 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepRecon: Joint 2D Cardiac Segmentation and 3D Volume Reconstruction via A Structure-Specific Generative Method
Jun 14, 2022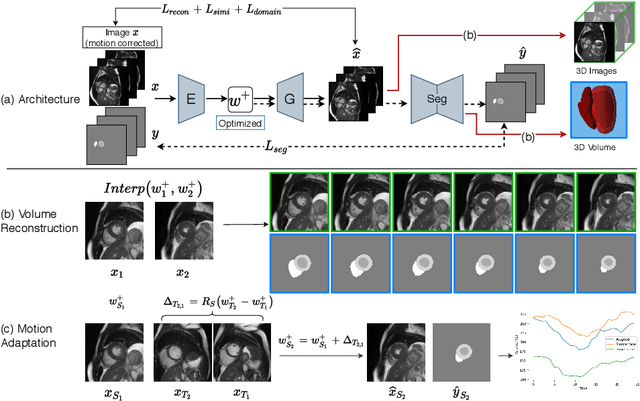
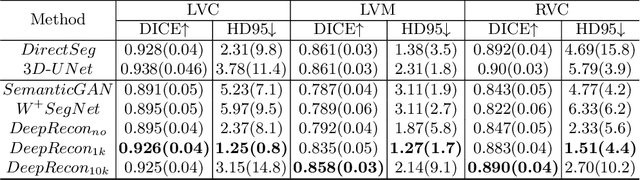
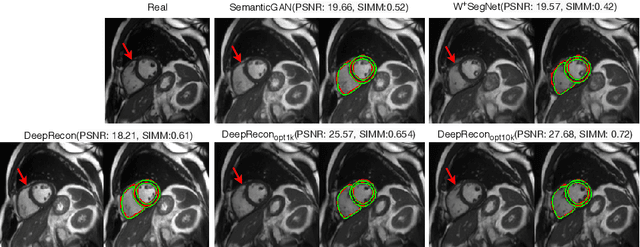
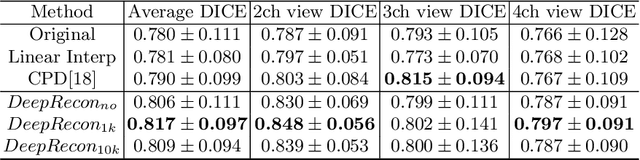
Joint 2D cardiac segmentation and 3D volume reconstruction are fundamental to building statistical cardiac anatomy models and understanding functional mechanisms from motion patterns. However, due to the low through-plane resolution of cine MR and high inter-subject variance, accurately segmenting cardiac images and reconstructing the 3D volume are challenging. In this study, we propose an end-to-end latent-space-based framework, DeepRecon, that generates multiple clinically essential outcomes, including accurate image segmentation, synthetic high-resolution 3D image, and 3D reconstructed volume. Our method identifies the optimal latent representation of the cine image that contains accurate semantic information for cardiac structures. In particular, our model jointly generates synthetic images with accurate semantic information and segmentation of the cardiac structures using the optimal latent representation. We further explore downstream applications of 3D shape reconstruction and 4D motion pattern adaptation by the different latent-space manipulation strategies.The simultaneously generated high-resolution images present a high interpretable value to assess the cardiac shape and motion.Experimental results demonstrate the effectiveness of our approach on multiple fronts including 2D segmentation, 3D reconstruction, downstream 4D motion pattern adaption performance.
