 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Medical Segmentation
Mar 27, 2024



Rapid advancements in medical image segmentation performance have been significantly driven by the development of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). However, these models introduce high computational demands and often have limited ability to generalize across diverse medical imaging datasets. In this manuscript, we introduce Generative Medical Segmentation (GMS), a novel approach leveraging a generative model for image segmentation. Concretely, GMS employs a robust pre-trained Variational Autoencoder (VAE) to derive latent representations of both images and masks, followed by a mapping model that learns the transition from image to mask in the latent space. This process culminates in generating a precise segmentation mask within the image space using the pre-trained VAE decoder. The design of GMS leads to fewer learnable parameters in the model, resulting in a reduced computational burden and enhanced generalization capability. Our extensive experimental analysis across five public datasets in different medical imaging domains demonstrates GMS outperforms existing discriminative segmentation models and has remarkable domain generalization. Our experiments suggest GMS could set a new benchmark for medical image segmentation, offering a scalable and effective solution. GMS implementation and model weights are available at https://github.com/King-HAW/GMS.
ARHNet: Adaptive Region Harmonization for Lesion-aware Augmentation to Improve Segmentation Performance
Jul 02, 2023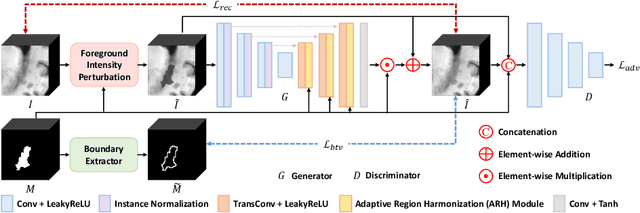
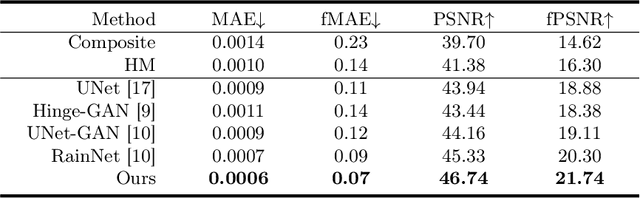
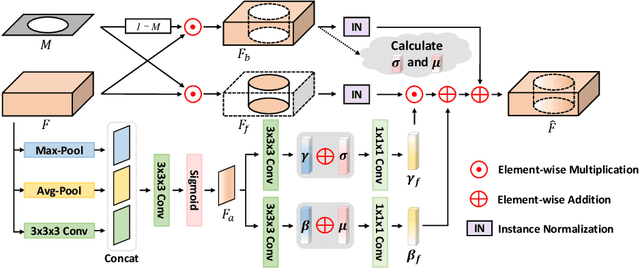
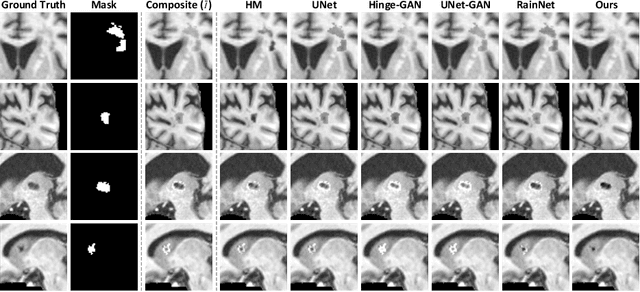
Accurately segmenting brain lesions in MRI scans is critical for providing patients with prognoses and neurological monitoring. However, the performance of CNN-based segmentation methods is constrained by the limited training set size. Advanced data augmentation is an effective strategy to improve the model's robustness. However, they often introduce intensity disparities between foreground and background areas and boundary artifacts, which weakens the effectiveness