 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation
Dec 31, 2025In this work, we show that the impact of model capacity varies across timesteps: it is crucial for the early and late stages but largely negligible during the intermediate stage. Accordingly, we propose FlowBlending, a stage-aware multi-model sampling strategy that employs a large model and a small model at capacity-sensitive stages and intermediate stages, respectively. We further introduce simple criteria to choose stage boundaries and provide a velocity-divergence analysis as an effective proxy for identifying capacity-sensitive regions. Across LTX-Video (2B/13B) and WAN 2.1 (1.3B/14B), FlowBlending achieves up to 1.65x faster inference with 57.35% fewer FLOPs, while maintaining the visual fidelity, temporal coherence, and semantic alignment of the large models. FlowBlending is also compatible with existing sampling-acceleration techniques, enabling up to 2x additional speedup. Project page is available at: https://jibin86.github.io/flowblending_project_page.
HARIVO: Harnessing Text-to-Image Models for Video Generation
Oct 10, 2024



We present a method to create diffusion-based video models from pretrained Text-to-Image (T2I) models. Recently, AnimateDiff proposed freezing the T2I model while only training temporal layers. We advance this method by proposing a unique architecture, incorporating a mapping network and frame-wise tokens, tailored for video generation while maintaining the diversity and creativity of the original T2I model. Key innovations include novel loss functions for temporal smoothness and a mitigating gradient sampling technique, ensuring realistic and temporally consistent video generation despite limited public video data. We have successfully integrated video-specific inductive biases into the architecture and loss functions. Our method, built on the frozen StableDiffusion model, simplifies training processes and allows for seamless integration with off-the-shelf models like ControlNet and DreamBooth. project page: https://kwonminki.github.io/HARIVO
Plug-and-Play Diffusion Distillation
Jun 04, 2024



Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1\% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this "plug-and-play" functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Feb 22, 2024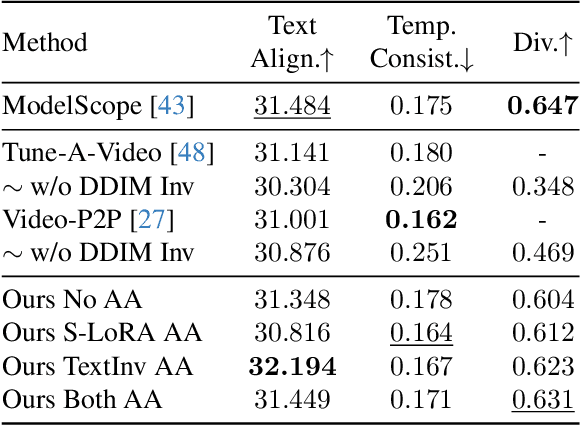
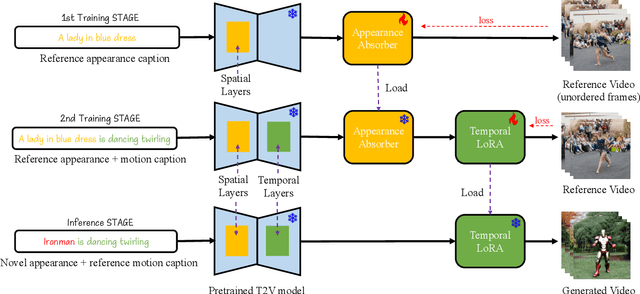


Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapting it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling from the reference videos. To disentangle the spatial and temporal information during the training pipeline, we introduce a novel concept of appearance absorbers that detach the original appearance from the single reference video prior to motion learning. Our proposed method can be easily extended to various downstream tasks, including custom video generation and editing, video appearance customization, and multiple motion combination, in a plug-and-play fashion. Our project page can be found at https://anonymous-314.github.io.
Attribute Based Interpretable Evaluation Metrics for Generative Models
Oct 26, 2023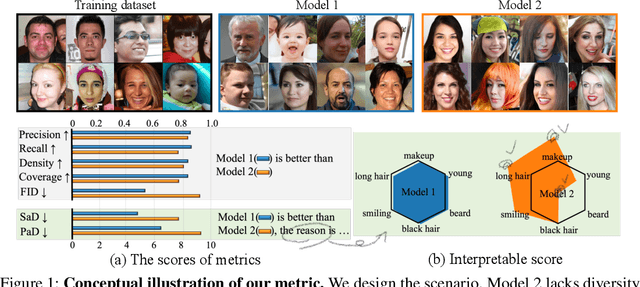
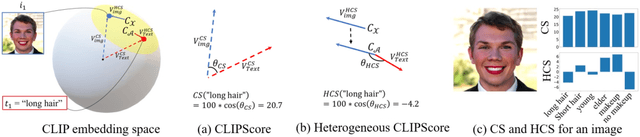
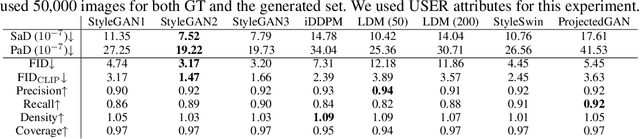
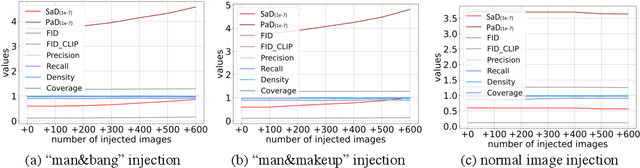
When the training dataset comprises a 1:1 proportion of dogs to cats, a generative model that produces 1:1 dogs and cats better resembles the training species distribution than another model with 3:1 dogs and cats. Can we capture this phenomenon using existing metrics? Unfortunately, we cannot, because these metrics do not provide any interpretability beyond "diversity". In this context, we propose a new evaluation protocol that measures the divergence of a set of generated images from the training set regarding the distribution of attribute strengths as follows. Single-attribute Divergence (SaD) measures the divergence regarding PDFs of a single attribute. Paired-attribute Divergence (PaD) measures the divergence regarding joint PDFs of a pair of attributes. They provide which attributes the models struggle. For measuring the attribute strengths of an image, we propose Heterogeneous CLIPScore (HCS) which measures the cosine similarity between image and text vectors with heterogeneous initial points. With SaD and PaD, we reveal the following about existing generative models. ProjectedGAN generates implausible attribute relationships such as a baby with a beard even though it has competitive scores of existing metrics. Diffusion models struggle to capture diverse colors in the datasets. The larger sampling timesteps of latent diffusion model generate the more minor objects including earrings and necklaces. Stable Diffusion v1.5 better captures the attributes than v2.1. Our metrics lay a foundation for explainable evaluations of generative models.
Understanding the Latent Space of Diffusion Models through the Lens of Riemannian Geometry
Jul 24, 2023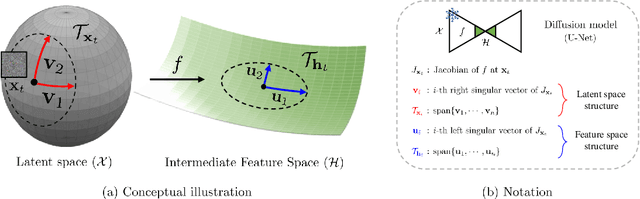
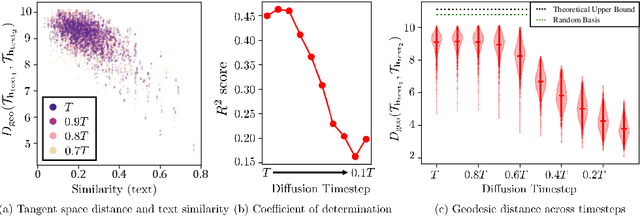

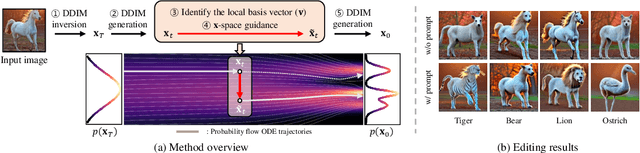
Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. To understand the latent space $\mathbf{x}_t \in \mathcal{X}$, we analyze them from a geometrical perspective. Specifically, we utilize the pullback metric to find the local latent basis in $\mathcal{X}$ and their corresponding local tangent basis in $\mathcal{H}$, the intermediate feature maps of DMs. The discovered latent basis enables unsupervised image editing capability through latent space traversal. We investigate the discovered structure from two perspectives. First, we examine how geometric structure evolves over diffusion timesteps. Through analysis, we show that 1) the model focuses on low-frequency components early in the generative process and attunes to high-frequency details later; 2) At early timesteps, different samples share similar tangent spaces; and 3) The simpler datasets that DMs trained on, the more consistent the tangent space for each timestep. Second, we investigate how the geometric structure changes based on text conditioning in Stable Diffusion. The results show that 1) similar prompts yield comparable tangent spaces; and 2) the model depends less on text conditions in later timesteps. To the best of our knowledge, this paper is the first to present image editing through $\mathbf{x}$-space traversal and provide thorough analyses of the latent structure of DMs.
Training-free Style Transfer Emerges from h-space in Diffusion models
Mar 27, 2023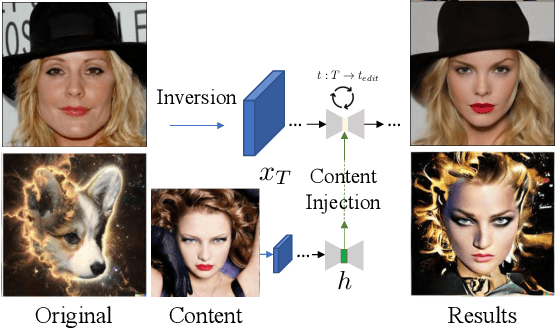
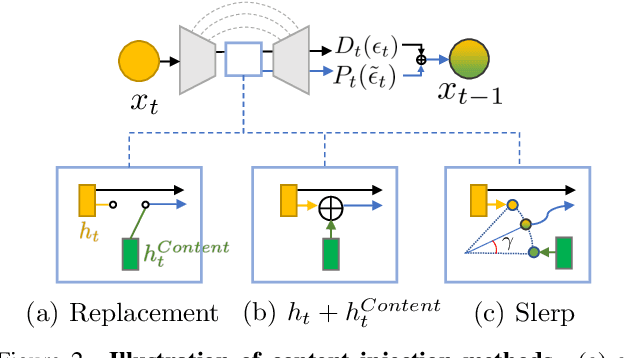


Diffusion models (DMs) synthesize high-quality images in various domains. However, controlling their generative process is still hazy because the intermediate variables in the process are not rigorously studied. Recently, StyleCLIP-like editing of DMs is found in the bottleneck of the U-Net, named $h$-space. In this paper, we discover that DMs inherently have disentangled representations for content and style of the resulting images: $h$-space contains the content and the skip connections convey the style. Furthermore, we introduce a principled way to inject content of one image to another considering progressive nature of the generative process. Briefly, given the original generative process, 1) the feature of the source content should be gradually blended, 2) the blended feature should be normalized to preserve the distribution, 3) the change of skip connections due to content injection should be calibrated. Then, the resulting image has the source content with the style of the original image just like image-to-image translation. Interestingly, injecting contents to styles of unseen domains produces harmonization-like style transfer. To the best of our knowledge, our method introduces the first training-free feed-forward style transfer only with an unconditional pretrained frozen generative network. The code is available at https://curryjung.github.io/DiffStyle/.
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.
FurryGAN: High Quality Foreground-aware Image Synthesis
Aug 22, 2022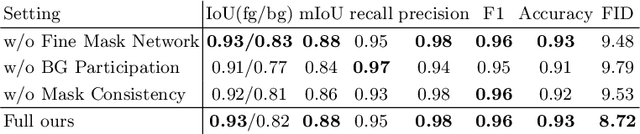
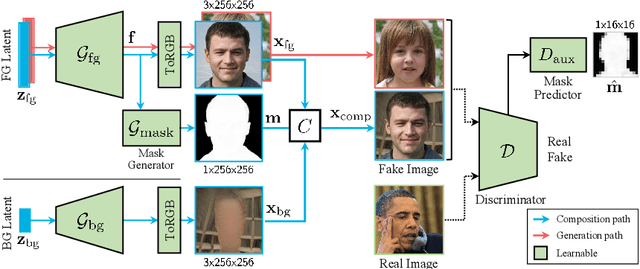
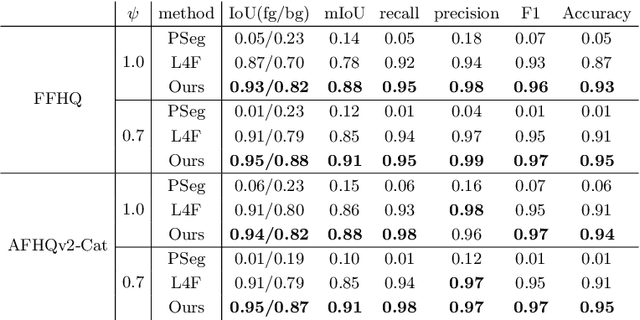
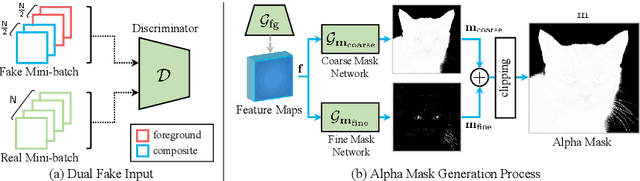
Foreground-aware image synthesis aims to generate images as well as their foreground masks. A common approach is to formulate an image as an masked blending of a foreground image and a background image. It is a challenging problem because it is prone to reach the trivial solution where either image overwhelms the other, i.e., the masks become completely full or empty, and the foreground and background are not meaningfully separated. We present FurryGAN with three key components: 1) imposing both the foreground image and the composite image to be realistic, 2) designing a mask as a combination of coarse and fine masks, and 3) guiding the generator by an auxiliary mask predictor in the discriminator. Our method produces realistic images with remarkably detailed alpha masks which cover hair, fur, and whiskers in a fully unsupervised manner.