TransFusion: Multi-view Divergent Fusion for Medical Image Segmentation with Transformers
Mar 21, 2022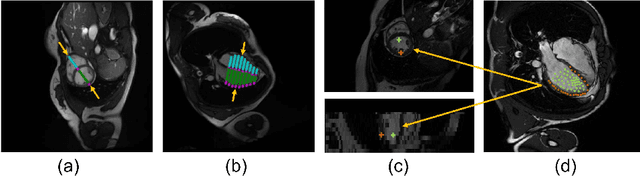
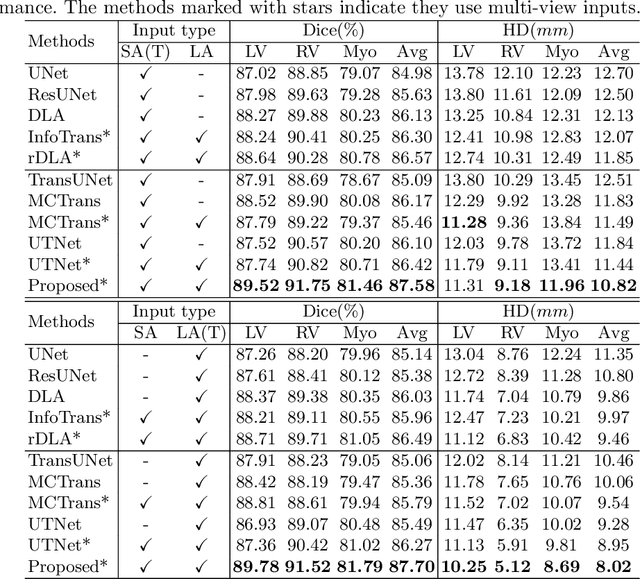
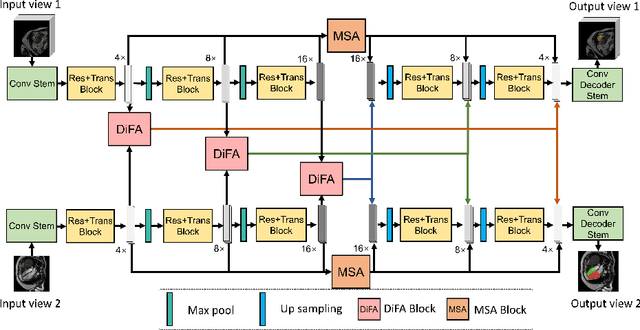
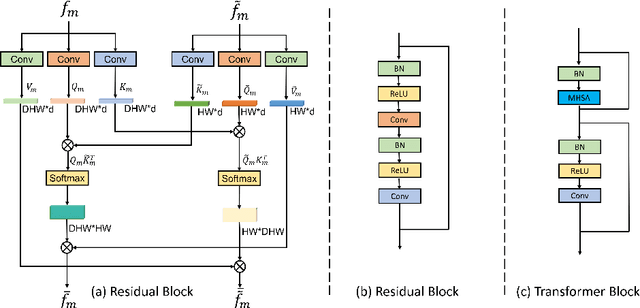
Combining information from multi-view images is crucial to improve the performance and robustness of automated methods for disease diagnosis. However, due to the non-alignment characteristics of multi-view images, building correlation and data fusion across views largely remain an open problem. In this study, we present TransFusion, a Transformer-based architecture to merge divergent multi-view imaging information using convolutional layers and powerful attention mechanisms. In particular, the Divergent Fusion Attention (DiFA) module is proposed for rich cross-view context modeling and semantic dependency mining, addressing the critical issue of capturing long-range correlations between unaligned data from different image views. We further propose the Multi-Scale Attention (MSA) to collect global correspondence of multi-scale feature representations. We evaluate TransFusion on the Multi-Disease, Multi-View \& Multi-Center Right Ventricular Segmentation in Cardiac MRI (M\&Ms-2) challenge cohort. TransFusion demonstrates leading performance against the state-of-the-art methods and opens up new perspectives for multi-view imaging integration towards robust medical image segmentation.
