 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulture-TRIP: Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinment
Feb 24, 2025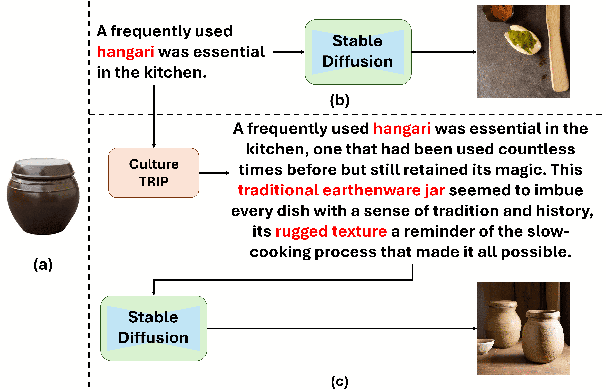

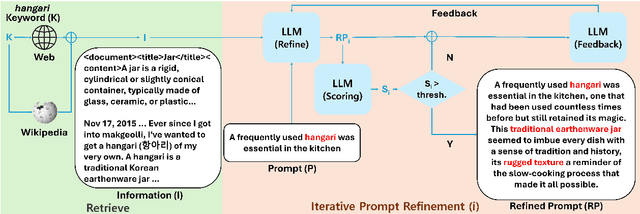
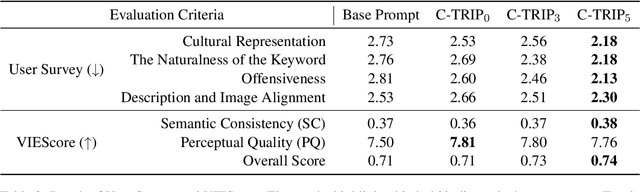
Text-to-Image models, including Stable Diffusion, have significantly improved in generating images that are highly semantically aligned with the given prompts. However, existing models may fail to produce appropriate images for the cultural concepts or objects that are not well known or underrepresented in western cultures, such as `hangari' (Korean utensil). In this paper, we propose a novel approach, Culturally-Aware Text-to-Image Generation with Iterative Prompt Refinement (Culture-TRIP), which refines the prompt in order to improve the alignment of the image with such culture nouns in text-to-image models. Our approach (1) retrieves cultural contexts and visual details related to the culture nouns in the prompt and (2) iteratively refines and evaluates the prompt based on a set of cultural criteria and large language models. The refinement process utilizes the information retrieved from Wikipedia and the Web. Our user survey, conducted with 66 participants from eight different countries demonstrates that our proposed approach enhances the alignment between the images and the prompts. In particular, C-TRIP demonstrates improved alignment between the generated images and underrepresented culture nouns. Resource can be found at https://shane3606.github.io/Culture-TRIP.
Improving LLM Classification of Logical Errors by Integrating Error Relationship into Prompts
May 01, 2024



LLMs trained in the understanding of programming syntax are now providing effective assistance to developers and are being used in programming education such as in generation of coding problem examples or providing code explanations. A key aspect of programming education is understanding and dealing with error message. However, 'logical errors' in which the program operates against the programmer's intentions do not receive error messages from the compiler. In this study, building on existing research on programming errors, we first define the types of logical errors that can occur in programming in general. Based on the definition, we propose an effective approach for detecting logical errors with LLMs that makes use of relations among error types in the Chain-of-Thought and Tree-of-Thought prompts. The experimental results indicate that when such logical error descriptions in the prompt are used, the average classifition performance is about 21% higher than the ones without them. We also conducted an experiment for exploiting the relations among errors in generating a new logical error dataset using LLMs. As there is very limited dataset for logical errors such benchmark dataset can be very useful for various programming related applications. We expect that our work can assist novice programmers in identifying the causes of code errors and correct them more effectively.