 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompensating Spatiotemporally Inconsistent Observations for Online Dynamic 3D Gaussian Splatting
May 02, 2025



Online reconstruction of dynamic scenes is significant as it enables learning scenes from live-streaming video inputs, while existing offline dynamic reconstruction methods rely on recorded video inputs. However, previous online reconstruction approaches have primarily focused on efficiency and rendering quality, overlooking the temporal consistency of their results, which often contain noticeable artifacts in static regions. This paper identifies that errors such as noise in real-world recordings affect temporal inconsistency in online reconstruction. We propose a method that enhances temporal consistency in online reconstruction from observations with temporal inconsistency which is inevitable in cameras. We show that our method restores the ideal observation by subtracting the learned error. We demonstrate that applying our method to various baselines significantly enhances both temporal consistency and rendering quality across datasets. Code, video results, and checkpoints are available at https://bbangsik13.github.io/OR2.
Culture-TRIP: Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinment
Feb 24, 2025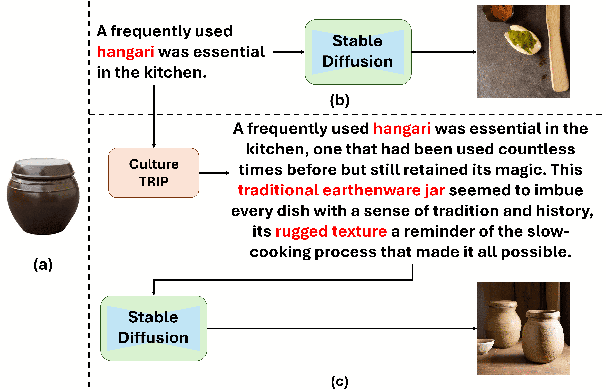

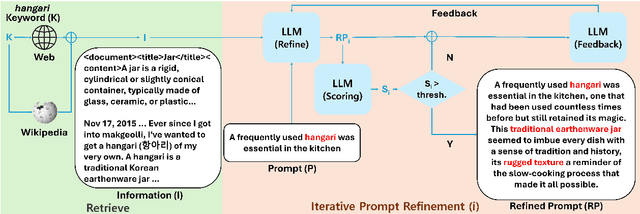
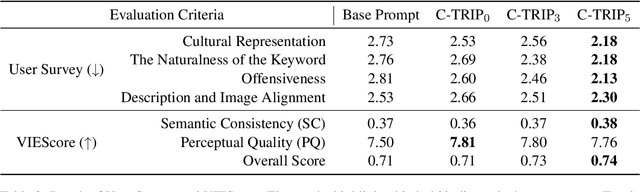
Text-to-Image models, including Stable Diffusion, have significantly improved in generating images that are highly semantically aligned with the given prompts. However, existing models may fail to produce appropriate images for the cultural concepts or objects that are not well known or underrepresented in western cultures, such as `hangari' (Korean utensil). In this paper, we propose a novel approach, Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinement (Culture-TRIP), which refines the prompt in order to improve the alignment of the image with such culture nouns in text-to-image models. Our approach (1) retrieves cultural contexts and visual details related to the culture nouns in the prompt and (2) iteratively refines and evaluates the prompt based on a set of cultural criteria and large language models. The refinement process utilizes the information retrieved from Wikipedia and the Web. Our user survey, conducted with 66 participants from eight different countries demonstrates that our proposed approach enhances the alignment between the images and the prompts. In particular, C-TRIP demonstrates improved alignment between the generated images and underrepresented culture nouns. Resource can be found at https://shane3606.github.io/Culture-TRIP.
Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Aug 14, 2024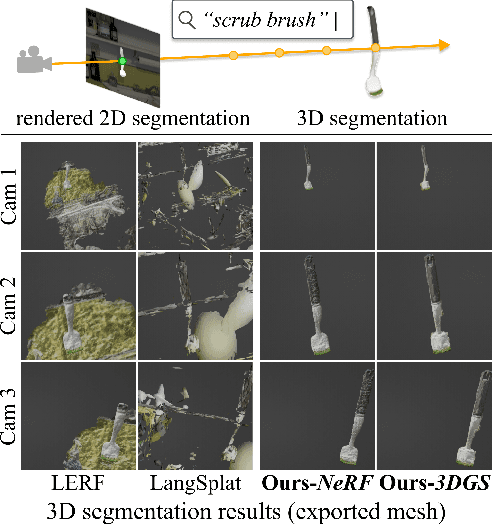
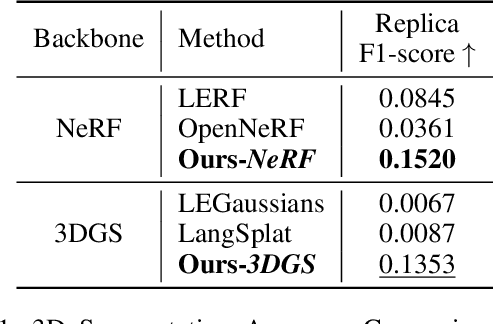
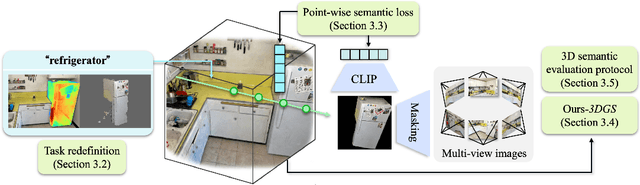
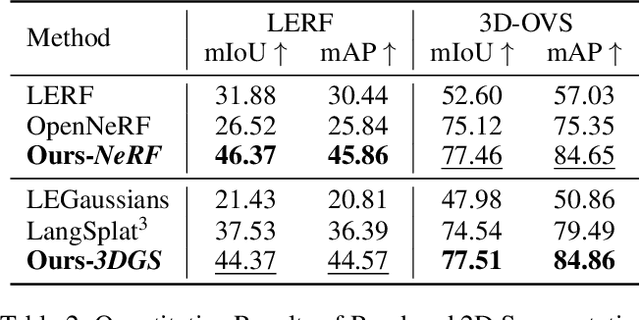
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF
Per-Gaussian Embedding-Based Deformation for Deformable 3D Gaussian Splatting
Apr 04, 2024