Modality Bank: Learn multi-modality images across data centers without sharing medical data
Jan 22, 2022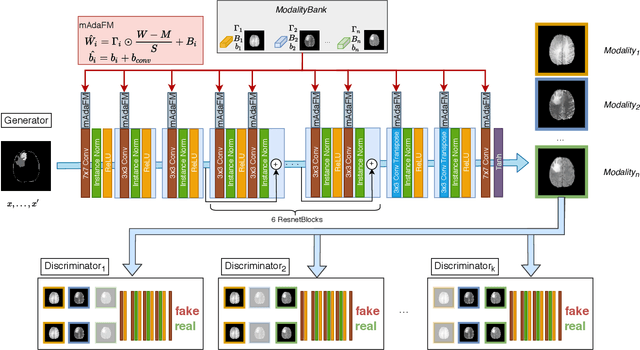
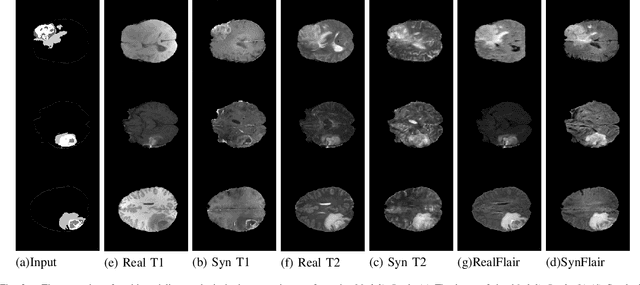
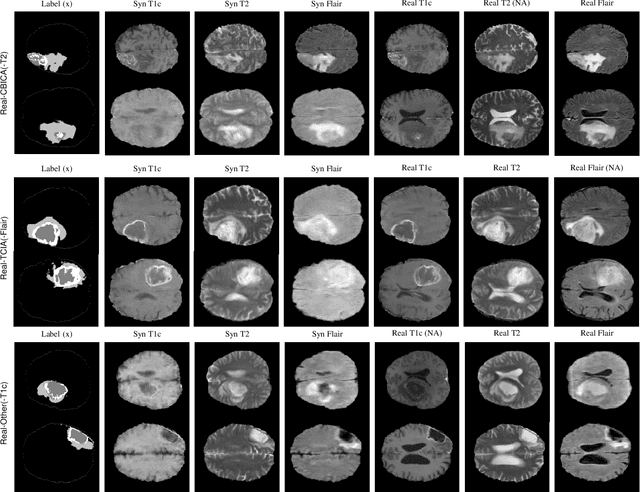
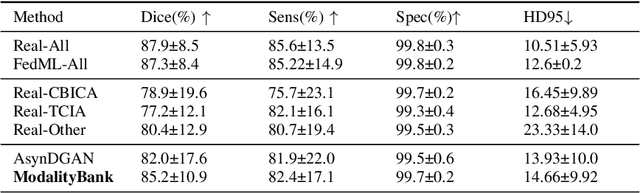
Multi-modality images have been widely used and provide comprehensive information for medical image analysis. However, acquiring all modalities among all institutes is costly and often impossible in clinical settings. To leverage more comprehensive multi-modality information, we propose a privacy secured decentralized multi-modality adaptive learning architecture named ModalityBank. Our method could learn a set of effective domain-specific modulation parameters plugged into a common domain-agnostic network. We demonstrate by switching different sets of configurations, the generator could output high-quality images for a specific modality. Our method could also complete the missing modalities across all data centers, thus could be used for modality completion purposes. The downstream task trained from the synthesized multi-modality samples could achieve higher performance than learning from one real data center and achieve close-to-real performance compare with all real images.
DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
Mar 29, 2021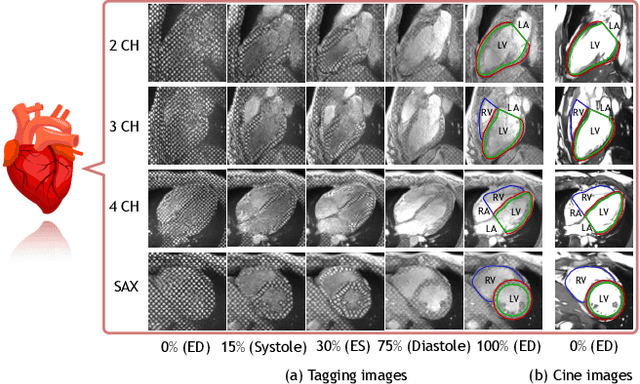
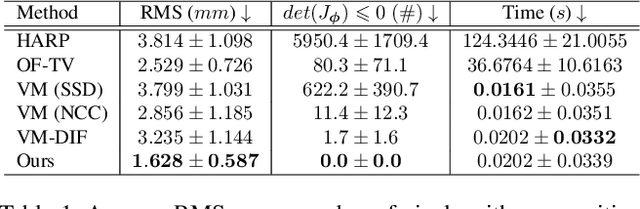
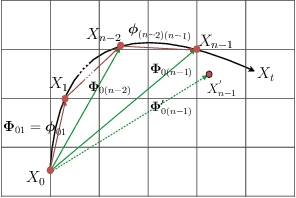
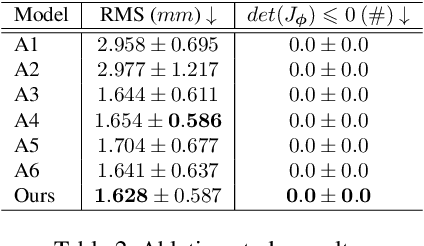
Cardiac tagging magnetic resonance imaging (t-MRI) is the gold standard for regional myocardium deformation and cardiac strain estimation. However, this technique has not been widely used in clinical diagnosis, as a result of the difficulty of motion tracking encountered with t-MRI images. In this paper, we propose a novel deep learning-based fully unsupervised method for in vivo motion tracking on t-MRI images. We first estimate the motion field (INF) between any two consecutive t-MRI frames by a bi-directional generative diffeomorphic registration neural network. Using this result, we then estimate the Lagrangian motion field between the reference frame and any other frame through a differentiable composition layer. By utilizing temporal information to perform reasonable estimations on spatio-temporal motion fields, this novel method provides a useful solution for motion tracking and image registration in dynamic medical imaging. Our method has been validated on a representative clinical t-MRI dataset; the experimental results show that our method is superior to conventional motion tracking methods in terms of landmark tracking accuracy and inference efficiency.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
Learn distributed GAN with Temporary Discriminators
Jul 17, 2020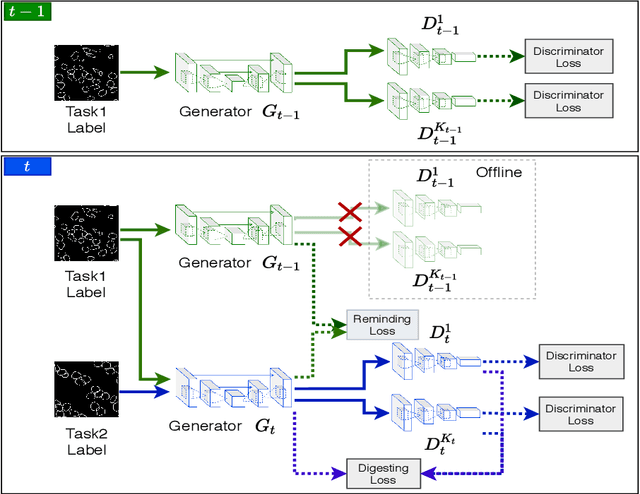
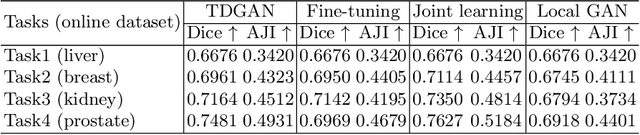

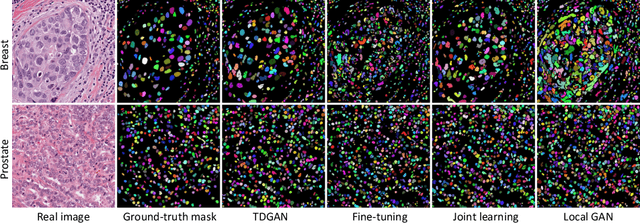
In this work, we propose a method for training distributed GAN with sequential temporary discriminators. Our proposed method tackles the challenge of training GAN in the federated learning manner: How to update the generator with a flow of temporary discriminators? We apply our proposed method to learn a self-adaptive generator with a series of local discriminators from multiple data centers. We show our design of loss function indeed learns the correct distribution with provable guarantees. The empirical experiments show that our approach is capable of generating synthetic data which is practical for real-world applications such as training a segmentation model.
