 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGE-Guided Cross-Modality Contrastive Learning for Gadolinium-Free Cardiomyopathy Screening in Cine CMR
Aug 23, 2025Cardiomyopathy, a principal contributor to heart failure and sudden cardiac mortality, demands precise early screening. Cardiac Magnetic Resonance (CMR), recognized as the diagnostic 'gold standard' through multiparametric protocols, holds the potential to serve as an accurate screening tool. However, its reliance on gadolinium contrast and labor-intensive interpretation hinders population-scale deployment. We propose CC-CMR, a Contrastive Learning and Cross-Modal alignment framework for gadolinium-free cardiomyopathy screening using cine CMR sequences. By aligning the latent spaces of cine CMR and Late Gadolinium Enhancement (LGE) sequences, our model encodes fibrosis-specific pathology into cine CMR embeddings. A Feature Interaction Module concurrently optimizes diagnostic precision and cross-modal feature congruence, augmented by an uncertainty-guided adaptive training mechanism that dynamically calibrates task-specific objectives to ensure model generalizability. Evaluated on multi-center data from 231 subjects, CC-CMR achieves accuracy of 0.943 (95% CI: 0.886-0.986), outperforming state-of-the-art cine-CMR-only models by 4.3% while eliminating gadolinium dependency, demonstrating its clinical viability for wide range of populations and healthcare environments.
SDF-Net: A Hybrid Detection Network for Mediastinal Lymph Node Detection on Contrast CT Images
Sep 10, 2024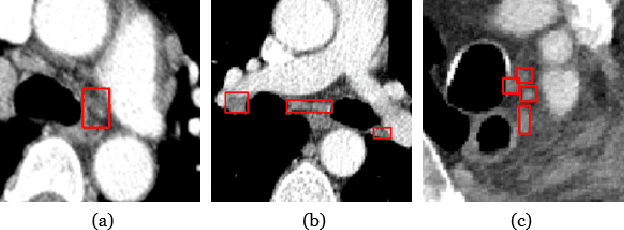
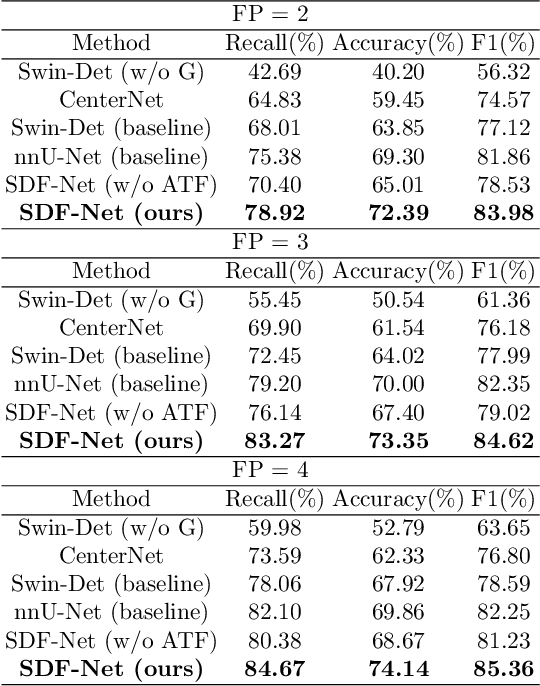
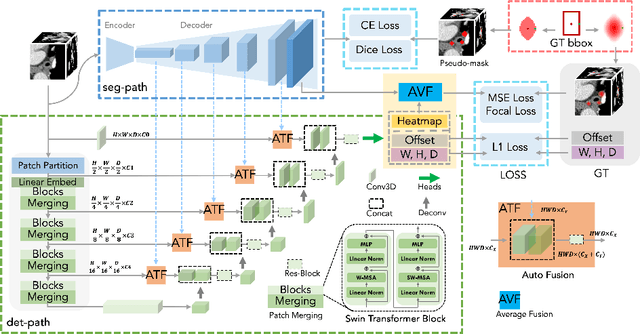
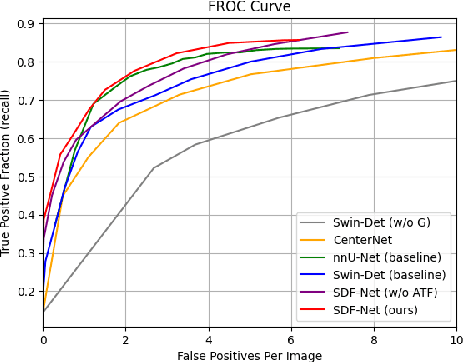
Accurate lymph node detection and quantification are crucial for cancer diagnosis and staging on contrast-enhanced CT images, as they impact treatment planning and prognosis. However, detecting lymph nodes in the mediastinal area poses challenges due to their low contrast, irregular shapes and dispersed distribution. In this paper, we propose a Swin-Det Fusion Network (SDF-Net) to effectively detect lymph nodes. SDF-Net integrates features from both segmentation and detection to enhance the detection capability of lymph nodes with various shapes and sizes. Specifically, an auto-fusion module is designed to merge the feature maps of segmentation and detection networks at different levels. To facilitate effective learning without mask annotations, we introduce a shape-adaptive Gaussian kernel to represent lymph node in the training stage and provide more anatomical information for effective learning. Comparative results demonstrate promising performance in addressing the complex lymph node detection problem.
