 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
Plug-and-Play Diffusion Distillation
Jun 04, 2024



Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1\% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this "plug-and-play" functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Modality Bank: Learn multi-modality images across data centers without sharing medical data
Jan 22, 2022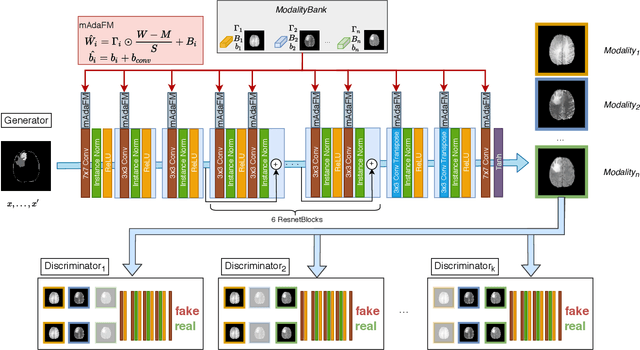
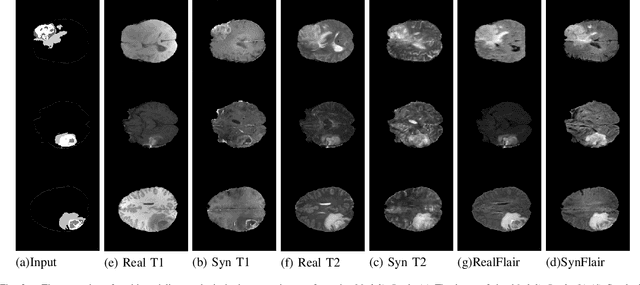
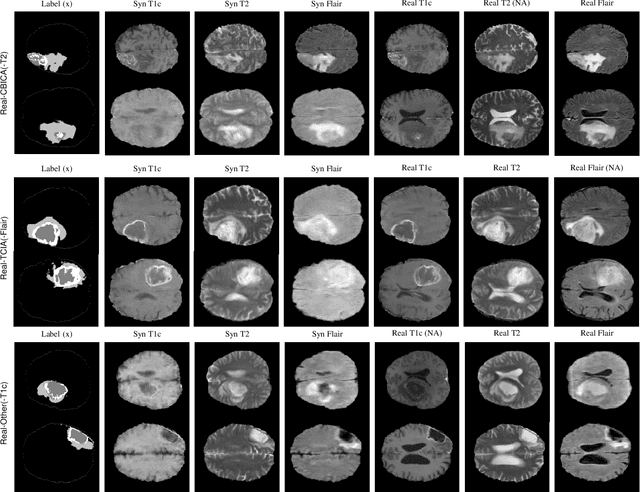
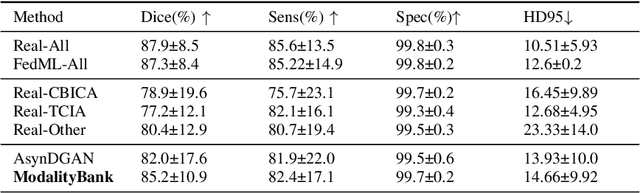
Multi-modality images have been widely used and provide comprehensive information for medical image analysis. However, acquiring all modalities among all institutes is costly and often impossible in clinical settings. To leverage more comprehensive multi-modality information, we propose a privacy secured decentralized multi-modality adaptive learning architecture named ModalityBank. Our method could learn a set of effective domain-specific modulation parameters plugged into a common domain-agnostic network. We demonstrate by switching different sets of configurations, the generator could output high-quality images for a specific modality. Our method could also complete the missing modalities across all data centers, thus could be used for modality completion purposes. The downstream task trained from the synthesized multi-modality samples could achieve higher performance than learning from one real data center and achieve close-to-real performance compare with all real images.
Object-Guided Instance Segmentation With Auxiliary Feature Refinement for Biological Images
Jun 14, 2021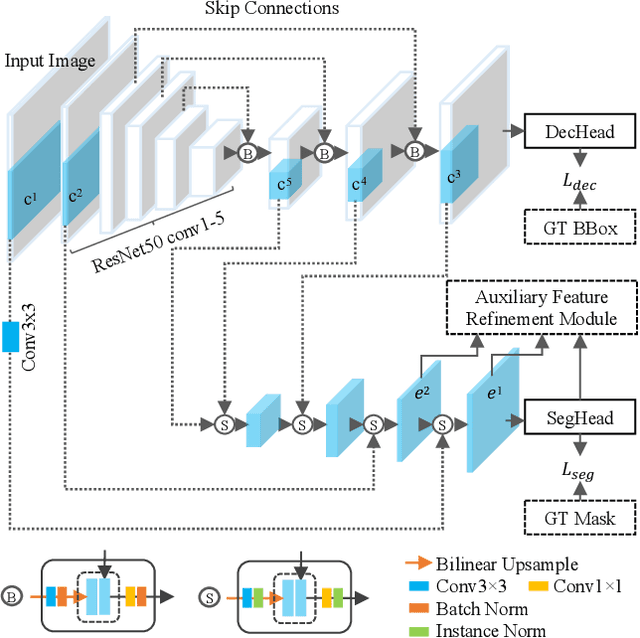
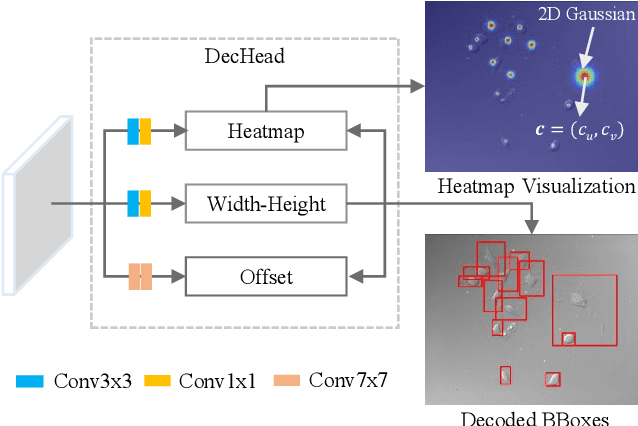
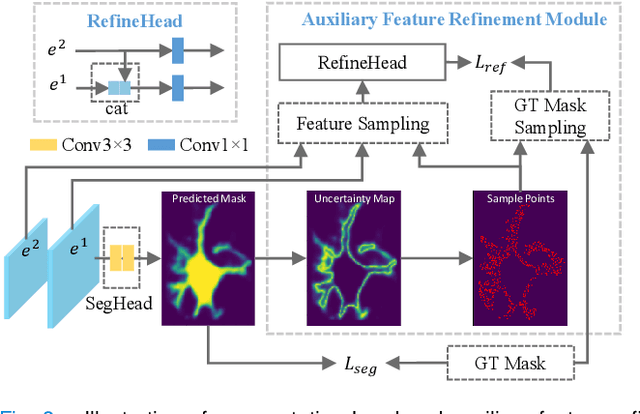

Instance segmentation is of great importance for many biological applications, such as study of neural cell interactions, plant phenotyping, and quantitatively measuring how cells react to drug treatment. In this paper, we propose a novel box-based instance segmentation method. Box-based instance segmentation methods capture objects via bounding boxes and then perform individual segmentation within each bounding box region. However, existing methods can hardly differentiate the target from its neighboring objects within the same bounding box region due to their similar textures and low-contrast boundaries. To deal with this problem, in this paper, we propose an object-guided instance segmentation method. Our method first detects the center points of the objects, from which the bounding box parameters are then predicted. To perform segmentation, an object-guided coarse-to-fine segmentation branch is built along with the detection branch. The segmentation branch reuses the object features as guidance to separate target object from the neighboring ones within the same bounding box region. To further improve the segmentation quality, we design an auxiliary feature refinement module that densely samples and refines point-wise features in the boundary regions. Experimental results on three biological image datasets demonstrate the advantages of our method. The code will be available at https://github.com/yijingru/ObjGuided-Instance-Segmentation.
