 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^3$POT: Contrast-Driven Face Occlusion Segmentation via Self-Supervised Prompt Learning
Jan 31, 2026Existing face parsing methods usually misclassify occlusions as facial components. This is because occlusion is a high-level concept, it does not refer to a concrete category of object. Thus, constructing a real-world face dataset covering all categories of occlusion object is almost impossible and accurate mask annotation is labor-intensive. To deal with the problems, we present S$^3$POT, a contrast-driven framework synergizing face generation with self-supervised spatial prompting, to achieve occlusion segmentation. The framework is inspired by the insights: 1) Modern face generators' ability to realistically reconstruct occluded regions, creating an image that preserve facial geometry while eliminating occlusion, and 2) Foundation segmentation models' (e.g., SAM) capacity to extract precise mask when provided with appropriate prompts. In particular, S$^3$POT consists of three modules: Reference Generation (RF), Feature enhancement (FE), and Prompt Selection (PS). First, a reference image is produced by RF using structural guidance from parsed mask. Second, FE performs contrast of tokens between raw and reference images to obtain an initial prompt, then modifies image features with the prompt by cross-attention. Third, based on the enhanced features, PS constructs a set of positive and negative prompts and screens them with a self-attention network for a mask decoder. The network is learned under the guidance of three novel and complementary objective functions without occlusion ground truth mask involved. Extensive experiments on a dedicatedly collected dataset demonstrate S$^3$POT's superior performance and the effectiveness of each module.
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Mar 29, 2024Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($\theta$ and $\beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
Human Mesh Recovery from Arbitrary Multi-view Images
Mar 20, 2024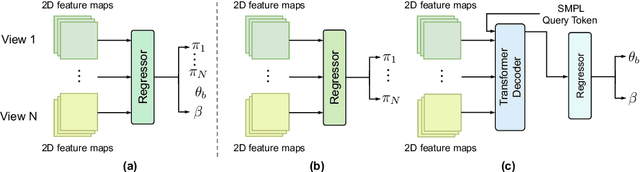
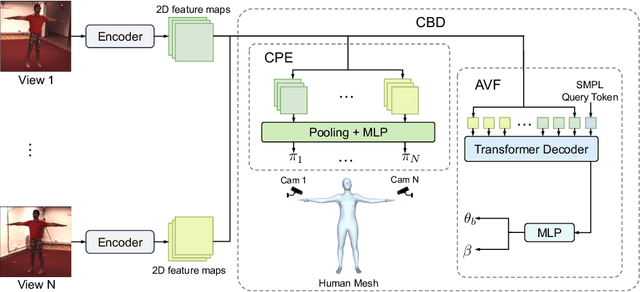
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (\ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.
Forecasting Human Trajectory from Scene History
Oct 17, 2022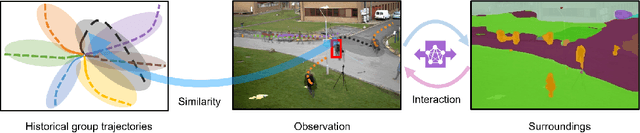

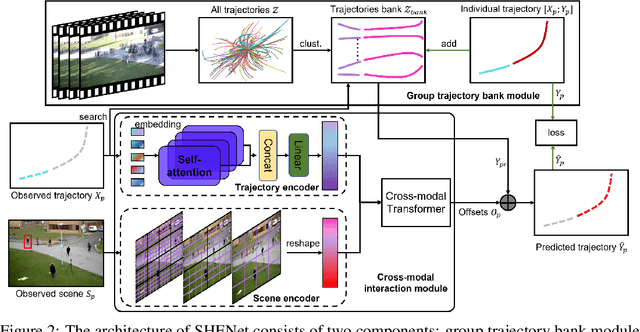
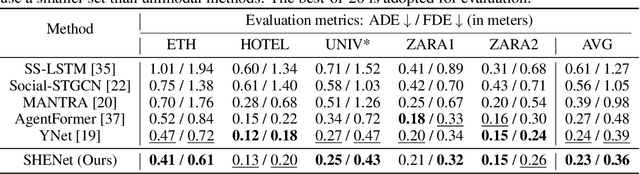
Predicting the future trajectory of a person remains a challenging problem, due to randomness and subjectivity of human movement. However, the moving patterns of human in a constrained scenario typically conform to a limited number of regularities to a certain extent, because of the scenario restrictions and person-person or person-object interactivity. Thus, an individual person in this scenario should follow one of the regularities as well. In other words, a person's subsequent trajectory has likely been traveled by others. Based on this hypothesis, we propose to forecast a person's future trajectory by learning from the implicit scene regularities. We call the regularities, inherently derived from the past dynamics of the people and the environment in the scene, scene history. We categorize scene history information into two types: historical group trajectory and individual-surroundings interaction. To exploit these two types of information for trajectory prediction, we propose a novel framework Scene History Excavating Network (SHENet), where the scene history is leveraged in a simple yet effective approach. In particular, we design two components: the group trajectory bank module to extract representative group trajectories as the candidate for future path, and the cross-modal interaction module to model the interaction between individual past trajectory and its surroundings for trajectory refinement. In addition, to mitigate the uncertainty in ground-truth trajectory, caused by the aforementioned randomness and subjectivity of human movement, we propose to include smoothness into the training process and evaluation metrics. We conduct extensive evaluations to validate the efficacy of our proposed framework on ETH, UCY, as well as a new, challenging benchmark dataset PAV, demonstrating superior performance compared to state-of-the-art methods.