 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-OrdinalFormer: Vision Language Guided Ordinal Transformers for Interpretable Knee Osteoarthritis Grading
Dec 31, 2025Knee osteoarthritis (KOA) is a leading cause of disability worldwide, and accurate severity assessment using the Kellgren Lawrence (KL) grading system is critical for clinical decision making. However, radiographic distinctions between early disease stages, particularly KL1 and KL2, are subtle and frequently lead to inter-observer variability among radiologists. To address these challenges, we propose VLOrdinalFormer, a vision language guided ordinal learning framework for fully automated KOA grading from knee radiographs. The proposed method combines a ViT L16 backbone with CORAL based ordinal regression and a Contrastive Language Image Pretraining (CLIP) driven semantic alignment module, allowing the model to incorporate clinically meaningful textual concepts related to joint space narrowing, osteophyte formation, and subchondral sclerosis. To improve robustness and mitigate overfitting, we employ stratified five fold cross validation, class aware re weighting to emphasize challenging intermediate grades, and test time augmentation with global threshold optimization. Experiments conducted on the publicly available OAI kneeKL224 dataset demonstrate that VLOrdinalFormer achieves state of the art performance, outperforming CNN and ViT baselines in terms of macro F1 score and overall accuracy. Notably, the proposed framework yields substantial performance gains for KL1 and KL2 without compromising classification accuracy for mild or severe cases. In addition, interpretability analyses using Grad CAM and CLIP similarity maps confirm that the model consistently attends to clinically relevant anatomical regions. These results highlight the potential of vision language aligned ordinal transformers as reliable and interpretable tools for KOA grading and disease progression assessment in routine radiological practice.
Unified Review and Benchmark of Deep Segmentation Architectures for Cardiac Ultrasound on CAMUS
Dec 27, 2025Several review papers summarize cardiac imaging and DL advances, few works connect this overview to a unified and reproducible experimental benchmark. In this study, we combine a focused review of cardiac ultrasound segmentation literature with a controlled comparison of three influential architectures, U-Net, Attention U-Net, and TransUNet, on the Cardiac Acquisitions for Multi-Structure Ultrasound Segmentation (CAMUS) echocardiography dataset. Our benchmark spans multiple preprocessing routes, including native NIfTI volumes, 16-bit PNG exports, GPT-assisted polygon-based pseudo-labels, and self-supervised pretraining (SSL) on thousands of unlabeled cine frames. Using identical training splits, losses, and evaluation criteria, a plain U-Net achieved a 94% mean Dice when trained directly on NIfTI data (preserving native dynamic range), while the PNG-16-bit workflow reached 91% under similar conditions. Attention U-Net provided modest improvements on small or low-contrast regions, reducing boundary leakage, whereas TransUNet demonstrated the strongest generalization on challenging frames due to its ability to model global spatial context, particularly when initialized with SSL. Pseudo-labeling expanded the training set and improved robustness after confidence filtering. Overall, our contributions are threefold: a harmonized, apples-to-apples benchmark of U-Net, Attention U-Net, and TransUNet under standardized CAMUS preprocessing and evaluation; practical guidance on maintaining intensity fidelity, resolution consistency, and alignment when preparing ultrasound data; and an outlook on scalable self-supervision and emerging multimodal GPT-based annotation pipelines for rapid labeling, quality assurance, and targeted dataset curation.
