 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenDial: Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Mar 29, 2026We present TokenDial, a framework for continuous, slider-style attribute control in pretrained text-to-video generation models. While modern generators produce strong holistic videos, they offer limited control over how much an attribute changes (e.g., effect intensity or motion magnitude) without drifting identity, background, or temporal coherence. TokenDial is built on the observation: additive offsets in the intermediate spatiotemporal visual patch-token space form a semantic control direction, where adjusting the offset magnitude yields coherent, predictable edits for both appearance and motion dynamics. We learn attribute-specific token offsets without retraining the backbone, using pretrained understanding signals: semantic direction matching for appearance and motion-magnitude scaling for motion. We demonstrate TokenDial's effectiveness on diverse attributes and prompts, achieving stronger controllability and higher-quality edits than state-of-the-art baselines, supported by extensive quantitative evaluation and human studies.
ShapeShift: Towards Text-to-Shape Arrangement Synthesis with Content-Aware Geometric Constraints
Mar 18, 2025



While diffusion-based models excel at generating photorealistic images from text, a more nuanced challenge emerges when constrained to using only a fixed set of rigid shapes, akin to solving tangram puzzles or arranging real-world objects to match semantic descriptions. We formalize this problem as shape-based image generation, a new text-guided image-to-image translation task that requires rearranging the input set of rigid shapes into non-overlapping configurations and visually communicating the target concept. Unlike pixel-manipulation approaches, our method, ShapeShift, explicitly parameterizes each shape within a differentiable vector graphics pipeline, iteratively optimizing placement and orientation through score distillation sampling from pretrained diffusion models. To preserve arrangement clarity, we introduce a content-aware collision resolution mechanism that applies minimal semantically coherent adjustments when overlaps occur, ensuring smooth convergence toward physically valid configurations. By bridging diffusion-based semantic guidance with explicit geometric constraints, our approach yields interpretable compositions where spatial relationships clearly embody the textual prompt. Extensive experiments demonstrate compelling results across diverse scenarios, with quantitative and qualitative advantages over alternative techniques.
Spline-FRIDA: Towards Diverse, Humanlike Robot Painting Styles with a Sample-Efficient, Differentiable Brush Stroke Model
Nov 30, 2024A painting is more than just a picture on a wall; a painting is a process comprised of many intentional brush strokes, the shapes of which are an important component of a painting's overall style and message. Prior work in modeling brush stroke trajectories either does not work with real-world robotics or is not flexible enough to capture the complexity of human-made brush strokes. In this work, we introduce Spline-FRIDA which can model complex human brush stroke trajectories. This is achieved by recording artists drawing using motion capture, modeling the extracted trajectories with an autoencoder, and introducing a novel brush stroke dynamics model to the existing robotic painting platform FRIDA. We conducted a survey and found that our open-source Spline-FRIDA approach successfully captures the stroke styles in human drawings and that Spline-FRIDA's brush strokes are more human-like, improve semantic planning, and are more artistic compared to existing robot painting systems with restrictive B\'ezier curve strokes.
CoFRIDA: Self-Supervised Fine-Tuning for Human-Robot Co-Painting
Feb 21, 2024



Prior robot painting and drawing work, such as FRIDA, has focused on decreasing the sim-to-real gap and expanding input modalities for users, but the interaction with these systems generally exists only in the input stages. To support interactive, human-robot collaborative painting, we introduce the Collaborative FRIDA (CoFRIDA) robot painting framework, which can co-paint by modifying and engaging with content already painted by a human collaborator. To improve text-image alignment, FRIDA's major weakness, our system uses pre-trained text-to-image models; however, pre-trained models in the context of real-world co-painting do not perform well because they (1) do not understand the constraints and abilities of the robot and (2) cannot perform co-painting without making unrealistic edits to the canvas and overwriting content. We propose a self-supervised fine-tuning procedure that can tackle both issues, allowing the use of pre-trained state-of-the-art text-image alignment models with robots to enable co-painting in the physical world. Our open-source approach, CoFRIDA, creates paintings and drawings that match the input text prompt more clearly than FRIDA, both from a blank canvas and one with human created work. More generally, our fine-tuning procedure successfully encodes the robot's constraints and abilities into a foundation model, showcasing promising results as an effective method for reducing sim-to-real gaps.
SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation
Jan 16, 2024



Accurate representation in media is known to improve the well-being of the people who consume it. Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures. We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB) and (2) proposing a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve. SCoFT is designed to prevent overfitting on small datasets, encode only high-level information from the data, and shift the generated distribution away from misrepresentations encoded in a pretrained model. Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that fine-tuning on CCUB consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline, which is further improved with our SCoFT technique.
Robot Synesthesia: A Sound and Emotion Guided AI Painter
Feb 09, 2023



If a picture paints a thousand words, sound may voice a million. While recent robotic painting and image synthesis methods have achieved progress in generating visuals from text inputs, the translation of sound into images is vastly unexplored. Generally, sound-based interfaces and sonic interactions have the potential to expand accessibility and control for the user and provide a means to convey complex emotions and the dynamic aspects of the real world. In this paper, we propose an approach for using sound and speech to guide a robotic painting process, known here as robot synesthesia. For general sound, we encode the simulated paintings and input sounds into the same latent space. For speech, we decouple speech into its transcribed text and the tone of the speech. Whereas we use the text to control the content, we estimate the emotions from the tone to guide the mood of the painting. Our approach has been fully integrated with FRIDA, a robotic painting framework, adding sound and speech to FRIDA's existing input modalities, such as text and style. In two surveys, participants were able to correctly guess the emotion or natural sound used to generate a given painting more than twice as likely as random chance. On our sound-guided image manipulation and music-guided paintings, we discuss the results qualitatively.
Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset
Jan 28, 2023



It has been shown that accurate representation in media improves the well-being of the people who consume it. By contrast, inaccurate representations can negatively affect viewers and lead to harmful perceptions of other cultures. To achieve inclusive representation in generated images, we propose a culturally-aware priming approach for text-to-image synthesis using a small but culturally curated dataset that we collected, known here as Cross-Cultural Understanding Benchmark (CCUB) Dataset, to fight the bias prevalent in giant datasets. Our proposed approach is comprised of two fine-tuning techniques: (1) Adding visual context via fine-tuning a pre-trained text-to-image synthesis model, Stable Diffusion, on the CCUB text-image pairs, and (2) Adding semantic context via automated prompt engineering using the fine-tuned large language model, GPT-3, trained on our CCUB culturally-aware text data. CCUB dataset is curated and our approach is evaluated by people who have a personal relationship with that particular culture. Our experiments indicate that priming using both text and image is effective in improving the cultural relevance and decreasing the offensiveness of generated images while maintaining quality.
Towards Real-Time Text2Video via CLIP-Guided, Pixel-Level Optimization
Oct 23, 2022We introduce an approach to generating videos based on a series of given language descriptions. Frames of the video are generated sequentially and optimized by guidance from the CLIP image-text encoder; iterating through language descriptions, weighting the current description higher than others. As opposed to optimizing through an image generator model itself, which tends to be computationally heavy, the proposed approach computes the CLIP loss directly at the pixel level, achieving general content at a speed suitable for near real-time systems. The approach can generate videos in up to 720p resolution, variable frame-rates, and arbitrary aspect ratios at a rate of 1-2 frames per second. Please visit our website to view videos and access our open-source code: https://pschaldenbrand.github.io/text2video/ .
FRIDA: A Collaborative Robot Painter with a Differentiable, Real2Sim2Real Planning Environment
Oct 03, 2022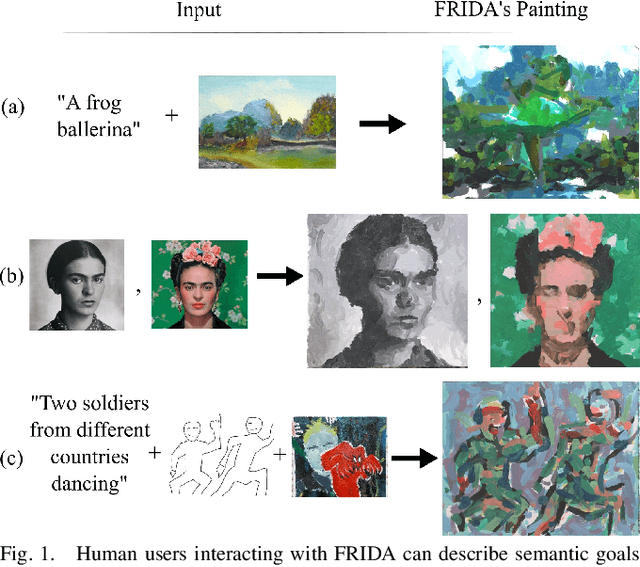
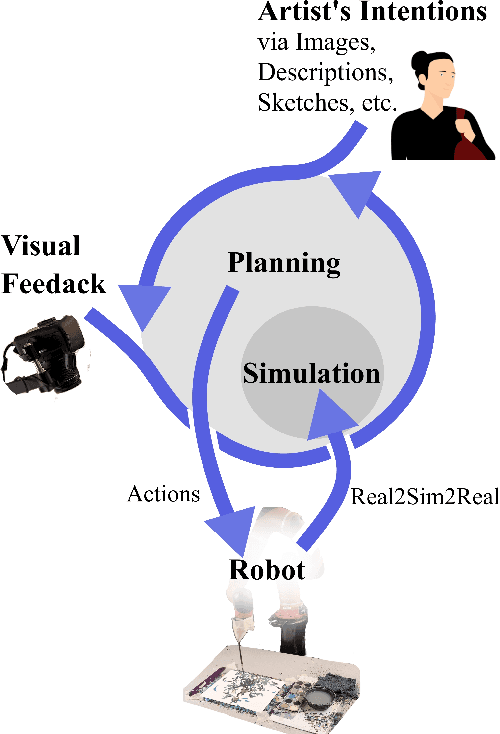
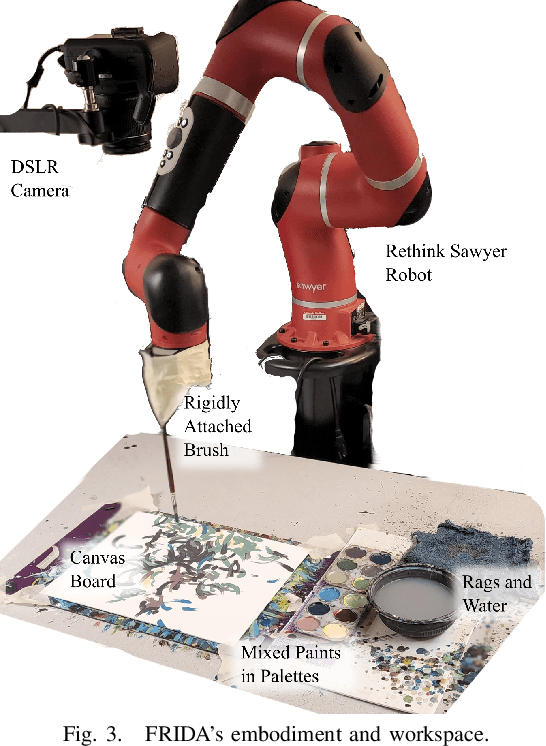
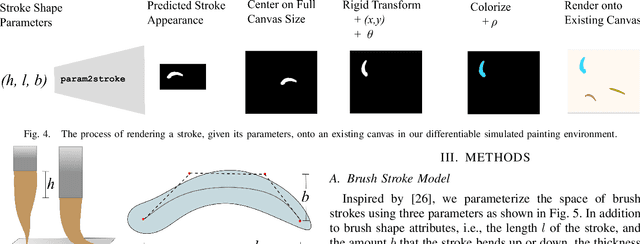
Painting is an artistic process of rendering visual content that achieves the high-level communication goals of an artist that may change dynamically throughout the creative process. In this paper, we present a Framework and Robotics Initiative for Developing Arts (FRIDA) that enables humans to produce paintings on canvases by collaborating with a painter robot using simple inputs such as language descriptions or images. FRIDA introduces several technical innovations for computationally modeling a creative painting process. First, we develop a fully differentiable simulation environment for painting, adopting the idea of real to simulation to real (real2sim2real). We show that our proposed simulated painting environment is higher fidelity to reality than existing simulation environments used for robot painting. Second, to model the evolving dynamics of a creative process, we develop a planning approach that can continuously optimize the painting plan based on the evolving canvas with respect to the high-level goals. In contrast to existing approaches where the content generation process and action planning are performed independently and sequentially, FRIDA adapts to the stochastic nature of using paint and a brush by continually re-planning and re-assessing its semantic goals based on its visual perception of the painting progress. We describe the details on the technical approach as well as the system integration.
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Translation
Feb 24, 2022