of such strategies. In this paper, we propose a foreground harmonization framework (ARHNet) to tackle intensity disparities and make synthetic images look more realistic. In particular, we propose an Adaptive Region Harmonization (ARH) module to dynamically align foreground feature maps to the background with an attention mechanism. We demonstrate the efficacy of our method in improving the segmentation performance using real and synthetic images. Experimental results on the ATLAS 2.0 dataset show that ARHNet outperforms other methods for image harmonization tasks, and boosts the down-stream segmentation performance. Our code is publicly available at https://github.com/King-HAW/ARHNet.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023



Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
Domain Generalization for Mammographic Image Analysis via Contrastive Learning
Apr 20, 2023Mammographic image analysis is a fundamental problem in the computer-aided diagnosis scheme, which has recently made remarkable progress with the advance of deep learning. However, the construction of a deep learning model requires training data that are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, mammogram collection from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning models to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor styles. Afterward, the backbone network is then recalibrated to the downstream tasks of mass detection, multi-view mass matching, BI-RADS classification and breast density classification with specific supervised learning. The proposed method is evaluated with mammograms from four vendors and two unseen public datasets. The experimental results suggest that our approach can effectively improve analysis performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
ChatCAD: Interactive Computer-Aided Diagnosis on Medical Image using Large Language Models
Feb 14, 2023