Knee Cartilage Defect Assessment by Graph Representation and Surface Convolution
Jan 12, 2022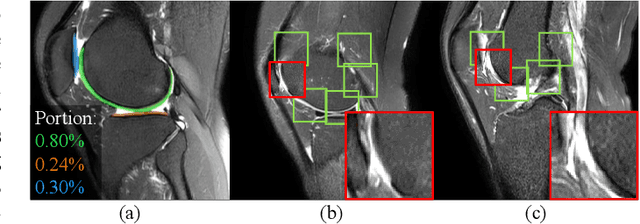
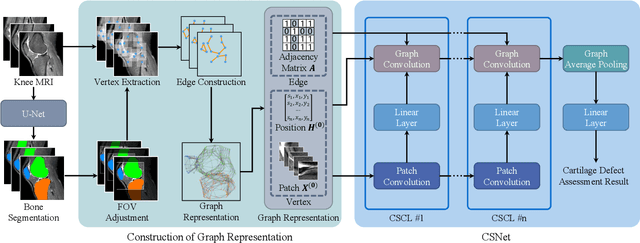
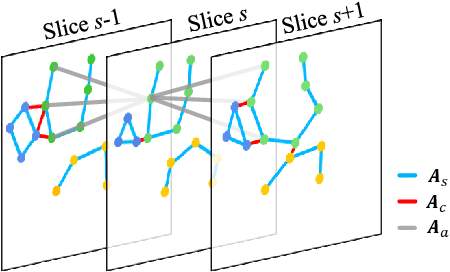
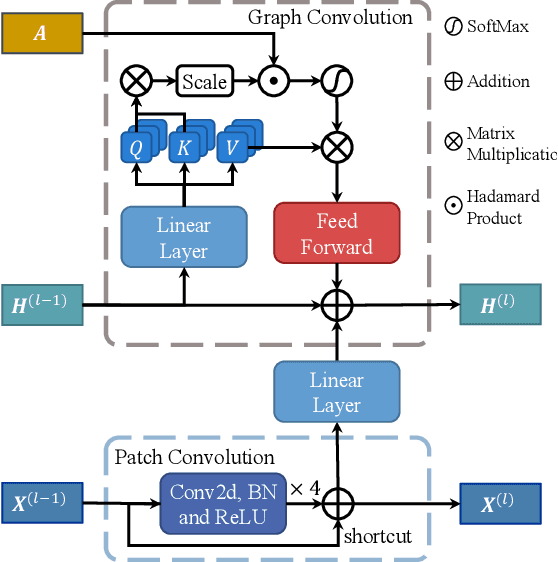
Knee osteoarthritis (OA) is the most common osteoarthritis and a leading cause of disability. Cartilage defects are regarded as major manifestations of knee OA, which are visible by magnetic resonance imaging (MRI). Thus early detection and assessment for knee cartilage defects are important for protecting patients from knee OA. In this way, many attempts have been made on knee cartilage defect assessment by applying convolutional neural networks (CNNs) to knee MRI. However, the physiologic characteristics of the cartilage may hinder such efforts: the cartilage is a thin curved layer, implying that only a small portion of voxels in knee MRI can contribute to the cartilage defect assessment; heterogeneous scanning protocols further challenge the feasibility of the CNNs in clinical practice; the CNN-based knee cartilage evaluation results lack interpretability. To address these challenges, we model the cartilages structure and appearance from knee MRI into a graph representation, which is capable of handling highly diverse clinical data. Then, guided by the cartilage graph representation, we design a non-Euclidean deep learning network with the self-attention mechanism, to extract cartilage features in the local and global, and to derive the final assessment with a visualized result. Our comprehensive experiments show that the proposed method yields superior performance in knee cartilage defect assessment, plus its convenient 3D visualization for interpretability.
Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning
Nov 21, 2021
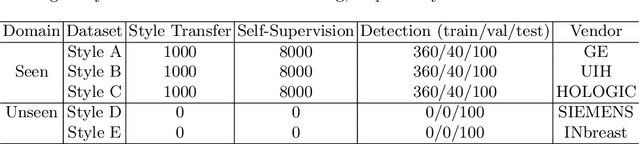
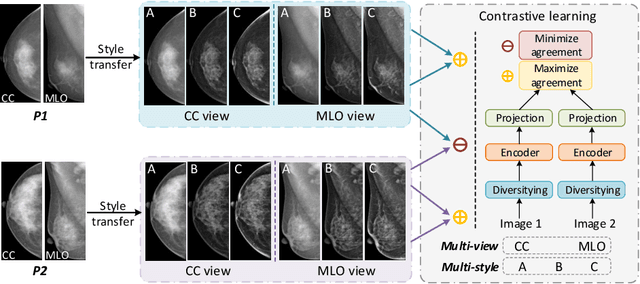
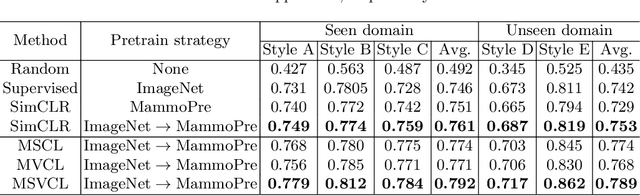
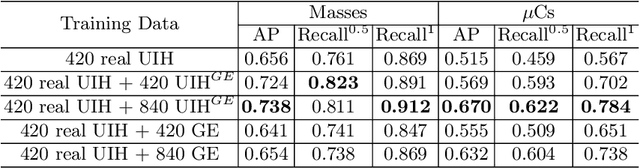
Lesion detection is a fundamental problem in the computer-aided diagnosis scheme for mammography. The advance of deep learning techniques have made a remarkable progress for this task, provided that the training data are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, the collection of mammograms from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning model to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor-styles. Afterward, the backbone network is then recalibrated to the downstream task of lesion detection with the specific supervised learning. The proposed method is evaluated with mammograms from four vendors and one unseen public dataset. The experimental results suggest that our approach can effectively improve detection performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
* Pages 98-108
mr2NST: Multi-Resolution and Multi-Reference Neural Style Transfer for Mammography
May 25, 2020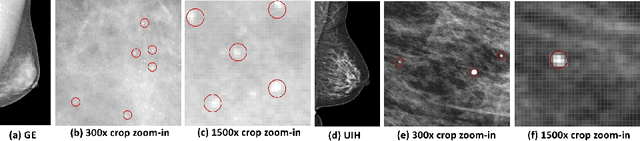

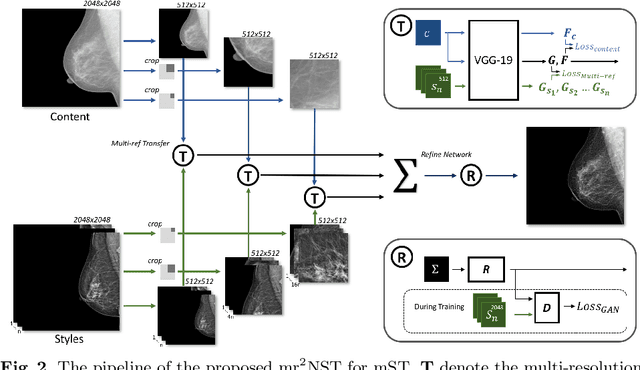
Computer-aided diagnosis with deep learning techniques has been shown to be helpful for the diagnosis of the mammography in many clinical studies. However, the image styles of different vendors are very distinctive, and there may exist domain gap among different vendors that could potentially compromise the universal applicability of one deep learning model. In this study, we explicitly address style variety issue with the proposed multi-resolution and multi-reference neural style transfer (mr2NST) network. The mr2NST can normalize the styles from different vendors to the same style baseline with very high resolution. We illustrate that the image quality of the transferred images is comparable to the quality of original images of the target domain (vendor) in terms of NIMA scores. Meanwhile, the mr2NST results are also shown to be helpful for the lesion detection in mammograms.