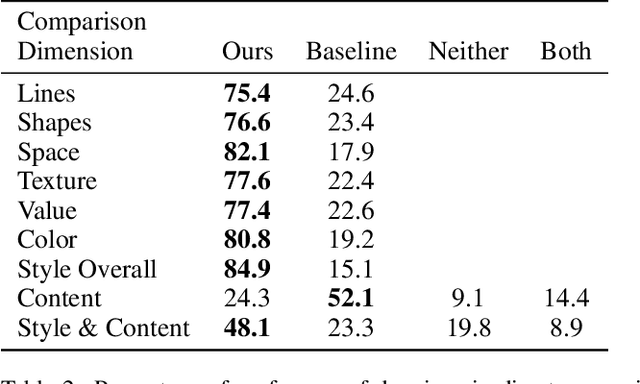
Generating images that fit a given text description using machine learning has improved greatly with the release of technologies such as the CLIP image-text encoder model; however, current methods lack artistic control of the style of image to be generated. We present an approach for generating styled drawings for a given text description where a user can specify a desired drawing style using a sample image. Inspired by a theory in art that style and content are generally inseparable during the creative process, we propose a coupled approach, known here as StyleCLIPDraw, whereby the drawing is generated by optimizing for style and content simultaneously throughout the process as opposed to applying style transfer after creating content in a sequence. Based on human evaluation, the styles of images generated by StyleCLIPDraw are strongly preferred to those by the sequential approach. Although the quality of content generation degrades for certain styles, overall considering both content \textit{and} style, StyleCLIPDraw is found far more preferred, indicating the importance of style, look, and feel of machine generated images to people as well as indicating that style is coupled in the drawing process itself. Our code (https://github.com/pschaldenbrand/StyleCLIPDraw), a demonstration (https://replicate.com/pschaldenbrand/style-clip-draw), and style evaluation data (https://www.kaggle.com/pittsburghskeet/drawings-with-style-evaluation-styleclipdraw) are publicly available.