 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompensating Spatiotemporally Inconsistent Observations for Online Dynamic 3D Gaussian Splatting
May 02, 2025



Online reconstruction of dynamic scenes is significant as it enables learning scenes from live-streaming video inputs, while existing offline dynamic reconstruction methods rely on recorded video inputs. However, previous online reconstruction approaches have primarily focused on efficiency and rendering quality, overlooking the temporal consistency of their results, which often contain noticeable artifacts in static regions. This paper identifies that errors such as noise in real-world recordings affect temporal inconsistency in online reconstruction. We propose a method that enhances temporal consistency in online reconstruction from observations with temporal inconsistency which is inevitable in cameras. We show that our method restores the ideal observation by subtracting the learned error. We demonstrate that applying our method to various baselines significantly enhances both temporal consistency and rendering quality across datasets. Code, video results, and checkpoints are available at https://bbangsik13.github.io/OR2.
4D Scaffold Gaussian Splatting for Memory Efficient Dynamic Scene Reconstruction
Nov 26, 2024



Existing 4D Gaussian methods for dynamic scene reconstruction offer high visual fidelity and fast rendering. However, these methods suffer from excessive memory and storage demands, which limits their practical deployment. This paper proposes a 4D anchor-based framework that retains visual quality and rendering speed of 4D Gaussians while significantly reducing storage costs. Our method extends 3D scaffolding to 4D space, and leverages sparse 4D grid-aligned anchors with compressed feature vectors. Each anchor models a set of neural 4D Gaussians, each of which represent a local spatiotemporal region. In addition, we introduce a temporal coverage-aware anchor growing strategy to effectively assign additional anchors to under-reconstructed dynamic regions. Our method adjusts the accumulated gradients based on Gaussians' temporal coverage, improving reconstruction quality in dynamic regions. To reduce the number of anchors, we further present enhanced formulations of neural 4D Gaussians. These include the neural velocity, and the temporal opacity derived from a generalized Gaussian distribution. Experimental results demonstrate that our method achieves state-of-the-art visual quality and 97.8% storage reduction over 4DGS.
Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Aug 14, 2024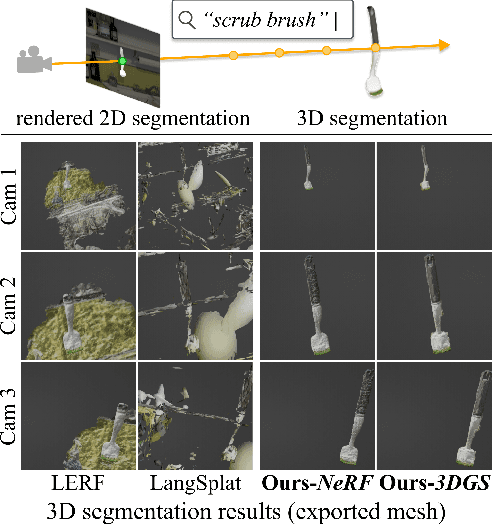
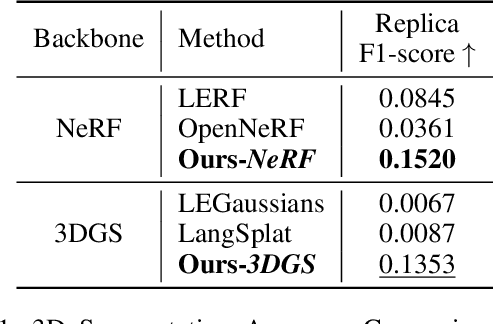
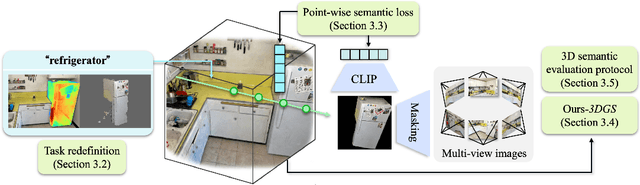
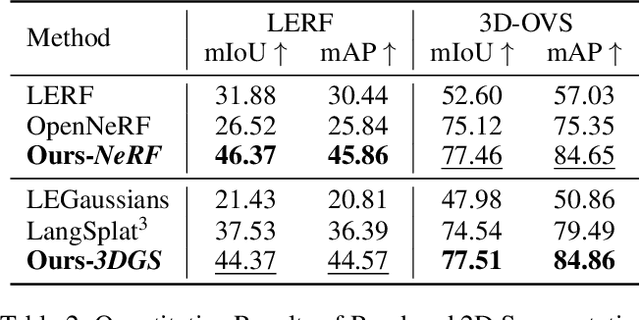
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF
Per-Gaussian Embedding-Based Deformation for Deformable 3D Gaussian Splatting
Apr 04, 2024



As 3D Gaussian Splatting (3DGS) provides fast and high-quality novel view synthesis, it is a natural extension to deform a canonical 3DGS to multiple frames. However, previous works fail to accurately reconstruct dynamic scenes, especially 1) static parts moving along nearby dynamic parts, and 2) some dynamic areas are blurry. We attribute the failure to the wrong design of the deformation field, which is built as a coordinate-based function. This approach is problematic because 3DGS is a mixture of multiple fields centered at the Gaussians, not just a single coordinate-based framework. To resolve this problem, we define the deformation as a function of per-Gaussian embeddings and temporal embeddings. Moreover, we decompose deformations as coarse and fine deformations to model slow and fast movements, respectively. Also, we introduce an efficient training strategy for faster convergence and higher quality. Project page: https://jeongminb.github.io/e-d3dgs/
Sync-NeRF: Generalizing Dynamic NeRFs to Unsynchronized Videos
Oct 20, 2023
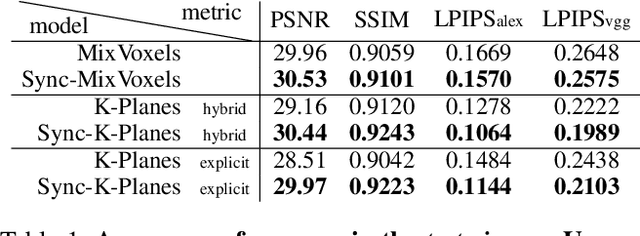
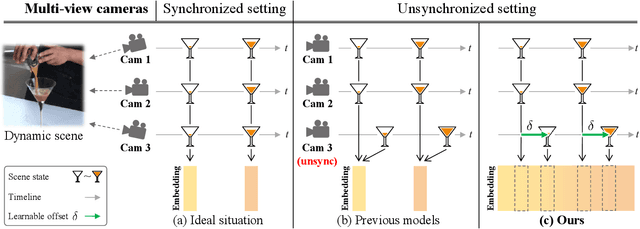
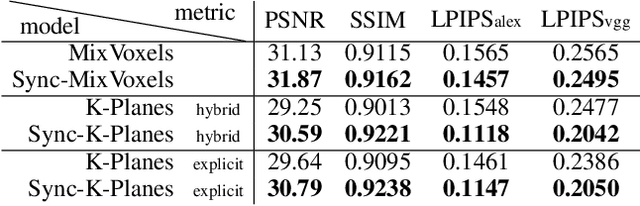
Recent advancements in 4D scene reconstruction using neural radiance fields (NeRF) have demonstrated the ability to represent dynamic scenes from multi-view videos. However, they fail to reconstruct the dynamic scenes and struggle to fit even the training views in unsynchronized settings. It happens because they employ a single latent embedding for a frame while the multi-view images at the frame were actually captured at different moments. To address this limitation, we introduce time offsets for individual unsynchronized videos and jointly optimize the offsets with NeRF. By design, our method is applicable for various baselines and improves them with large margins. Furthermore, finding the offsets naturally works as synchronizing the videos without manual effort. Experiments are conducted on the common Plenoptic Video Dataset and a newly built Unsynchronized Dynamic Blender Dataset to verify the performance of our method. Project page: https://seoha-kim.github.io/sync-nerf
BallGAN: 3D-aware Image Synthesis with a Spherical Background
Jan 22, 2023



3D-aware GANs aim to synthesize realistic 3D scenes such that they can be rendered in arbitrary perspectives to produce images. Although previous methods produce realistic images, they suffer from unstable training or degenerate solutions where the 3D geometry is unnatural. We hypothesize that the 3D geometry is underdetermined due to the insufficient constraint, i.e., being classified as real image to the discriminator is not enough. To solve this problem, we propose to approximate the background as a spherical surface and represent a scene as a union of the foreground placed in the sphere and the thin spherical background. It reduces the degree of freedom in the background field. Accordingly, we modify the volume rendering equation and incorporate dedicated constraints to design a novel 3D-aware GAN framework named BallGAN. BallGAN has multiple advantages as follows. 1) It produces more reasonable 3D geometry; the images of a scene across different viewpoints have better photometric consistency and fidelity than the state-of-the-art methods. 2) The training becomes much more stable. 3) The foreground can be separately rendered on top of different arbitrary backgrounds.
3d human motion generation from the text via gesture action classification and the autoregressive model
Nov 18, 2022



In this paper, a deep learning-based model for 3D human motion generation from the text is proposed via gesture action classification and an autoregressive model. The model focuses on generating special gestures that express human thinking, such as waving and nodding. To achieve the goal, the proposed method predicts expression from the sentences using a text classification model based on a pretrained language model and generates gestures using the gate recurrent unit-based autoregressive model. Especially, we proposed the loss for the embedding space for restoring raw motions and generating intermediate motions well. Moreover, the novel data augmentation method and stop token are proposed to generate variable length motions. To evaluate the text classification model and 3D human motion generation model, a gesture action classification dataset and action-based gesture dataset are collected. With several experiments, the proposed method successfully generates perceptually natural and realistic 3D human motion from the text. Moreover, we verified the effectiveness of the proposed method using a public-available action recognition dataset to evaluate cross-dataset generalization performance.
FurryGAN: High Quality Foreground-aware Image Synthesis
Aug 22, 2022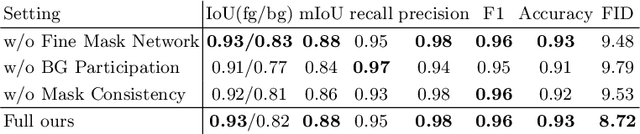
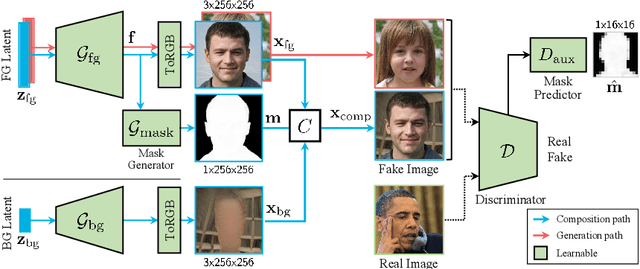
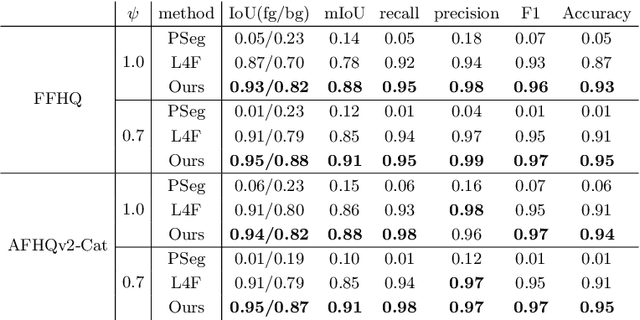
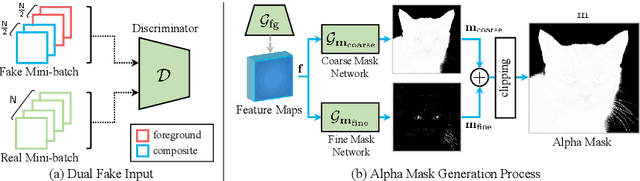
Foreground-aware image synthesis aims to generate images as well as their foreground masks. A common approach is to formulate an image as an masked blending of a foreground image and a background image. It is a challenging problem because it is prone to reach the trivial solution where either image overwhelms the other, i.e., the masks become completely full or empty, and the foreground and background are not meaningfully separated. We present FurryGAN with three key components: 1) imposing both the foreground image and the composite image to be realistic, 2) designing a mask as a combination of coarse and fine masks, and 3) guiding the generator by an auxiliary mask predictor in the discriminator. Our method produces realistic images with remarkably detailed alpha masks which cover hair, fur, and whiskers in a fully unsupervised manner.