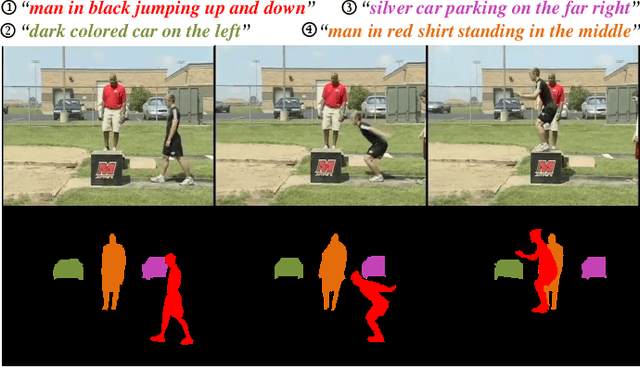

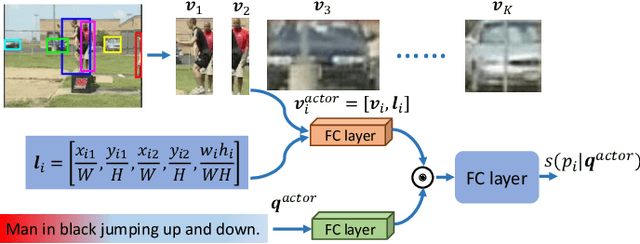

The actor and action semantic segmentation is a challenging problem that requires joint actor and action understanding, and learns to segment from pre-defined actor and action label pairs. However, existing methods for this task fail to distinguish those actors that have same super-category and identify the actor-action pairs that outside of the fixed actor and action vocabulary. Recent studies have extended this task using textual queries, instead of word-level actor-action pairs, to make the actor and action can be flexibly specified. In this paper, we focus on the text-based actor and action segmentation problem, which performs fine-grained actor and action understanding in the video. Previous works predicted segmentation masks from the merged heterogenous features of a given video and textual query, while they ignored that the linguistic variation of the textual query and visual semantic discrepancy of the video, and led to the asymmetric matching between convolved volumes of the video and the global query representation. To alleviate aforementioned problem, we propose a novel actor and action modular network that individually localizes the actor and action in two separate modules. We first learn the actor-/action-related content for the video and textual query, and then match them in a symmetrical manner to localize the target region. The target region includes the desired actor and action which is then fed into a fully convolutional network to predict the segmentation mask. The whole model enables joint learning for the actor-action matching and segmentation, and achieves the state-of-the-art performance on A2D Sentences and J-HMDB Sentences datasets.
The Learning of Fuzzy Cognitive Maps With Noisy Data: A Rapid and Robust Learning Method With Maximum Entropy
Aug 22, 2019