Liver Fibrosis and NAS scoring from CT images using self-supervised learning and texture encoding
Mar 15, 2021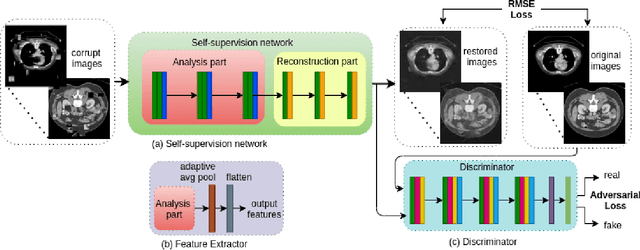

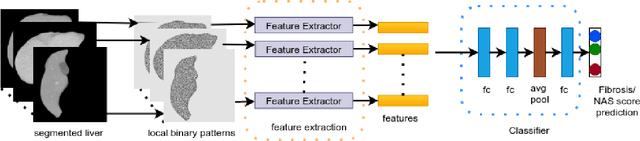

Non-alcoholic fatty liver disease (NAFLD) is one of the most common causes of chronic liver diseases (CLD) which can progress to liver cancer. The severity and treatment of NAFLD is determined by NAFLD Activity Scores (NAS)and liver fibrosis stage, which are usually obtained from liver biopsy. However, biopsy is invasive in nature and involves risk of procedural complications. Current methods to predict the fibrosis and NAS scores from noninvasive CT images rely heavily on either a large annotated dataset or transfer learning using pretrained networks. However, the availability of a large annotated dataset cannot be always ensured andthere can be domain shifts when using transfer learning. In this work, we propose a self-supervised learning method to address both problems. As the NAFLD causes changes in the liver texture, we also propose to use texture encoded inputs to improve the performance of the model. Given a relatively small dataset with 30 patients, we employ a self-supervised network which achieves better performance than a network trained via transfer learning. The code is publicly available at https://github.com/ananyajana/fibrosis_code.
Training Federated GANs with Theoretical Guarantees: A Universal Aggregation Approach
Feb 09, 2021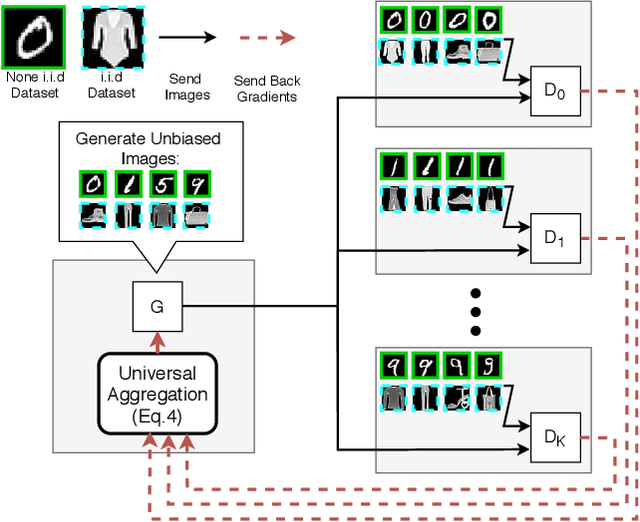

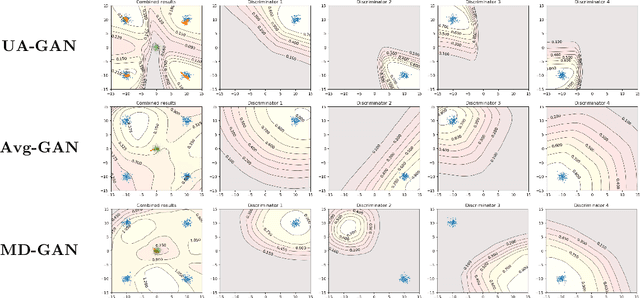
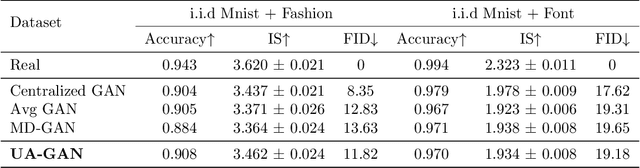
Recently, Generative Adversarial Networks (GANs) have demonstrated their potential in federated learning, i.e., learning a centralized model from data privately hosted by multiple sites. A federatedGAN jointly trains a centralized generator and multiple private discriminators hosted at different sites. A major theoretical challenge for the federated GAN is the heterogeneity of the