As 3D Gaussian Splatting (3DGS) provides fast and high-quality novel view synthesis, it is a natural extension to deform a canonical 3DGS to multiple frames. However, previous works fail to accurately reconstruct dynamic scenes, especially 1) static parts moving along nearby dynamic parts, and 2) some dynamic areas are blurry. We attribute the failure to the wrong design of the deformation field, which is built as a coordinate-based function. This approach is problematic because 3DGS is a mixture of multiple fields centered at the Gaussians, not just a single coordinate-based framework. To resolve this problem, we define the deformation as a function of per-Gaussian embeddings and temporal embeddings. Moreover, we decompose deformations as coarse and fine deformations to model slow and fast movements, respectively. Also, we introduce an efficient training strategy for faster convergence and higher quality. Project page: https://jeongminb.github.io/e-d3dgs/
CIC: A framework for Culturally-aware Image Captioning
Feb 08, 2024
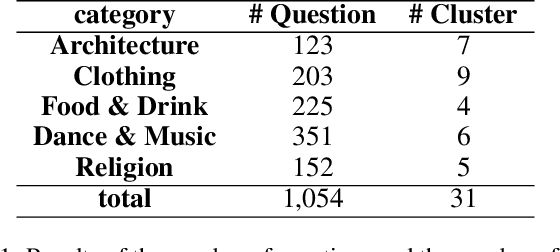
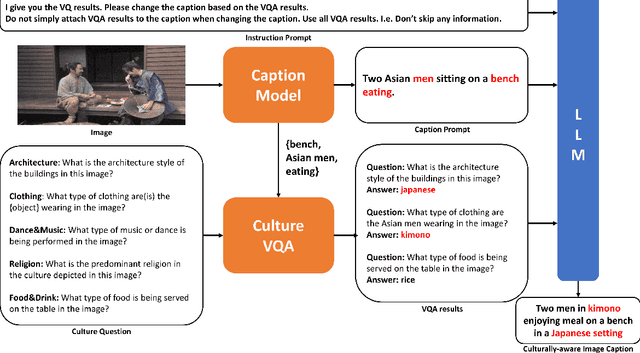

