 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Aug 14, 2024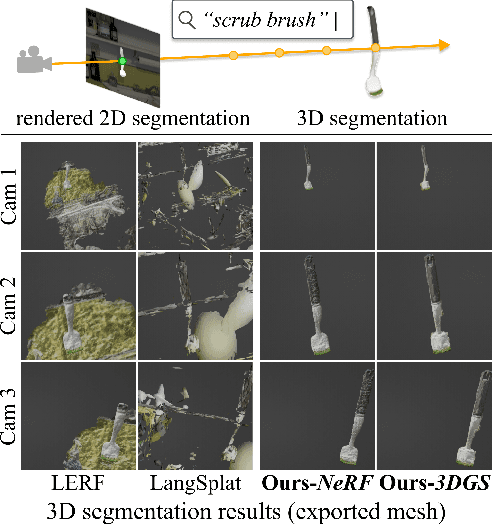
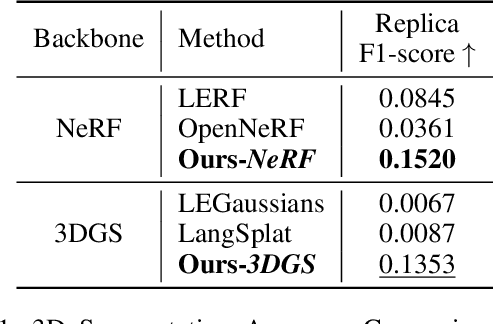
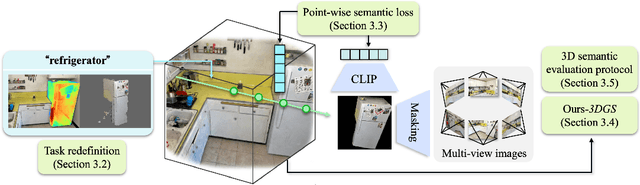
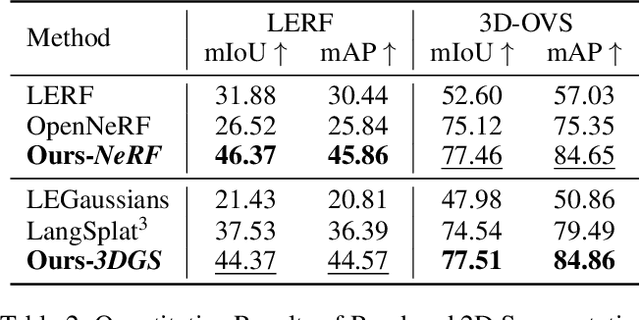
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF