 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Style Transfer Emerges from h-space in Diffusion models
Paper and Code
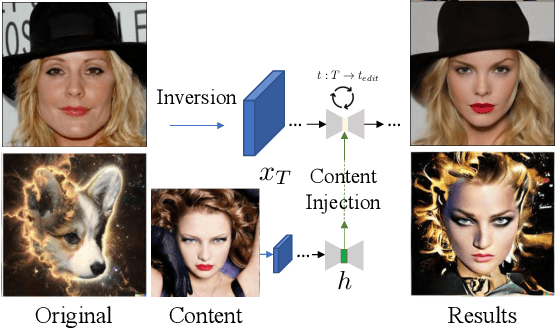
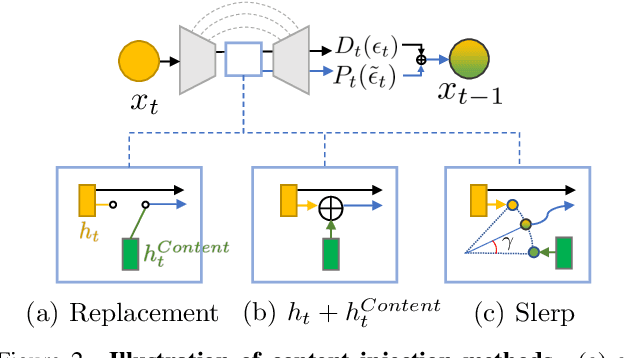


Diffusion models (DMs) synthesize high-quality images in various domains. However, controlling their generative process is still hazy because the intermediate variables in the process are not rigorously studied. Recently, StyleCLIP-like editing of DMs is found in the bottleneck of the U-Net, named $h$-space. In this paper, we discover that DMs inherently have disentangled representations for content and style of the resulting images: $h$-space contains the content and the skip connections convey the style. Furthermore, we introduce a principled way to inject content of one image to another considering progressive nature of the generative process. Briefly, given the original generative process, 1) the feature of the source content should be gradually blended, 2) the blended feature should be normalized to preserve the distribution, 3) the change of skip connections due to content injection should be calibrated. Then, the resulting image has the source content with the style of the original image just like image-to-image translation. Interestingly, injecting contents to styles of unseen domains produces harmonization-like style transfer. To the best of our knowledge, our method introduces the first training-free feed-forward style transfer only with an unconditional pretrained frozen generative network. The code is available at https://curryjung.github.io/DiffStyle/.