 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchable deep beamformer for high-quality and real-time passive acoustic mapping
Dec 03, 2024
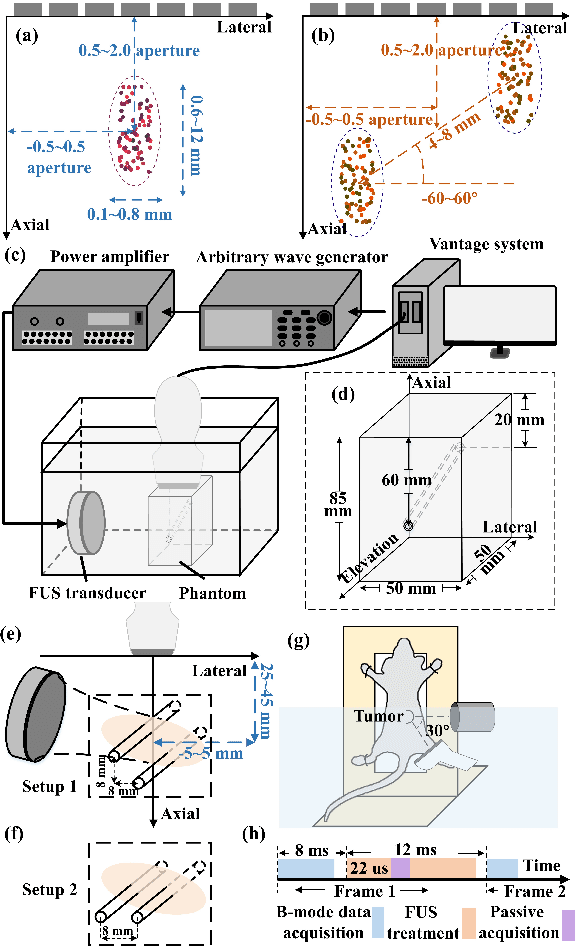
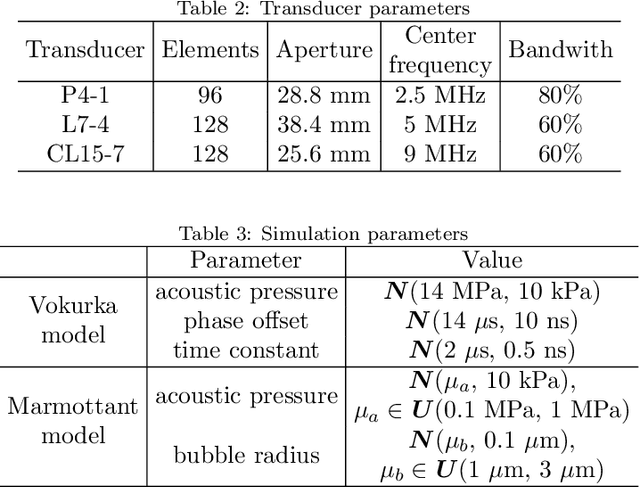
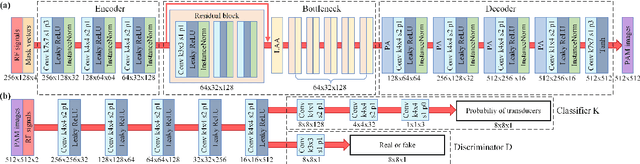
Passive acoustic mapping (PAM) is a promising tool for monitoring acoustic cavitation activities in the applications of ultrasound therapy. Data-adaptive beamformers for PAM have better image quality compared to the time exposure acoustics (TEA) algorithms. However, the computational cost of data-adaptive beamformers is considerably expensive. In this work, we develop a deep beamformer based on a generative adversarial network, which can switch between different transducer arrays and reconstruct high-quality PAM images directly from radio frequency ultrasound signals with low computational cost. The deep beamformer was trained on the dataset consisting of simulated and experimental cavitation signals of single and multiple microbubble clouds measured by different (linear and phased) arrays covering 1-15 MHz. We compared the performance of the deep beamformer to TEA and three different data-adaptive beamformers using the simulated and experimental test dataset. Compared with TEA, the deep beamformer reduced the energy spread area by 18.9%-65.0% and improved the image signal-to-noise ratio by 9.3-22.9 dB in average for the different arrays in our data. Compared to the data-adaptive beamformers, the deep beamformer reduced the computational cost by three orders of magnitude achieving 10.5 ms image reconstruction speed in our data, while the image quality was as good as that of the data-adaptive beamformers. These results demonstrated the potential of the deep beamformer for high-resolution monitoring of microbubble cavitation activities for ultrasound therapy.
Limited-View Photoacoustic Imaging Reconstruction Via High-quality Self-supervised Neural Representation
Jul 04, 2024