Large language models (LLMs) have recently demonstrated their potential in clinical applications, providing valuable medical knowledge and advice. For example, a large dialog LLM like ChatGPT has successfully passed part of the US medical licensing exam. However, LLMs currently have difficulty processing images, making it challenging to interpret information from medical images, which are rich in information that supports clinical decisions. On the other hand, computer-aided diagnosis (CAD) networks for medical images have seen significant success in the medical field by using advanced deep-learning algorithms to support clinical decision-making. This paper presents a method for integrating LLMs into medical-image CAD networks. The proposed framework uses LLMs to enhance the output of multiple CAD networks, such as diagnosis networks, lesion segmentation networks, and report generation networks, by summarizing and reorganizing the information presented in natural language text format. The goal is to merge the strengths of LLMs' medical domain knowledge and logical reasoning with the vision understanding capability of existing medical-image CAD models to create a more user-friendly and understandable system for patients compared to conventional CAD systems. In the future, LLM's medical knowledge can be also used to improve the performance of vision-based medical-image CAD models.
Image Synthesis with Disentangled Attributes for Chest X-Ray Nodule Augmentation and Detection
Jul 19, 2022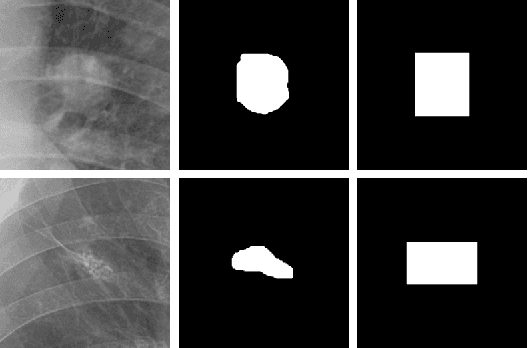
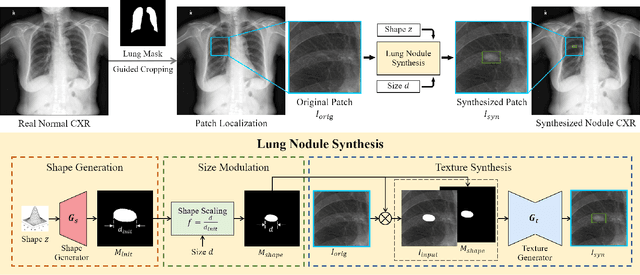
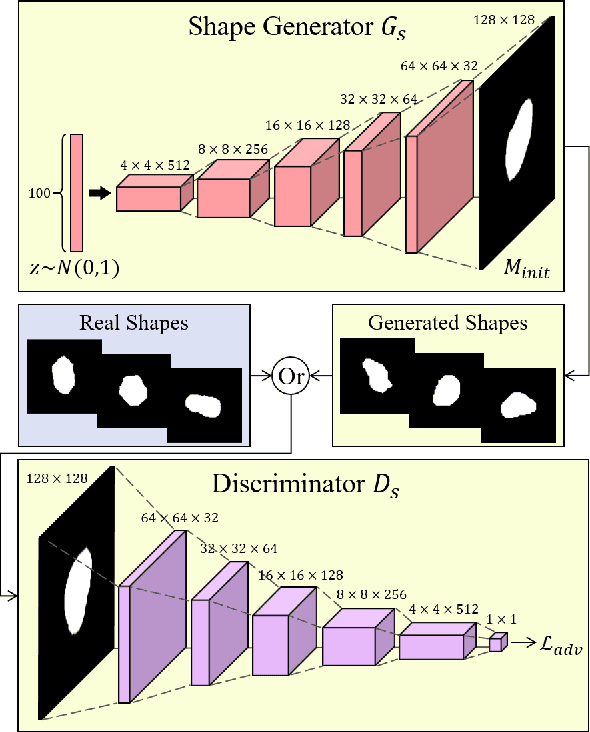
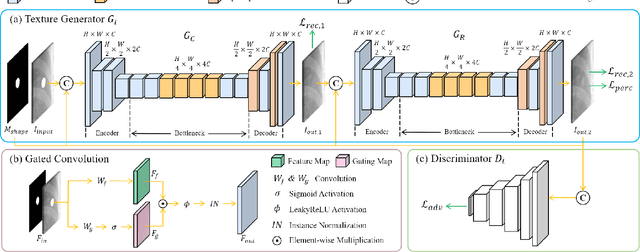
Lung nodule detection in chest X-ray (CXR) images is common to early screening of lung cancers. Deep-learning-based Computer-Assisted Diagnosis (CAD) systems can support radiologists for nodule screening in CXR. However, it requires large-scale and diverse medical data with high-quality annotations to train such robust and accurate CADs. To alleviate the limited availability of such datasets, lung nodule synthesis methods are proposed for the sake of data augmentation. Nevertheless, previous methods lack the ability to generate nodules that are realistic with the size attribute desired by the detector. To address this issue, we introduce a novel lung nodule synthesis framework in this paper, which decomposes nodule attributes into three main aspects including shape, size, and texture, respectively. A GAN-based Shape Generator firstly models nodule