 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Mesh Recovery from Arbitrary Multi-view Images
Paper and Code
Mar 20, 2024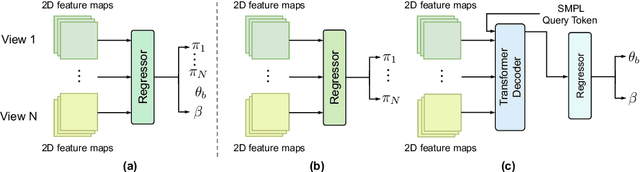
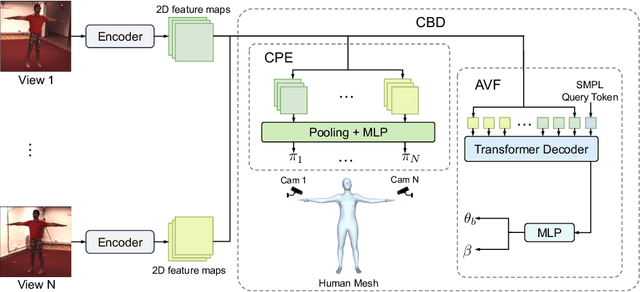
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (\ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.