Hybrid Ensemble Approaches: Optimal Deep Feature Fusion and Hyperparameter-Tuned Classifier Ensembling for Enhanced Brain Tumor Classification
Jul 16, 2025Magnetic Resonance Imaging (MRI) is widely recognized as the most reliable tool for detecting tumors due to its capability to produce detailed images that reveal their presence. However, the accuracy of diagnosis can be compromised when human specialists evaluate these images. Factors such as fatigue, limited expertise, and insufficient image detail can lead to errors. For example, small tumors might go unnoticed, or overlap with healthy brain regions could result in misidentification. To address these challenges and enhance diagnostic precision, this study proposes a novel double ensembling framework, consisting of ensembled pre-trained deep learning (DL) models for feature extraction and ensembled fine-tuned hyperparameter machine learning (ML) models to efficiently classify brain tumors. Specifically, our method includes extensive preprocessing and augmentation, transfer learning concepts by utilizing various pre-trained deep convolutional neural networks and vision transformer networks to extract deep features from brain MRI, and fine-tune hyperparameters of ML classifiers. Our experiments utilized three different publicly available Kaggle MRI brain tumor datasets to evaluate the pre-trained DL feature extractor models, ML classifiers, and the effectiveness of an ensemble of deep features along with an ensemble of ML classifiers for brain tumor classification. Our results indicate that the proposed feature fusion and classifier fusion improve upon the state of the art, with hyperparameter fine-tuning providing a significant enhancement over the ensemble method. Additionally, we present an ablation study to illustrate how each component contributes to accurate brain tumor classification.
Hierarchical Deep Feature Fusion and Ensemble Learning for Enhanced Brain Tumor MRI Classification
Jun 14, 2025Accurate brain tumor classification is crucial in medical imaging to ensure reliable diagnosis and effective treatment planning. This study introduces a novel double ensembling framework that synergistically combines pre-trained deep learning (DL) models for feature extraction with optimized machine learning (ML) classifiers for robust classification. The framework incorporates comprehensive preprocessing and data augmentation of brain magnetic resonance images (MRI), followed by deep feature extraction using transfer learning with pre-trained Vision Transformer (ViT) networks. The novelty lies in the dual-level ensembling strategy: feature-level ensembling, which integrates deep features from the top-performing ViT models, and classifier-level ensembling, which aggregates predictions from hyperparameter-optimized ML classifiers. Experiments on two public Kaggle MRI brain tumor datasets demonstrate that this approach significantly surpasses state-of-the-art methods, underscoring the importance of feature and classifier fusion. The proposed methodology also highlights the critical roles of hyperparameter optimization (HPO) and advanced preprocessing techniques in improving diagnostic accuracy and reliability, advancing the integration of DL and ML for clinically relevant medical image analysis.
Culture-TRIP: Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinment
Feb 24, 2025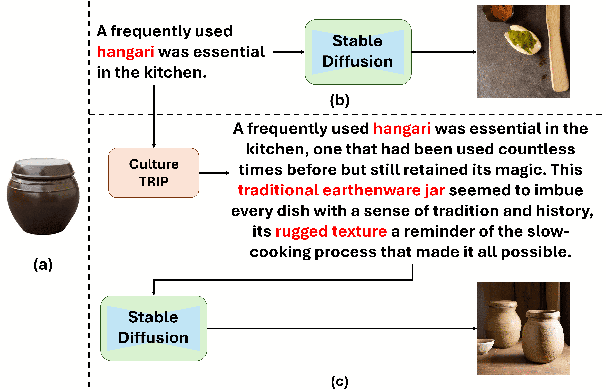

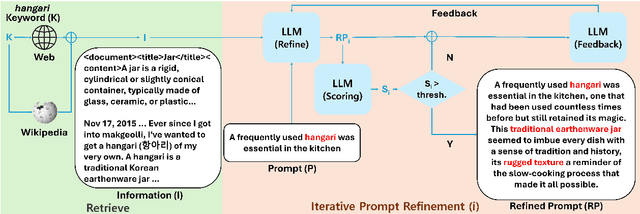
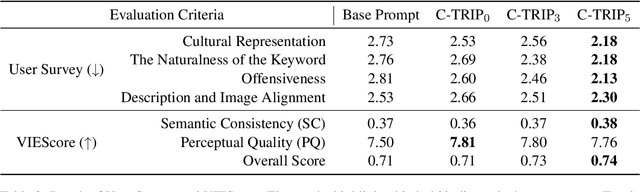
Text-to-Image models, including Stable Diffusion, have significantly improved in generating images that are highly semantically aligned with the given prompts. However, existing models may fail to produce appropriate images for the cultural concepts or objects that are not well known or underrepresented in western cultures, such as `hangari' (Korean utensil). In this paper, we propose a novel approach, Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinement (Culture-TRIP), which refines the prompt in order to improve the alignment of the image with such culture nouns in text-to-image models. Our approach (1) retrieves cultural contexts and visual details related to the culture nouns in the prompt and (2) iteratively refines and evaluates the prompt based on a set of cultural criteria and large language models. The refinement process utilizes the information retrieved from Wikipedia and the Web. Our user survey, conducted with 66 participants from eight different countries demonstrates that our proposed approach enhances the alignment between the images and the prompts. In particular, C-TRIP demonstrates improved alignment between the generated images and underrepresented culture nouns. Resource can be found at https://shane3606.github.io/Culture-TRIP.
