 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFit: Multi-modal 3D Body Fitting via Scale-agnostic Dense Landmark Prediction
Apr 23, 2026Fitting an underlying body model to 3D clothed human assets has been extensively studied, yet most approaches focus on either single-modal inputs such as point clouds or multi-view images alone, often requiring a known metric scale. This constraint is frequently impractical, especially for AI-generated assets where scale distortion is common. We propose OmniFit, a method that can seamlessly handle diverse multi-modal inputs, including full scans, partial depth observations, and image captures, while remaining scale-agnostic for both real and synthetic assets. Our key innovation is a simple yet effective conditional transformer decoder that directly maps surface points to dense body landmarks, which are then used for SMPL-X parameter fitting. In addition, an optional plug-and-play image adapter incorporates visual cues to compensate for missing geometric information. We further introduce a dedicated scale predictor that rescales subjects to canonical body proportions. OmniFit substantially outperforms state-of-the-art methods by 57.1 to 80.9 percent across daily and loose clothing scenarios. To the best of our knowledge, it is the first body fitting method to surpass multi-view optimization baselines and the first to achieve millimeter-level accuracy on the CAPE and 4D-DRESS benchmarks.
ETCH-X: Robustify Expressive Body Fitting to Clothed Humans with Composable Datasets
Apr 09, 2026Human body fitting, which aligns parametric body models such as SMPL to raw 3D point clouds of clothed humans, serves as a crucial first step for downstream tasks like animation and texturing. An effective fitting method should be both locally expressive-capturing fine details such as hands and facial features-and globally robust to handle real-world challenges, including clothing dynamics, pose variations, and noisy or partial inputs. Existing approaches typically excel in only one aspect, lacking an all-in-one solution.We upgrade ETCH to ETCH-X, which leverages a tightness-aware fitting paradigm to filter out clothing dynamics ("undress"), extends expressiveness with SMPL-X, and replaces explicit sparse markers (which are highly sensitive to partial data) with implicit dense correspondences ("dense fit") for more robust and fine-grained body fitting. Our disentangled "undress" and "dense fit" modular stages enable separate and scalable training on composable data sources, including diverse simulated garments (CLOTH3D), large-scale full-body motions (AMASS), and fine-grained hand gestures (InterHand2.6M), improving outfit generalization and pose robustness of both bodies and hands. Our approach achieves robust and expressive fitting across diverse clothing, poses, and levels of input completeness, delivering a substantial performance improvement over ETCH on both: 1) seen data, such as 4D-Dress (MPJPE-All, 33.0% ) and CAPE (V2V-Hands, 35.8% ), and 2) unseen data, such as BEDLAM2.0 (MPJPE-All, 80.8% ; V2V-All, 80.5% ). Code and models will be released at https://xiaobenli00.github.io/ETCH-X/.
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Mar 29, 2024Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($\theta$ and $\beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
Human Mesh Recovery from Arbitrary Multi-view Images
Mar 20, 2024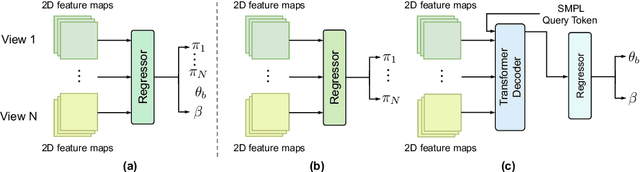
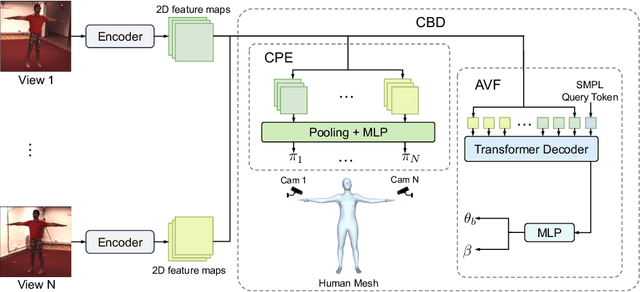
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (\ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.