 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow intelligent are convolutional neural networks?
Paper and Code

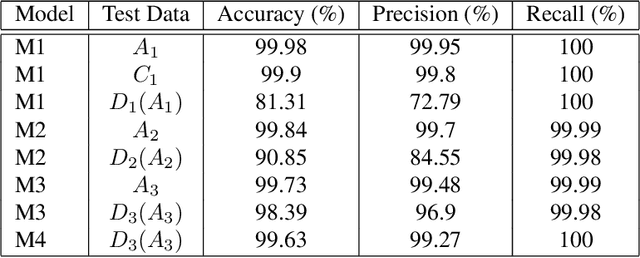


Motivated by the Gestalt pattern theory, and the Winograd Challenge for language understanding, we design synthetic experiments to investigate a deep learning algorithm's ability to infer simple (at least for human) visual concepts, such as symmetry, from examples. A visual concept is represented by randomly generated, positive as well as negative, example images. We then test the ability and speed of algorithms (and humans) to learn the concept from these images. The training and testing are performed progressively in multiple rounds, with each subsequent round deliberately designed to be more complex and confusing than the previous round(s), especially if the concept was not grasped by the learner. However, if the concept was understood, all the deliberate tests would become trivially easy. Our experiments show that humans can often infer a semantic concept quickly after looking at only a very small number of examples (this is often referred to as an "aha moment": a moment of sudden realization), and performs perfectly during all testing rounds (except for careless mistakes). On the contrary, deep convolutional neural networks (DCNN) could approximate some concepts statistically, but only after seeing many (x10^4) more examples. And it will still make obvious mistakes, especially during deliberate testing rounds or on samples outside the training distributions. This signals a lack of true "understanding", or a failure to reach the right "formula" for the semantics. We did find that some concepts are easier for DCNN than others. For example, simple "counting" is more learnable than "symmetry", while "uniformity" or "conformance" are much more difficult for DCNN to learn. To conclude, we propose an "Aha Challenge" for visual perception, calling for focused and quantitative research on Gestalt-style machine intelligence using limited training examples.