 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMF: Cascaded Multi-model Fusion for Referring Image Segmentation
Paper and Code


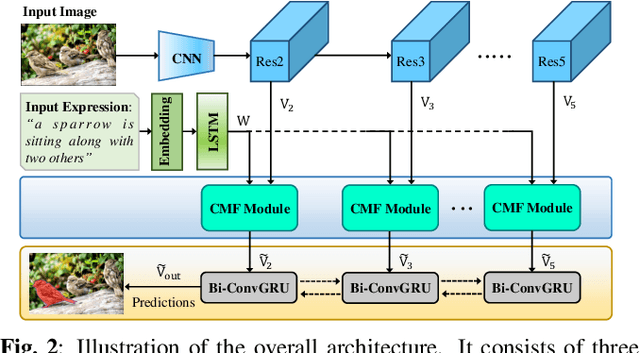
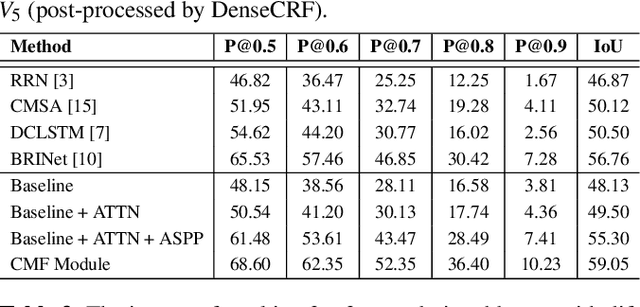
In this work, we address the task of referring image segmentation (RIS), which aims at predicting a segmentation mask for the object described by a natural language expression. Most existing methods focus on establishing unidirectional or directional relationships between visual and linguistic features to associate two modalities together, while the multi-scale context is ignored or insufficiently modeled. Multi-scale context is crucial to localize and segment those objects that have large scale variations during the multi-modal fusion process. To solve this problem, we propose a simple yet effective Cascaded Multi-modal Fusion (CMF) module, which stacks multiple atrous convolutional layers in parallel and further introduces a cascaded branch to fuse visual and linguistic features. The cascaded branch can progressively integrate multi-scale contextual information and facilitate the alignment of two modalities during the multi-modal fusion process. Experimental results on four benchmark datasets demonstrate that our method outperforms most state-of-the-art methods. Code is available at https://github.com/jianhua2022/CMF-Refseg.