A Self-ensembling Framework for Semi-supervised Knee Osteoarthritis Localization and Classification with Dual-Consistency
May 19, 2020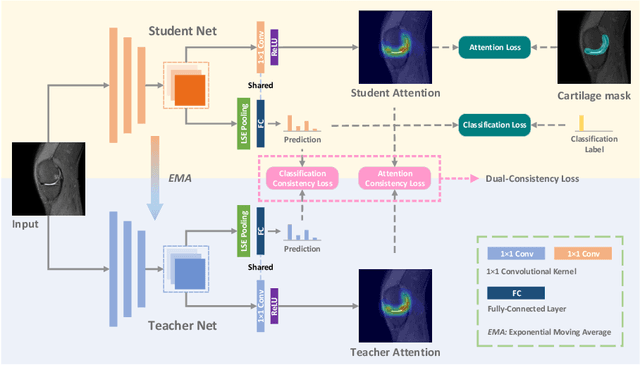

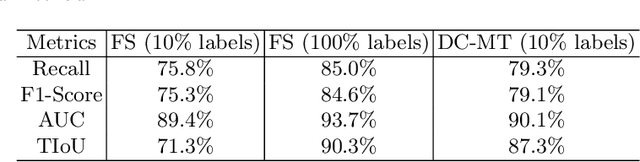
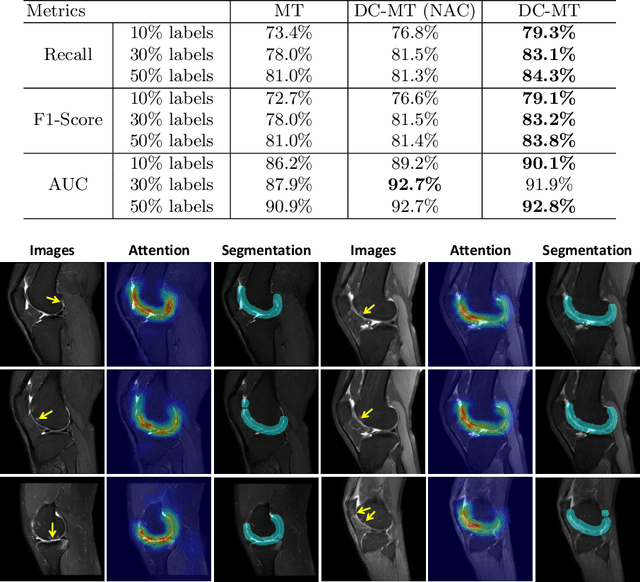
Knee osteoarthritis (OA) is one of the most common musculoskeletal disorders and requires early-stage diagnosis. Nowadays, the deep convolutional neural networks have achieved greatly in the computer-aided diagnosis field. However, the construction of the deep learning models usually requires great amounts of annotated data, which is generally high-cost. In this paper, we propose a novel approach for knee OA diagnosis, including severity classification and lesion localization. Particularly, we design a self-ensembling framework, which is composed of a student network and a teacher network with the same structure. The student network learns from both labeled data and unlabeled data and the teacher network averages the student model weights through the training course. A novel attention loss function is developed to obtain accurate attention masks. With dual-consistency checking of the attention in the lesion classification and localization, the two networks can gradually optimize the attention distribution and improve the performance of each other, whereas the training relies on partially labeled data only and follows the semi-supervised manner. Experiments show that the proposed method can significantly improve the self-ensembling performance in both knee OA classification and localization, and also greatly reduce the needs of annotated data.