Image Captioning generates descriptive sentences from images using Vision-Language Pre-trained models (VLPs) such as BLIP, which has improved greatly. However, current methods lack the generation of detailed descriptive captions for the cultural elements depicted in the images, such as the traditional clothing worn by people from Asian cultural groups. In this paper, we propose a new framework, \textbf{Culturally-aware Image Captioning (CIC)}, that generates captions and describes cultural elements extracted from cultural visual elements in images representing cultures. Inspired by methods combining visual modality and Large Language Models (LLMs) through appropriate prompts, our framework (1) generates questions based on cultural categories from images, (2) extracts cultural visual elements from Visual Question Answering (VQA) using generated questions, and (3) generates culturally-aware captions using LLMs with the prompts. Our human evaluation conducted on 45 participants from 4 different cultural groups with a high understanding of the corresponding culture shows that our proposed framework generates more culturally descriptive captions when compared to the image captioning baseline based on VLPs. Our code and dataset will be made publicly available upon acceptance.
SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation
Jan 16, 2024



Accurate representation in media is known to improve the well-being of the people who consume it. Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures. We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB) and (2) proposing a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve. SCoFT is designed to prevent overfitting on small datasets, encode only high-level information from the data, and shift the generated distribution away from misrepresentations encoded in a pretrained model. Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that fine-tuning on CCUB consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline, which is further improved with our SCoFT technique.
Sync-NeRF: Generalizing Dynamic NeRFs to Unsynchronized Videos
Oct 20, 2023
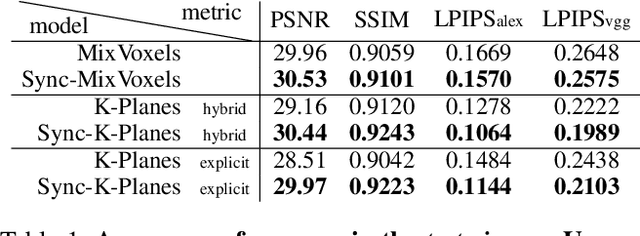
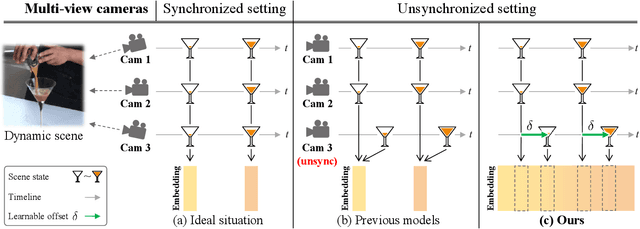
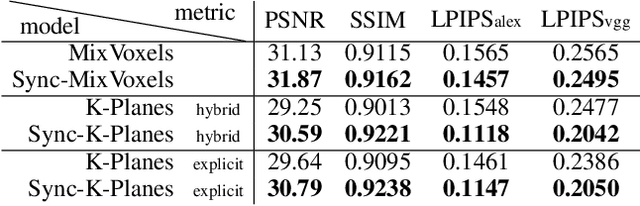
Recent advancements in 4D scene reconstruction using neural radiance fields (NeRF) have demonstrated the ability to represent dynamic scenes from multi-view videos. However, they fail to reconstruct the dynamic scenes and struggle to fit even the training views in unsynchronized settings. It happens because they employ a single latent embedding for a frame while the multi-view images at the frame were actually captured at different moments. To address this limitation, we introduce time offsets for individual unsynchronized videos and jointly optimize the offsets with NeRF. By design, our method is applicable for various baselines and improves them with large margins. Furthermore, finding the offsets naturally works as synchronizing the videos without manual effort. Experiments are conducted on the common Plenoptic Video Dataset and a newly built Unsynchronized Dynamic Blender Dataset to verify the performance of our method. Project page: https://seoha-kim.github.io/sync-nerf
Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset
Jan 28, 2023



It has been shown that accurate representation in media improves the well-being of the people who consume it. By contrast, inaccurate representations can negatively affect viewers and lead to harmful perceptions of other cultures. To achieve inclusive representation in generated images, we propose a culturally-aware priming approach for text-to-image synthesis using a small but culturally curated dataset that we collected, known here as Cross-Cultural Understanding Benchmark (CCUB) Dataset, to fight the bias prevalent in giant datasets. Our proposed approach is comprised of two fine-tuning techniques: (1) Adding visual context via fine-tuning a pre-trained text-to-image synthesis model, Stable Diffusion, on the CCUB text-image pairs, and (2) Adding semantic context via automated prompt engineering using the fine-tuned large language model, GPT-3, trained on our CCUB culturally-aware text data. CCUB dataset is curated and our approach is evaluated by people who have a personal relationship with that particular culture. Our experiments indicate that priming using both text and image is effective in improving the cultural relevance and decreasing the offensiveness of generated images while maintaining quality.