DAM-Seg: Anatomically accurate cardiac segmentation using Dense Associative Networks
Feb 21, 2025Deep learning-based cardiac segmentation has seen significant advancements over the years. Many studies have tackled the challenge of anatomically incorrect segmentation predictions by introducing auxiliary modules. These modules either post-process segmentation outputs or enforce consistency between specific points to ensure anatomical correctness. However, such approaches often increase network complexity, require separate training for these modules, and may lack robustness in scenarios with poor visibility. To address these limitations, we propose a novel transformer-based architecture that leverages dense associative networks to learn and retain specific patterns inherent to cardiac inputs. Unlike traditional methods, our approach restricts the network to memorize a limited set of patterns. During forward propagation, a weighted sum of these patterns is used to enforce anatomical correctness in the output. Since these patterns are input-independent, the model demonstrates enhanced robustness, even in cases with poor visibility. The proposed pipeline was evaluated on two publicly available datasets, CAMUS and CardiacNet. Experimental results indicate that our model consistently outperforms baseline approaches across all metrics, highlighting its effectiveness and reliability for cardiac segmentation tasks.
Collaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics
Jan 13, 2025

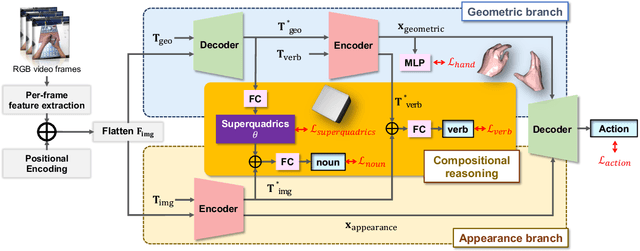

With the availability of egocentric 3D hand-object interaction datasets, there is increasing interest in developing unified models for hand-object pose estimation and action recognition. However, existing methods still struggle to recognise seen actions on unseen objects due to the limitations in representing object shape and movement using 3D bounding boxes. Additionally, the reliance on object templates at test time limits their generalisability to unseen objects. To address these challenges, we propose to leverage superquadrics as an alternative 3D object representation to bounding boxes and demonstrate their effectiveness on both template-free object reconstruction and action recognition tasks. Moreover, as we find that pure appearance-based methods can outperform the unified methods, the potential benefits from 3D geometric information remain unclear. Therefore, we study the compositionality of actions by considering a more challenging task where the training combinations of verbs and nouns do not overlap with the testing split. We extend H2O and FPHA datasets with compositional splits and design a novel collaborative learning framework that can explicitly reason about the geometric relations between hands and the manipulated object. Through extensive quantitative and qualitative evaluations, we demonstrate significant improvements over the state-of-the-arts in (compositional) action recognition.
Evaluating Consistencies in LLM responses through a Semantic Clustering of Question Answering
Oct 20, 2024In the realm of Large Language Model (LLM) functionalities, providing reliable information is paramount, yet reports suggest that LLM outputs lack consistency. This inconsistency, often at-tributed to randomness in token sampling, under-mines user trust as it leads to varying responses even for identical queries. In this paper, we present a new approach for evaluating semantic consistencies of LLM including comparison of alternative tech-niques. Our approach evaluates whether LLM re-sponses are semantically congruent for a given question, recognizing that as syntactically different sentences may convey the same meaning. Here-tofore, To enhance LLM consistency, two main approaches have been explored: Leverage external knowledge as context like the RAG pattern or use Zero-shot-CoT to improve performance of LLM itself. We apply our evaluation approach to these techniques, and demonstrate to compare the im-pact of these methods on LLM response con-sistency across different domains of question an-swering tasks. Using the TruthfulQA dataset to assess LLM responses, the study induces N re-sponses per question from the LLM and clusters semantically equivalent sentences to measure semantic consistency across 37 categories. Through this, it quantitatively analyzes the effectiveness of the aforementioned methods in improving LLM performance before and after their adoption.