shapes by generating diverse shape masks. The following Size Modulation then enables quantitative control on the diameters of the generated nodule shapes in pixel-level granularity. A coarse-to-fine gated convolutional Texture Generator finally synthesizes visually plausible nodule textures conditioned on the modulated shape masks. Moreover, we propose to synthesize nodule CXR images by controlling the disentangled nodule attributes for data augmentation, in order to better compensate for the nodules that are easily missed in the detection task. Our experiments demonstrate the enhanced image quality, diversity, and controllability of the proposed lung nodule synthesis framework. We also validate the effectiveness of our data augmentation on greatly improving nodule detection performance.
Follow My Eye: Using Gaze to Supervise Computer-Aided Diagnosis
Apr 06, 2022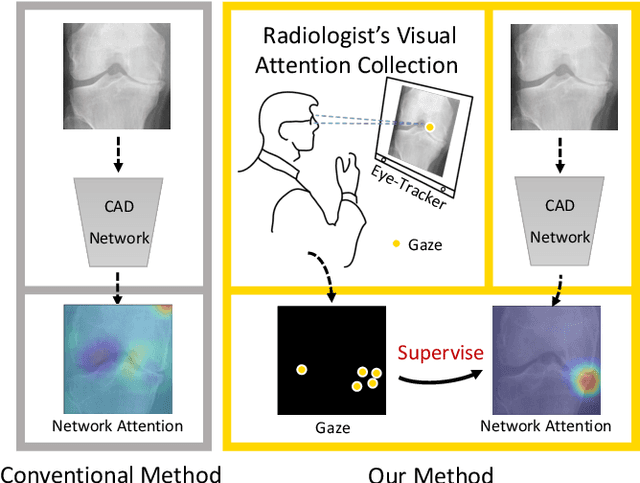
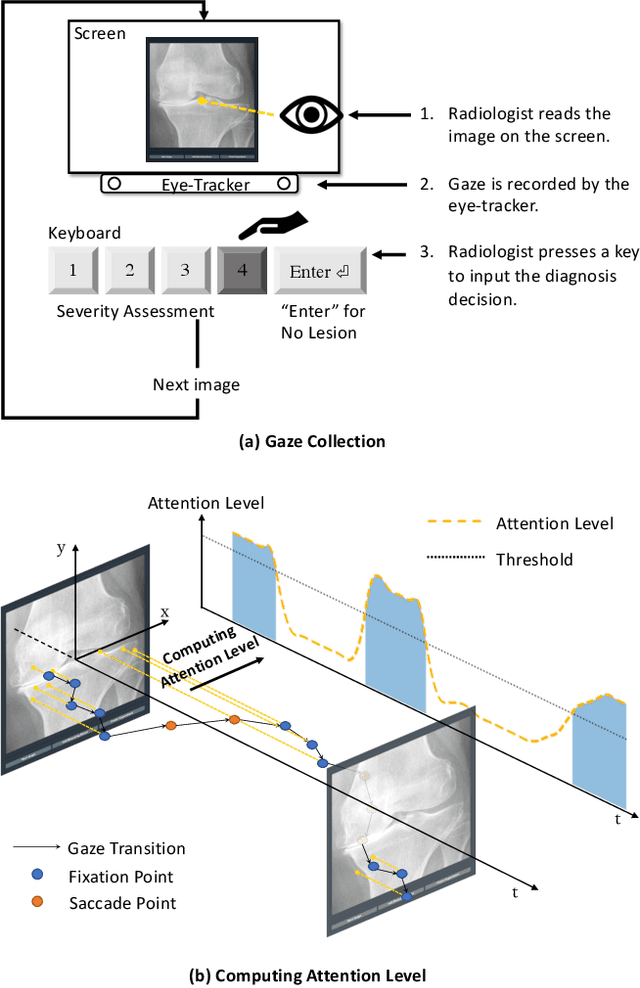

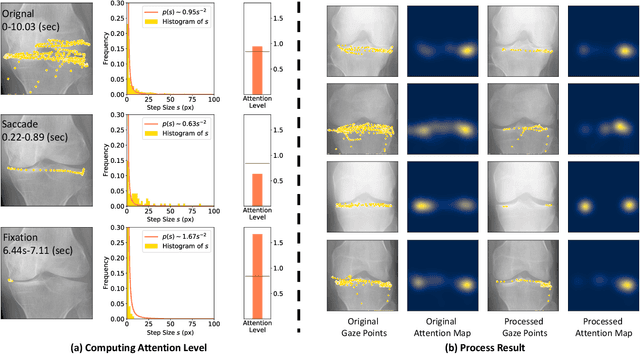
When deep neural network (DNN) was first introduced to the medical image analysis community, researchers were impressed by its performance. However, it is evident now that a large number of manually labeled data is often a must to train a properly functioning DNN. This demand for supervision data and labels is a major bottleneck in current medical image analysis, since collecting a large number of annotations from experienced experts can be time-consuming and expensive. In this paper, we demonstrate that the eye movement of radiologists reading medical images can be a new form of supervision to train the DNN-based computer-aided diagnosis (CAD) system. Particularly, we record the tracks of the radiologists' gaze when they are reading images. The gaze information is processed and then used to supervise the DNN's attention via an Attention Consistency module. To the best of our knowledge, the above pipeline is among the earliest efforts to leverage expert eye movement for deep-learning-based CAD. We have conducted extensive experiments on knee X-ray images for osteoarthritis assessment. The results show that our method can achieve considerable improvement in diagnosis performance, with the help of gaze supervision.