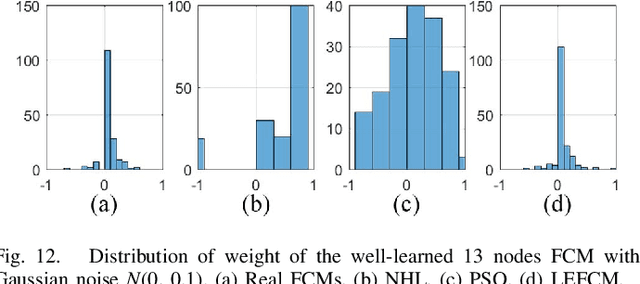
Numerous learning methods for fuzzy cognitive maps (FCMs), such as the Hebbian-based and the population-based learning methods, have been developed for modeling and simulating dynamic systems. However, these methods are faced with several obvious limitations. Most of these models are extremely time consuming when learning the large-scale FCMs with hundreds of nodes. Furthermore, the FCMs learned by those algorithms lack robustness when the experimental data contain noise. In addition, reasonable distribution of the weights is rarely considered in these algorithms, which could result in the reduction of the performance of the resulting FCM. In this article, a straightforward, rapid, and robust learning method is proposed to learn FCMs from noisy data, especially, to learn large-scale FCMs. The crux of the proposed algorithm is to equivalently transform the learning problem of FCMs to a classic-constrained convex optimization problem in which the least-squares term ensures the robustness of the well-learned FCM and the maximum entropy term regularizes the distribution of the weights of the well-learned FCM. A series of experiments covering two frequently used activation functions (the sigmoid and hyperbolic tangent functions) are performed on both synthetic datasets with noise and real-world datasets. The experimental results show that the proposed method is rapid and robust against data containing noise and that the well-learned weights have better distribution. In addition, the FCMs learned by the proposed method also exhibit superior performance in comparison with the existing methods. Index Terms-Fuzzy cognitive maps (FCMs), maximum entropy, noisy data, rapid and robust learning.
Deep Learning based Inter-Modality Image Registration Supervised by Intra-Modality Similarity
Apr 28, 2018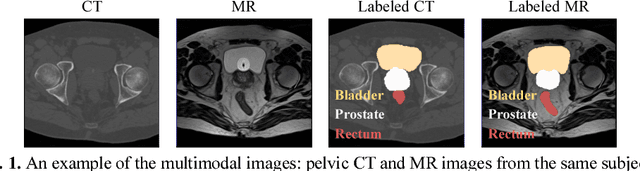
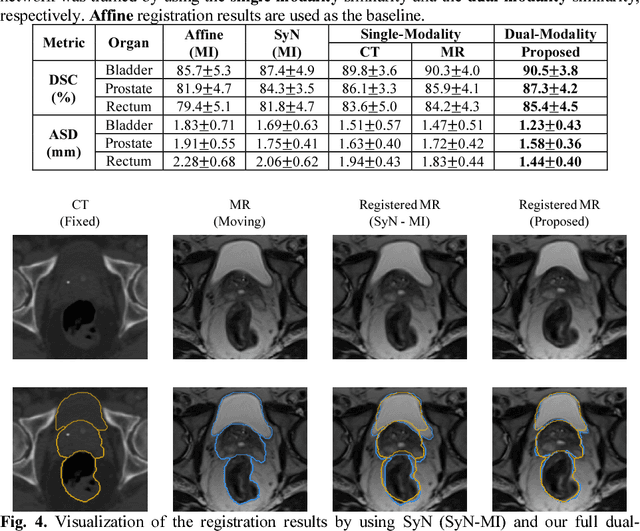
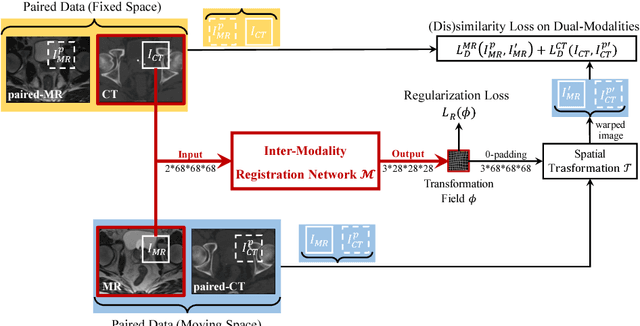
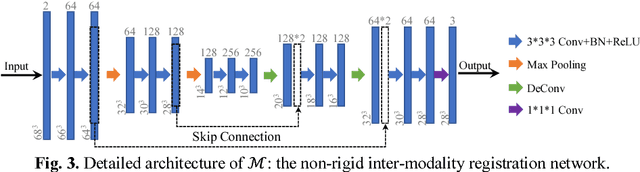
Non-rigid inter-modality registration can facilitate accurate information fusion from different modalities, but it is challenging due to the very different image appearances across modalities. In this paper, we propose to train a non-rigid inter-modality image registration network, which can directly predict the transformation field from the input multimodal images, such as CT and MR images. In particular, the training of our inter-modality registration network is supervised by intra-modality similarity metric based on the available paired data, which is derived from a pre-aligned CT and MR dataset. Specifically, in the training stage, to register the input CT and MR images, their similarity is evaluated on the warped MR image and the MR image that is paired with the input CT. So that, the intra-modality similarity metric can be directly applied to measure whether the input CT and MR images are well registered. Moreover, we use the idea of dual-modality fashion, in which we measure the similarity on both CT modality and MR modality. In this way, the complementary anatomies in both modalities can be jointly considered to more accurately train the inter-modality registration network. In the testing stage, the trained inter-modality registration network can be directly applied to register the new multimodal images without any paired data. Experimental results have shown that, the proposed method can achieve promising accuracy and efficiency for the challenging non-rigid inter-modality registration task and also outperforms the state-of-the-art approaches.