Advancing Medical Image Segmentation: Morphology-Driven Learning with Diffusion Transformer
Aug 01, 2024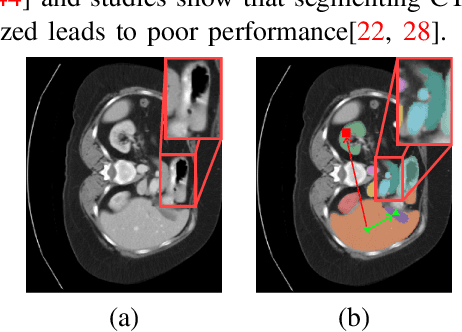

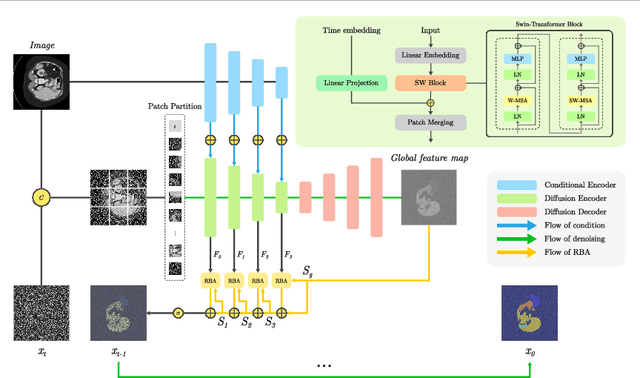
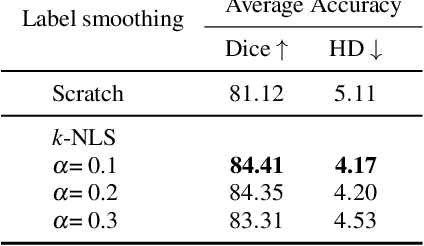
Understanding the morphological structure of medical images and precisely segmenting the region of interest or abnormality is an important task that can assist in diagnosis. However, the unique properties of medical imaging make clear segmentation difficult, and the high cost and time-consuming task of labeling leads to a coarse-grained representation of ground truth. Facing with these problems, we propose a novel Diffusion Transformer Segmentation (DTS) model for robust segmentation in the presence of noise. We propose an alternative to the dominant Denoising U-Net encoder through experiments applying a transformer architecture, which captures global dependency through self-attention. Additionally, we propose k-neighbor label smoothing, reverse boundary attention, and self-supervised learning with morphology-driven learning to improve the ability to identify complex structures. Our model, which analyzes the morphological representation of images, shows better results than the previous models in various medical imaging modalities, including CT, MRI, and lesion images.
Biomarker based Cancer Classification using an Ensemble with Pre-trained Models
Jun 14, 2024Certain cancer types, namely pancreatic cancer is difficult to detect at an early stage; sparking the importance of discovering the causal relationship between biomarkers and cancer to identify cancer efficiently. By allowing for the detection and monitoring of specific biomarkers through a non-invasive method, liquid biopsies enhance the precision and efficacy of medical interventions, advocating the move towards personalized healthcare. Several machine learning algorithms such as Random Forest, SVM are utilized for classification, yet causing inefficiency due to the need for conducting hyperparameter tuning. We leverage a meta-trained Hyperfast model for classifying cancer, accomplishing the highest AUC of 0.9929 and simultaneously achieving robustness especially on highly imbalanced datasets compared to other ML algorithms in several binary classification tasks (e.g. breast invasive carcinoma; BRCA vs. non-BRCA). We also propose a novel ensemble model combining pre-trained Hyperfast model, XGBoost, and LightGBM for multi-class classification tasks, achieving an incremental increase in accuracy (0.9464) while merely using 500 PCA features; distinguishable from previous studies where they used more than 2,000 features for similar results.