Knee Cartilage Defect Assessment by Graph Representation and Surface Convolution
Jan 12, 2022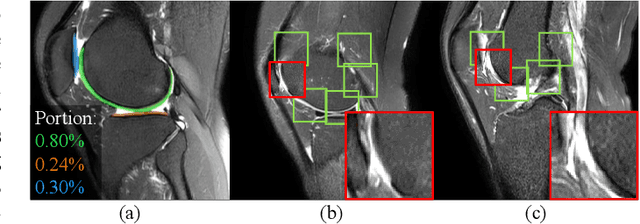
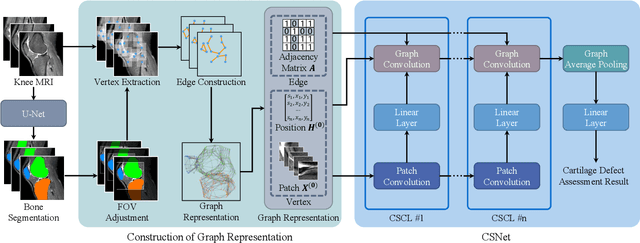
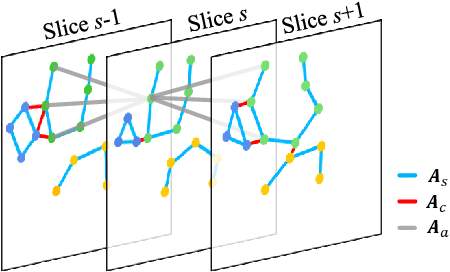
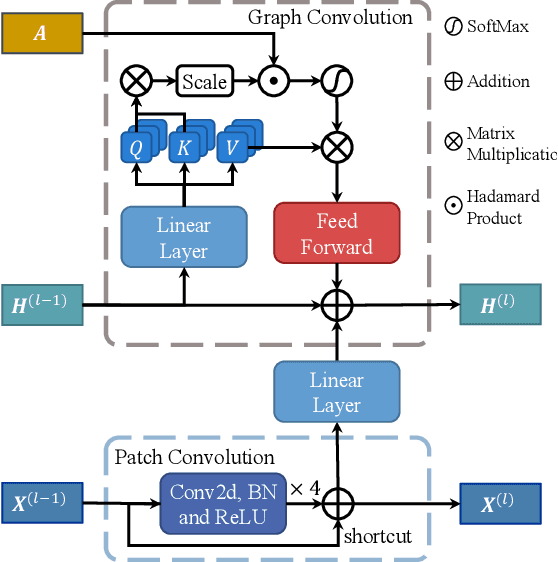
Knee osteoarthritis (OA) is the most common osteoarthritis and a leading cause of disability. Cartilage defects are regarded as major manifestations of knee OA, which are visible by magnetic resonance imaging (MRI). Thus early detection and assessment for knee cartilage defects are important for protecting patients from knee OA. In this way, many attempts have been made on knee cartilage defect assessment by applying convolutional neural networks (CNNs) to knee MRI. However, the physiologic characteristics of the cartilage may hinder such efforts: the cartilage is a thin curved layer, implying that only a small portion of voxels in knee MRI can contribute to the cartilage defect assessment; heterogeneous scanning protocols further challenge the feasibility of the CNNs in clinical practice; the CNN-based knee cartilage evaluation results lack interpretability. To address these challenges, we model the cartilages structure and appearance from knee MRI into a graph representation, which is capable of handling highly diverse clinical data. Then, guided by the cartilage graph representation, we design a non-Euclidean deep learning network with the self-attention mechanism, to extract cartilage features in the local and global, and to derive the final assessment with a visualized result. Our comprehensive experiments show that the proposed method yields superior performance in knee cartilage defect assessment, plus its convenient 3D visualization for interpretability.
Learning Hierarchical Attention for Weakly-supervised Chest X-Ray Abnormality Localization and Diagnosis
Dec 23, 2021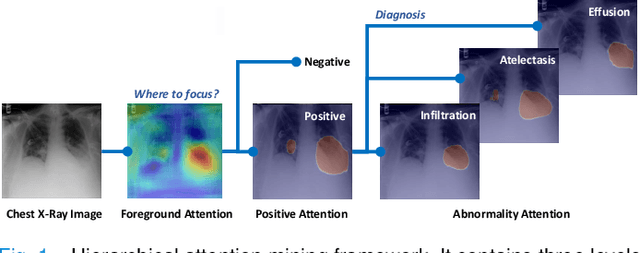
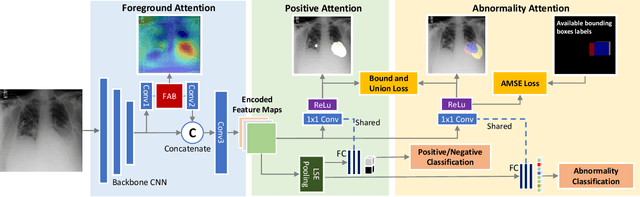
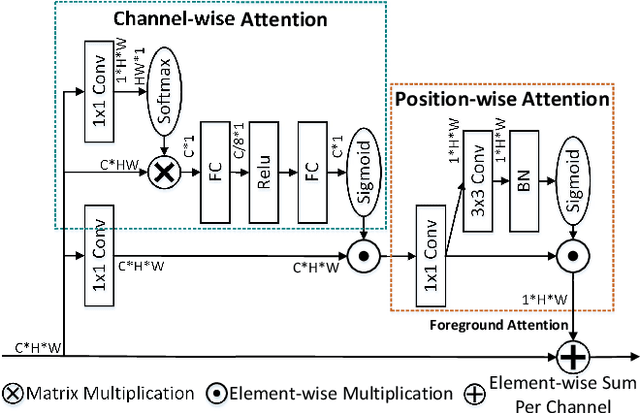
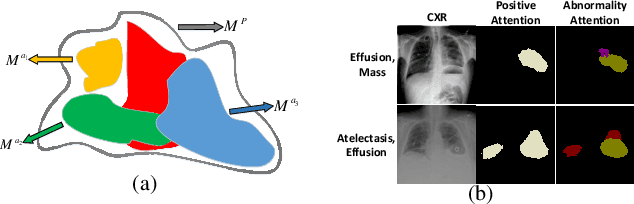