Lung Infection Quantification of COVID-19 in CT Images with Deep Learning
Mar 30, 2020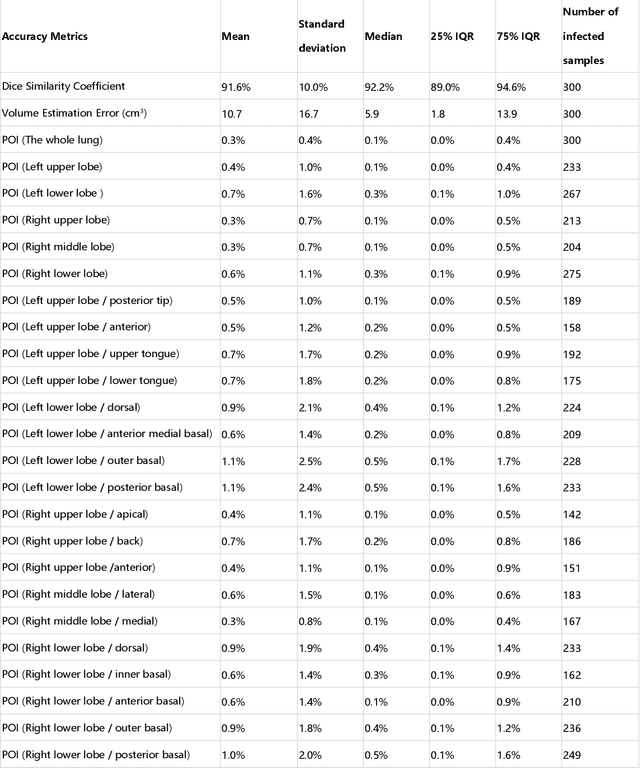
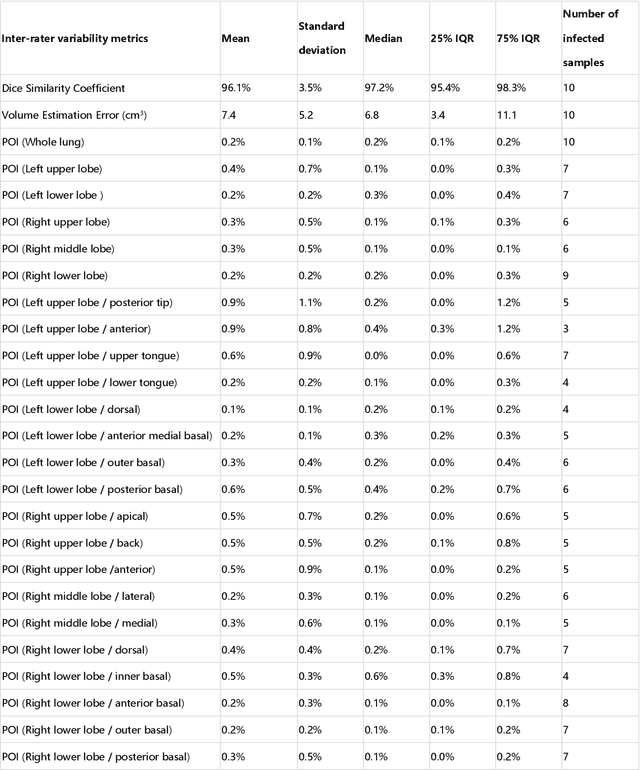
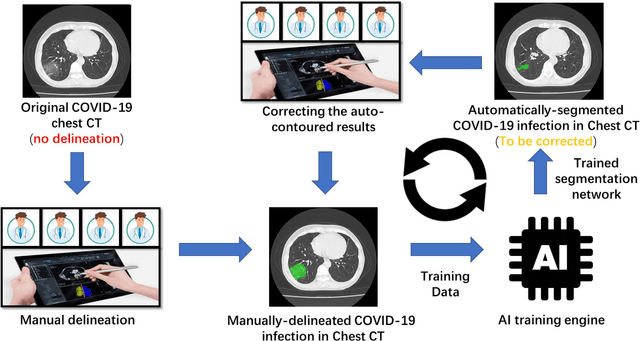
CT imaging is crucial for diagnosis, assessment and staging COVID-19 infection. Follow-up scans every 3-5 days are often recommended for disease progression. It has been reported that bilateral and peripheral ground glass opacification (GGO) with or without consolidation are predominant CT findings in COVID-19 patients. However, due to lack of computerized quantification tools, only qualitative impression and rough description of infected areas are currently used in radiological reports. In this paper, a deep learning (DL)-based segmentation system is developed to automatically quantify infection regions of interest (ROIs) and their volumetric ratios w.r.t. the lung. The performance of the system was evaluated by comparing the automatically segmented infection regions with the manually-delineated ones on 300 chest CT scans of 300 COVID-19 patients. For fast manual delineation of training samples and possible manual intervention of automatic results, a human-in-the-loop (HITL) strategy has been adopted to assist radiologists for infection region segmentation, which dramatically reduced the total segmentation time to 4 minutes after 3 iterations of model updating. The average Dice simiarility coefficient showed 91.6% agreement between automatic and manual infaction segmentations, and the mean estimation error of percentage of infection (POI) was 0.3% for the whole lung. Finally, possible applications, including but not limited to analysis of follow-up CT scans and infection distributions in the lobes and segments correlated with clinical findings, were discussed.
Synthesis and Inpainting-Based MR-CT Registration for Image-Guided Thermal Ablation of Liver Tumors
Jul 30, 2019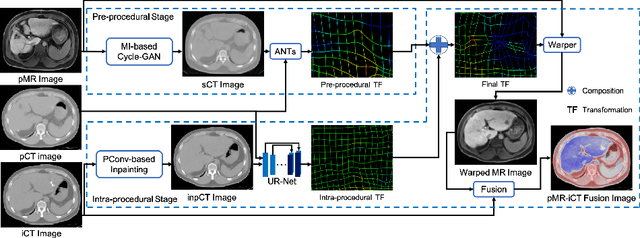
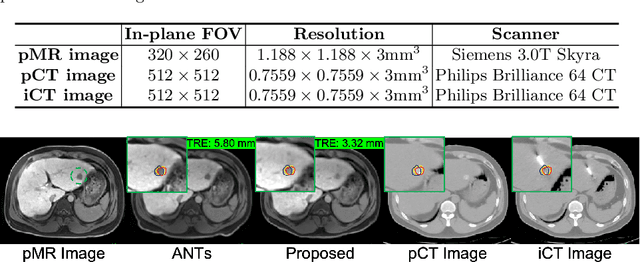
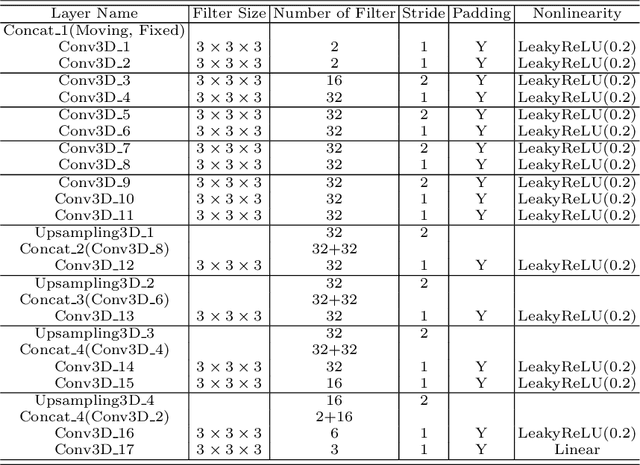
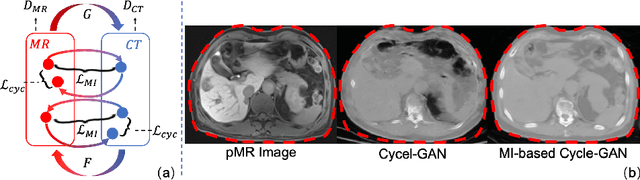
Thermal ablation is a minimally invasive procedure for treat-ing small or unresectable tumors. Although CT is widely used for guiding ablation procedures, the contrast of tumors against surrounding normal tissues in CT images is often poor, aggravating the difficulty in accurate thermal ablation. In this paper, we propose a fast MR-CT image registration method to overlay a pre-procedural MR (pMR) image onto an intra-procedural CT (iCT) image for guiding the thermal ablation of liver tumors. By first using a Cycle-GAN model with mutual information constraint to generate synthesized CT (sCT) image from the cor-responding pMR, pre-procedural MR-CT image registration is carried out through traditional mono-modality CT-CT image registration. At the intra-procedural stage, a partial-convolution-based network is first used to inpaint the probe and its artifacts in the iCT image. Then, an unsupervised registration network is used to efficiently align the pre-procedural CT (pCT) with the inpainted iCT (inpCT) image. The final transformation from pMR to iCT is obtained by combining the two estimated transformations,i.e., (1) from the pMR image space to the pCT image space (through sCT) and (2) from the pCT image space to the iCT image space (through inpCT). Experimental results confirm that the proposed method achieves high registration accuracy with a very fast computational speed.