local data distributions. Traditional approaches cannot guarantee to learn the target distribution, which isa mixture of the highly different local distributions. This paper tackles this theoretical challenge, and for the first time, provides a provably correct framework for federated GAN. We propose a new approach called Universal Aggregation, which simulates a centralized discriminator via carefully aggregating the mixture of all private discriminators. We prove that a generator trained with this simulated centralized discriminator can learn the desired target distribution. Through synthetic and real datasets, we show that our method can learn the mixture of largely different distributions where existing federated GAN methods fail.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
Deep Learning based NAS Score and Fibrosis Stage Prediction from CT and Pathology Data
Sep 22, 2020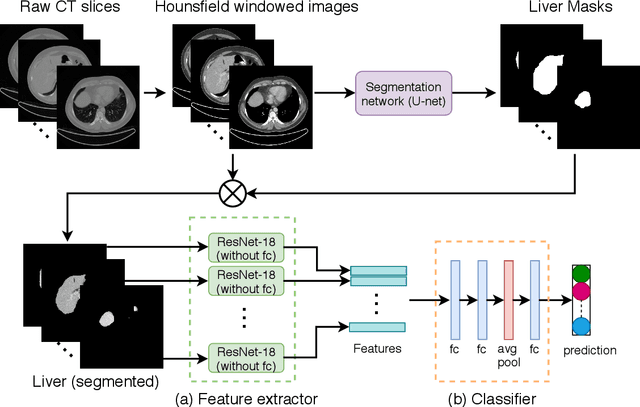
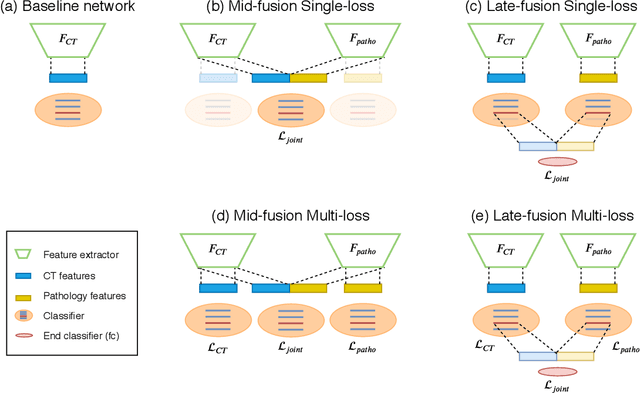
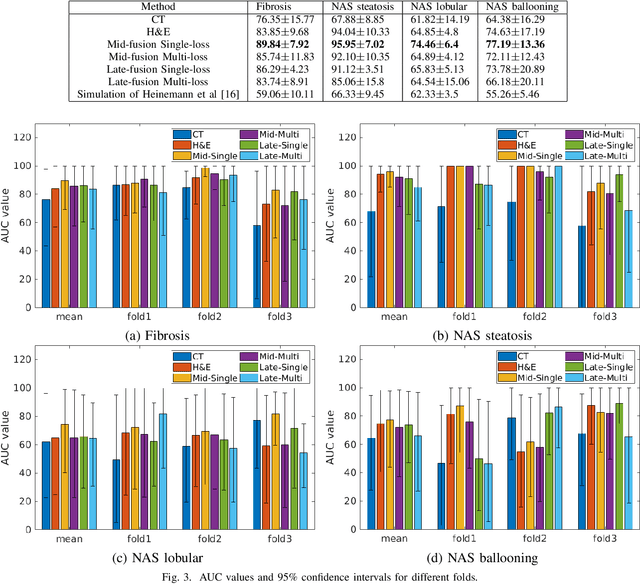

Non-Alcoholic Fatty Liver Disease (NAFLD) is becoming increasingly prevalent in the world population. Without diagnosis at the right time, NAFLD can lead to non-alcoholic steatohepatitis (NASH) and subsequent liver damage. The diagnosis and treatment of NAFLD depend on the NAFLD activity score (NAS) and the liver fibrosis stage, which are usually evaluated from liver biopsies by pathologists. In this work, we propose a novel method to automatically predict NAS score and fibrosis stage from CT data that is non-invasive and inexpensive to obtain compared with liver biopsy. We also present a method to combine the information from CT and H\&E stained pathology data to improve the performance of NAS score and fibrosis stage prediction, when both types of data are available. This is of great value to assist the pathologists in computer-aided diagnosis process. Experiments on a 30-patient dataset illustrate the effectiveness of our method.