We consider the problem of abnormality localization for clinical applications. While deep learning has driven much recent progress in medical imaging, many clinical challenges are not fully addressed, limiting its broader usage. While recent methods report high diagnostic accuracies, physicians have concerns trusting these algorithm results for diagnostic decision-making purposes because of a general lack of algorithm decision reasoning and interpretability. One potential way to address this problem is to further train these models to localize abnormalities in addition to just classifying them. However, doing this accurately will require a large amount of disease localization annotations by clinical experts, a task that is prohibitively expensive to accomplish for most applications. In this work, we take a step towards addressing these issues by means of a new attention-driven weakly supervised algorithm comprising a hierarchical attention mining framework that unifies activation- and gradient-based visual attention in a holistic manner. Our key algorithmic innovations include the design of explicit ordinal attention constraints, enabling principled model training in a weakly-supervised fashion, while also facilitating the generation of visual-attention-driven model explanations by means of localization cues. On two large-scale chest X-ray datasets (NIH ChestX-ray14 and CheXpert), we demonstrate significant localization performance improvements over the current state of the art while also achieving competitive classification performance. Our code is available on https://github.com/oyxhust/HAM.
Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning
Nov 21, 2021
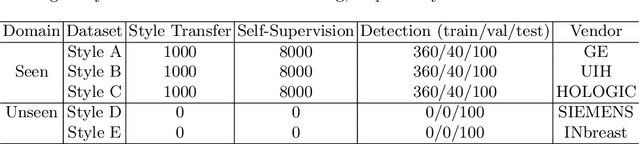
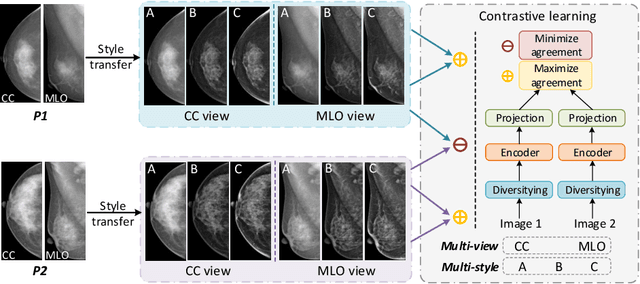
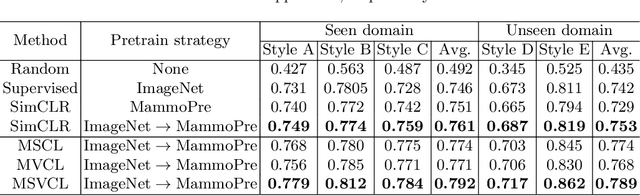
Lesion detection is a fundamental problem in the computer-aided diagnosis scheme for mammography. The advance of deep learning techniques have made a remarkable progress for this task, provided that the training data are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, the collection of mammograms from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning model to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor-styles. Afterward, the backbone network is then recalibrated to the downstream task of lesion detection with the specific supervised learning. The proposed method is evaluated with mammograms from four vendors and one unseen public dataset. The experimental results suggest that our approach can effectively improve detection performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
* Pages 98-108