 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Human Trajectory from Scene History
Oct 17, 2022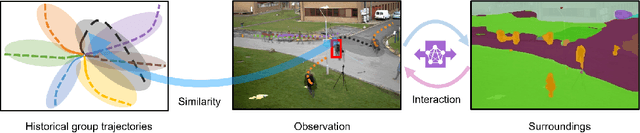

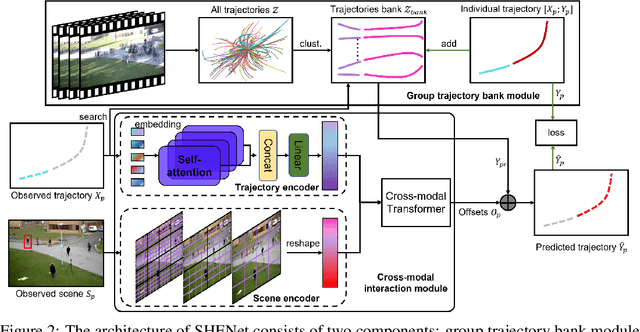
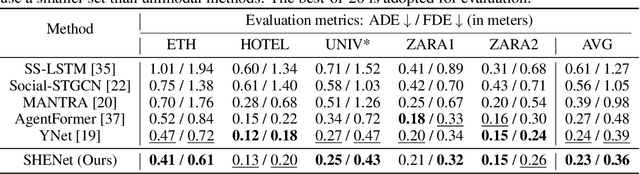
Predicting the future trajectory of a person remains a challenging problem, due to randomness and subjectivity of human movement. However, the moving patterns of human in a constrained scenario typically conform to a limited number of regularities to a certain extent, because of the scenario restrictions and person-person or person-object interactivity. Thus, an individual person in this scenario should follow one of the regularities as well. In other words, a person's subsequent trajectory has likely been traveled by others. Based on this hypothesis, we propose to forecast a person's future trajectory by learning from the implicit scene regularities. We call the regularities, inherently derived from the past dynamics of the people and the environment in the scene, scene history. We categorize scene history information into two types: historical group trajectory and individual-surroundings interaction. To exploit these two types of information for trajectory prediction, we propose a novel framework Scene History Excavating Network (SHENet), where the scene history is leveraged in a simple yet effective approach. In particular, we design two components: the group trajectory bank module to extract representative group trajectories as the candidate for future path, and the cross-modal interaction module to model the interaction between individual past trajectory and its surroundings for trajectory refinement. In addition, to mitigate the uncertainty in ground-truth trajectory, caused by the aforementioned randomness and subjectivity of human movement, we propose to include smoothness into the training process and evaluation metrics. We conduct extensive evaluations to validate the efficacy of our proposed framework on ETH, UCY, as well as a new, challenging benchmark dataset PAV, demonstrating superior performance compared to state-of-the-art methods.
Learning Hierarchical Attention for Weakly-supervised Chest X-Ray Abnormality Localization and Diagnosis
Dec 23, 2021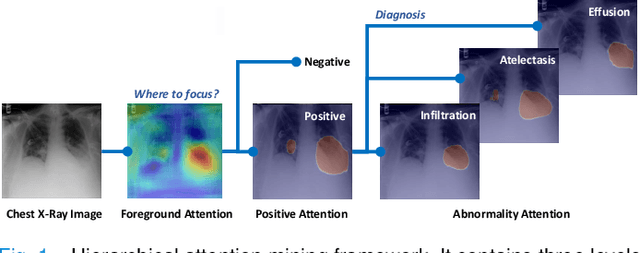
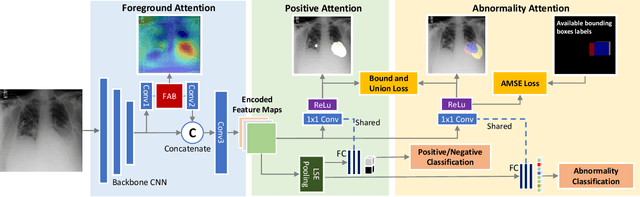
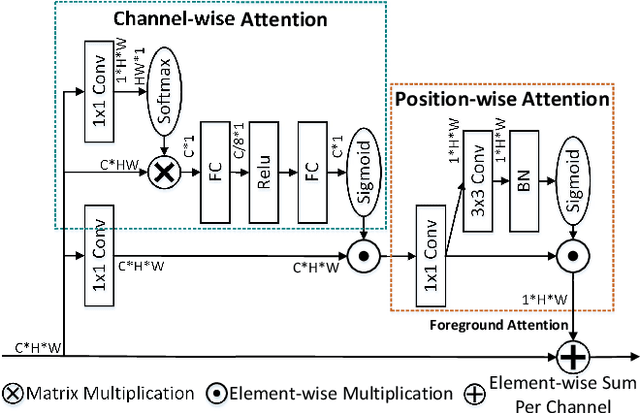
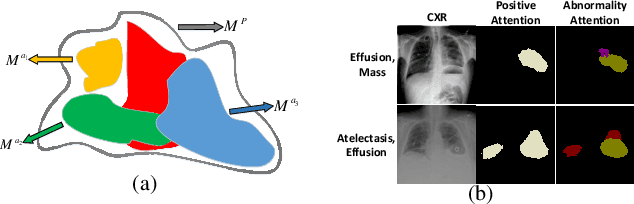
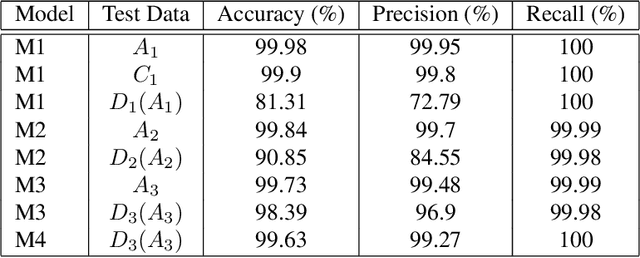
We consider the problem of abnormality localization for clinical applications. While deep learning has driven much recent progress in medical imaging, many clinical challenges are not fully addressed, limiting its broader usage. While recent methods report high diagnostic accuracies, physicians have concerns trusting these algorithm results for diagnostic decision-making purposes because of a general lack of algorithm decision reasoning and interpretability. One potential way to address this problem is to further train these models to localize abnormalities in