Weakly Supervised Deep Nuclei Segmentation Using Partial Points Annotation in Histopathology Images
Jul 10, 2020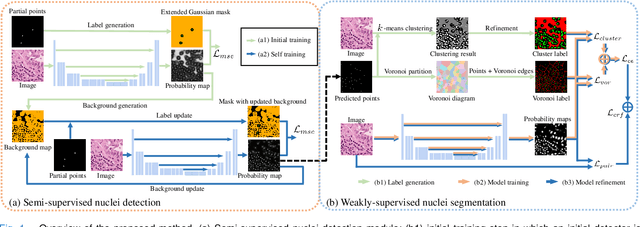
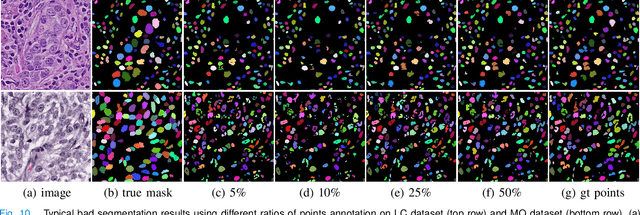
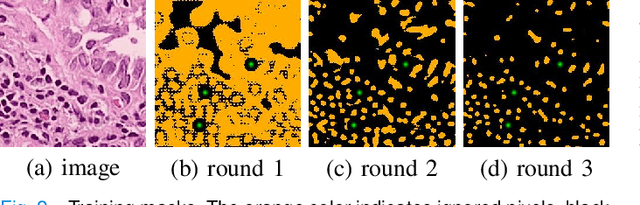

Nuclei segmentation is a fundamental task in histopathology image analysis. Typically, such segmentation tasks require significant effort to manually generate accurate pixel-wise annotations for fully supervised training. To alleviate such tedious and manual effort, in this paper we propose a novel weakly supervised segmentation framework based on partial points annotation, i.e., only a small portion of nuclei locations in each image are labeled. The framework consists of two learning stages. In the first stage, we design a semi-supervised strategy to learn a detection model from partially labeled nuclei locations. Specifically, an extended Gaussian mask is designed to train an initial model with partially labeled data. Then, selftraining with background propagation is proposed to make use of the unlabeled regions to boost nuclei detection and suppress false positives. In the second stage, a segmentation model is trained from the detected nuclei locations in a weakly-supervised fashion. Two types of coarse labels with complementary information are derived from the detected points and are then utilized to train a deep neural network. The fully-connected conditional random field loss is utilized in training to further refine the model without introducing extra computational complexity during inference. The proposed method is extensively evaluated on two nuclei segmentation datasets. The experimental results demonstrate that our method can achieve competitive performance compared to the fully supervised counterpart and the state-of-the-art methods while requiring significantly less annotation effort.
Collaborative Multi-agent Learning for MR Knee Articular Cartilage Segmentation
Aug 13, 2019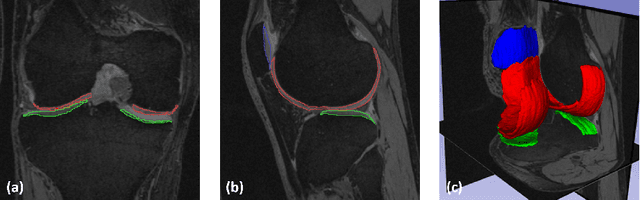
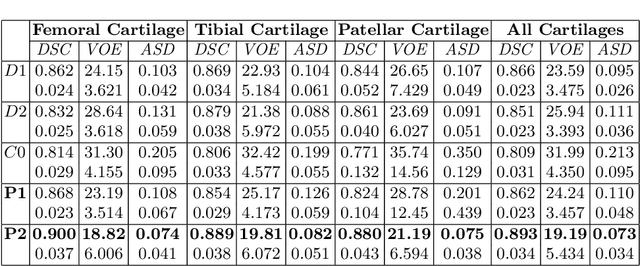
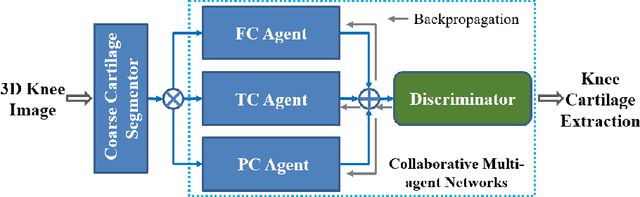
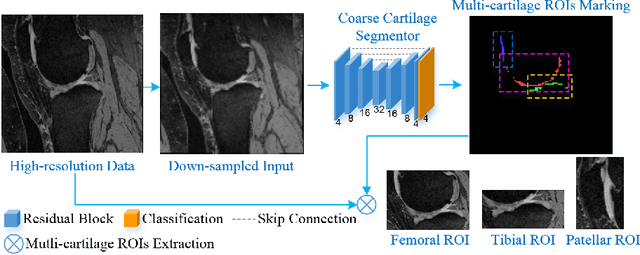
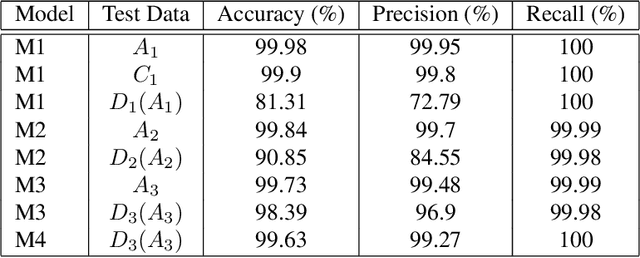
The 3D morphology and quantitative assessment of knee articular cartilages (i.e., femoral, tibial, and patellar cartilage) in magnetic resonance (MR) imaging is of great importance for knee radiographic osteoarthritis (OA) diagnostic decision making. However, effective and efficient delineation of all the knee articular cartilages in large-sized and high-resolution 3D MR knee data is still an open challenge. In this paper, we propose a novel framework to solve the MR knee cartilage segmentation task. The key contribution is