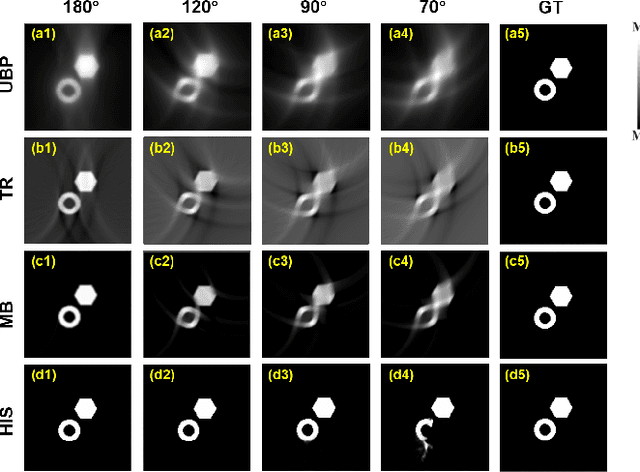
In practical applications within the human body, it is often challenging to fully encompass the target tissue or organ, necessitating the use of limited-view arrays, which can lead to the loss of crucial information. Addressing the reconstruction of photoacoustic sensor signals in limited-view detection spaces has become a focal point of current research. In this study, we introduce a self-supervised network termed HIgh-quality Self-supervised neural representation (HIS), which tackles the inverse problem of photoacoustic imaging to reconstruct high-quality photoacoustic images from sensor data acquired under limited viewpoints. We regard the desired reconstructed photoacoustic image as an implicit continuous function in 2D image space, viewing the pixels of the image as sparse discrete samples. The HIS's objective is to learn the continuous function from limited observations by utilizing a fully connected neural network combined with Fourier feature position encoding. By simply minimizing the error between the network's predicted sensor data and the actual sensor data, HIS is trained to represent the observed continuous model. The results indicate that the proposed HIS model offers superior image reconstruction quality compared to three commonly used methods for photoacoustic image reconstruction.
Sparse-view Signal-domain Photoacoustic Tomography Reconstruction Method Based on Neural Representation
Jun 25, 2024



Photoacoustic tomography is a hybrid biomedical technology, which combines the advantages of acoustic and optical imaging. However, for the conventional image reconstruction method, the image quality is affected obviously by artifacts under the condition of sparse sampling. in this paper, a novel model-based sparse reconstruction method via implicit neural representation was proposed for improving the image quality reconstructed from sparse data. Specially, the initial acoustic pressure distribution was modeled as a continuous function of spatial coordinates, and parameterized by a multi-layer perceptron. The weights of multi-layer perceptron were determined by training the network in self-supervised manner. And the total variation regularization term was used to offer the prior knowledge. We compared our result with some ablation studies, and the results show that out method outperforms existing methods on simulation and experimental data. Under the sparse sampling condition, our method can suppress the artifacts and avoid the ill-posed problem effectively, which reconstruct images with higher signal-to-noise ratio and contrast-to-noise ratio than traditional methods. The high-quality results for sparse data make the proposed method hold the potential for further decreasing the hardware cost of photoacoustic tomography system.
Forecasting Human Trajectory from Scene History
Oct 17, 2022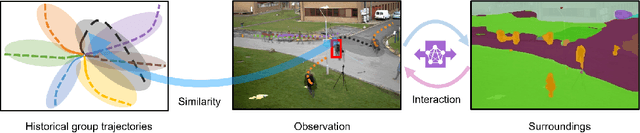

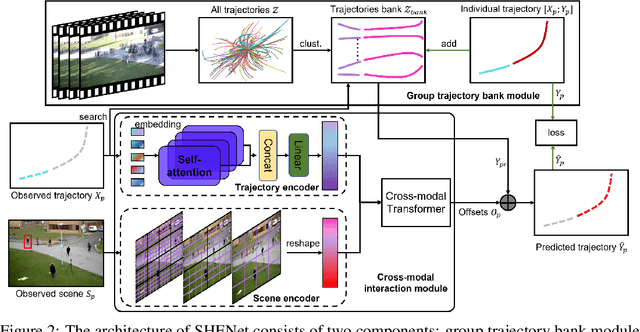
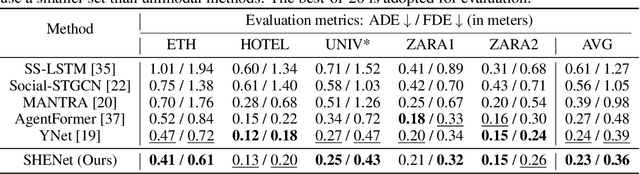
Predicting the future trajectory of a person remains a challenging problem, due to randomness and subjectivity of human movement. However, the moving patterns of human in a constrained scenario typically conform to a limited number of regularities to a certain extent, because of the scenario restrictions and person-person or person-object interactivity. Thus, an individual person in this scenario should follow one of the regularities as well. In other words, a person's subsequent trajectory has likely been traveled by others. Based on this hypothesis, we propose to forecast a person's future trajectory by learning from the implicit scene regularities. We call the regularities, inherently derived from the past dynamics of the people and the environment in the scene, scene history. We categorize scene history information into two types: historical group trajectory and individual-surroundings interaction. To exploit these two types of information for trajectory prediction, we propose a novel framework Scene History Excavating Network (SHENet), where the scene history is leveraged in a simple yet effective approach. In particular, we design two components: the group trajectory bank module to extract representative group trajectories as the candidate for future path, and the cross-modal interaction module to model the interaction between individual past trajectory and its surroundings for trajectory refinement. In addition, to mitigate the uncertainty in ground-truth trajectory, caused by the aforementioned randomness and subjectivity of human movement, we propose to include smoothness into the training process and evaluation metrics. We conduct extensive evaluations to validate the efficacy of our proposed framework on ETH, UCY, as well as a new, challenging benchmark dataset PAV, demonstrating superior performance compared to state-of-the-art methods.