Deep Learning based Inter-Modality Image Registration Supervised by Intra-Modality Similarity
Apr 28, 2018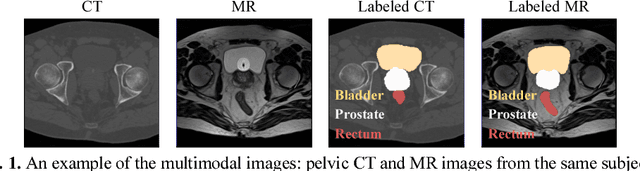
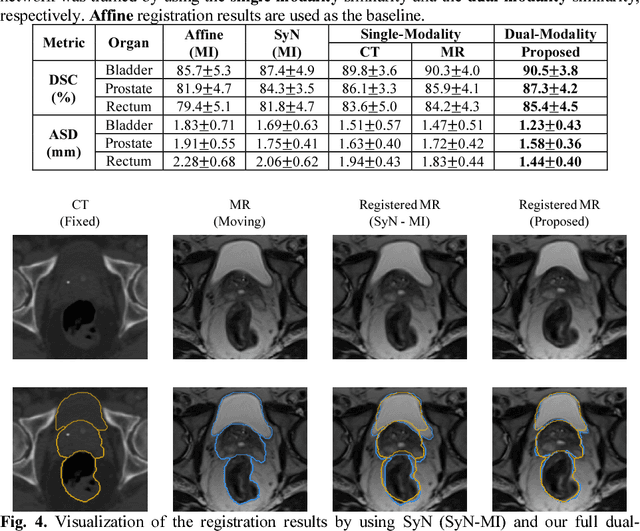
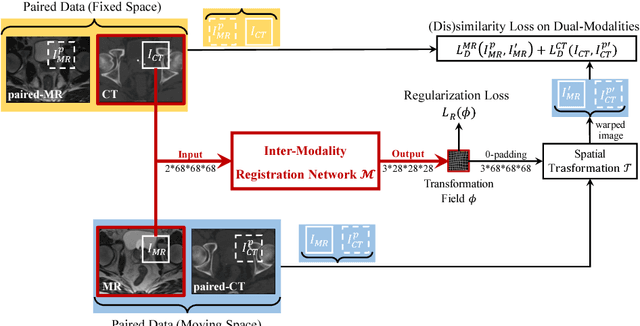
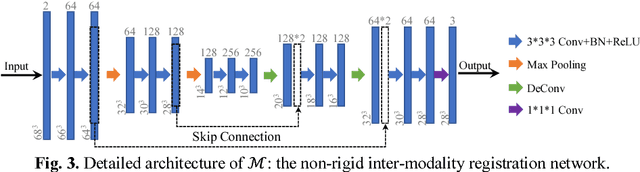
Non-rigid inter-modality registration can facilitate accurate information fusion from different modalities, but it is challenging due to the very different image appearances across modalities. In this paper, we propose to train a non-rigid inter-modality image registration network, which can directly predict the transformation field from the input multimodal images, such as CT and MR images. In particular, the training of our inter-modality registration network is supervised by intra-modality similarity metric based on the available paired data, which is derived from a pre-aligned CT and MR dataset. Specifically, in the training stage, to register the input CT and MR images, their similarity is evaluated on the warped MR image and the MR image that is paired with the input CT. So that, the intra-modality similarity metric can be directly applied to measure whether the input CT and MR images are well registered. Moreover, we use the idea of dual-modality fashion, in which we measure the similarity on both CT modality and MR modality. In this way, the complementary anatomies in both modalities can be jointly considered to more accurately train the inter-modality registration network. In the testing stage, the trained inter-modality registration network can be directly applied to register the new multimodal images without any paired data. Experimental results have shown that, the proposed method can achieve promising accuracy and efficiency for the challenging non-rigid inter-modality registration task and also outperforms the state-of-the-art approaches.