the adversarial learning based collaborative multi-agent segmentation network. In the proposed network, we use three parallel segmentation agents to label cartilages in their respective region of interest (ROI), and then fuse the three cartilages by a novel ROI-fusion layer. The collaborative learning is driven by an adversarial sub-network. The ROI-fusion layer not only fuses the individual cartilages from multiple agents, but also backpropagates the training loss from the adversarial sub-network to each agent to enable joint learning of shape and spatial constraints. Extensive evaluations are conducted on a dataset including hundreds of MR knee volumes with diverse populations, and the proposed method shows superior performance.
How intelligent are convolutional neural networks?
Oct 31, 2017


Motivated by the Gestalt pattern theory, and the Winograd Challenge for language understanding, we design synthetic experiments to investigate a deep learning algorithm's ability to infer simple (at least for human) visual concepts, such as symmetry, from examples. A visual concept is represented by randomly generated, positive as well as negative, example images. We then test the ability and speed of algorithms (and humans) to learn the concept from these images. The training and testing are performed progressively in multiple rounds, with each subsequent round deliberately designed to be more complex and confusing than the previous round(s), especially if the concept was not grasped by the learner. However, if the concept was understood, all the deliberate tests would become trivially easy. Our experiments show that humans can often infer a semantic concept quickly after looking at only a very small number of examples (this is often referred to as an "aha moment": a moment of sudden realization), and performs perfectly during all testing rounds (except for careless mistakes). On the contrary, deep convolutional neural networks (DCNN) could approximate some concepts statistically, but only after seeing many (x10^4) more examples. And it will still make obvious mistakes, especially during deliberate testing rounds or on samples outside the training distributions. This signals a lack of true "understanding", or a failure to reach the right "formula" for the semantics. We did find that some concepts are easier for DCNN than others. For example, simple "counting" is more learnable than "symmetry", while "uniformity" or "conformance" are much more difficult for DCNN to learn. To conclude, we propose an "Aha Challenge" for visual perception, calling for focused and quantitative research on Gestalt-style machine intelligence using limited training examples.