addition to just classifying them. However, doing this accurately will require a large amount of disease localization annotations by clinical experts, a task that is prohibitively expensive to accomplish for most applications. In this work, we take a step towards addressing these issues by means of a new attention-driven weakly supervised algorithm comprising a hierarchical attention mining framework that unifies activation- and gradient-based visual attention in a holistic manner. Our key algorithmic innovations include the design of explicit ordinal attention constraints, enabling principled model training in a weakly-supervised fashion, while also facilitating the generation of visual-attention-driven model explanations by means of localization cues. On two large-scale chest X-ray datasets (NIH ChestX-ray14 and CheXpert), we demonstrate significant localization performance improvements over the current state of the art while also achieving competitive classification performance. Our code is available on https://github.com/oyxhust/HAM.
How intelligent are convolutional neural networks?
Oct 31, 2017


Motivated by the Gestalt pattern theory, and the Winograd Challenge for language understanding, we design synthetic experiments to investigate a deep learning algorithm's ability to infer simple (at least for human) visual concepts, such as symmetry, from examples. A visual concept is represented by randomly generated, positive as well as negative, example images. We then test the ability and speed of algorithms (and humans) to learn the concept from these images. The training and testing are performed progressively in multiple rounds, with each subsequent round deliberately designed to be more complex and confusing than the previous round(s), especially if the concept was not grasped by the learner. However, if the concept was understood, all the deliberate tests would become trivially easy. Our experiments show that humans can often infer a semantic concept quickly after looking at only a very small number of examples (this is often referred to as an "aha moment": a moment of sudden realization), and performs perfectly during all testing rounds (except for careless mistakes). On the contrary, deep convolutional neural networks (DCNN) could approximate some concepts statistically, but only after seeing many (x10^4) more examples. And it will still make obvious mistakes, especially during deliberate testing rounds or on samples outside the training distributions. This signals a lack of true "understanding", or a failure to reach the right "formula" for the semantics. We did find that some concepts are easier for DCNN than others. For example, simple "counting" is more learnable than "symmetry", while "uniformity" or "conformance" are much more difficult for DCNN to learn. To conclude, we propose an "Aha Challenge" for visual perception, calling for focused and quantitative research on Gestalt-style machine intelligence using limited training examples.