 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor and Action Modular Network for Text-based Video Segmentation
Paper and Code
Nov 02, 2020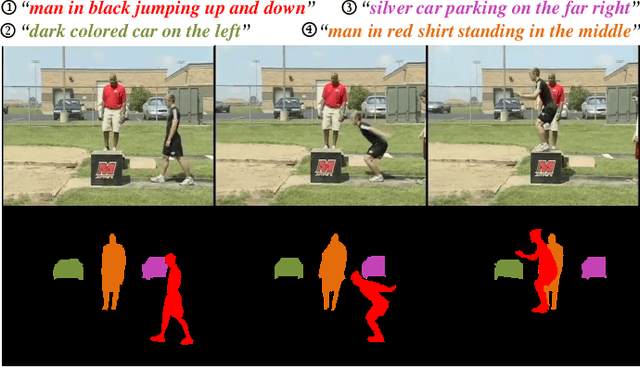

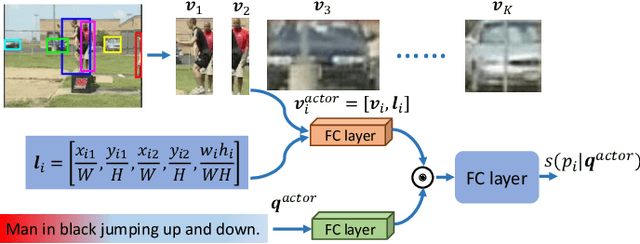

The actor and action semantic segmentation is a challenging problem that requires joint actor and action understanding, and learns to segment from pre-defined actor and action label pairs. However, existing methods for this task fail to distinguish those actors that have same super-category and identify the actor-action pairs that outside of the fixed actor and action vocabulary. Recent studies have extended this task using textual queries, instead of word-level actor-action pairs, to make the actor and action can be flexibly specified. In this paper, we focus on the text-based actor and action segmentation problem, which performs fine-grained actor and action understanding in the video. Previous works predicted segmentation masks from the merged heterogenous features of a given video and textual query, while they ignored that the linguistic variation of the textual query and visual semantic discrepancy of the video, and led to the asymmetric matching between convolved volumes of the video and the global query representation. To alleviate aforementioned problem, we propose a novel actor and action modular network that individually localizes the actor and action in two separate modules. We first learn the actor-/action-related content for the video and textual query, and then match them in a symmetrical manner to localize the target region. The target region includes the desired actor and action which is then fed into a fully convolutional network to predict the segmentation mask. The whole model enables joint learning for the actor-action matching and segmentation, and achieves the state-of-the-art performance on A2D Sentences and J-HMDB Sentences datasets.